背景介绍
过去几年我主要从事大模型 Agent 的开发工作,在这个过程中遇到的一个明显痛点是:如何将一个大模型 Agent 产品从最初的想法迭代到能够稳定上线。尽管团队内部已经沉淀出一套相对可靠的方法论,但整个流程依然相当漫长,其中的核心环节大都消耗在对现有 Agent 的评测、异常数据分析和异常归因上。尤其是异常数据归因分析格外耗时,依赖人力而且需要比较多的行业经验进行判定。
因此我一直在思考:是否存在一种更可靠的方法,可以显著缩短这个过程?最近一段时间的尝试给了我一个明确的答案:完整的 Agent 调优流程是可以被进一步标准化、并拆解为一组明确步骤的。既然能够拆解为确定性的步骤,那么自然就可以将其 skill 化。我在最近一个项目中进行了实践,实际效果相当不错,在尝试的过程中下甚至超出了我原本的预期。这让我隐约感觉到,AI 确实已经进化到了一个新的阶段,我们应该在更多环节中尝试 AI First 的开发实践:把 AI 当作专家,尽可能把所有合适的场景都交给 AI 去处理。
本文是对这次尝试的一份实践记录,同时也会介绍由此沉淀出的开源项目 agent-tune-kit。
尝试过程
项目背景
最近我在一个面向全球化服务分发的项目中负责代码相关的产品开发。该项目要解决的核心问题是:在产品主线持续迭代的同时,各个国家的定制化版本在不定期进行主线迭代升级合并时会出现大量冲突,此时需要大量的行业专家进行冲突处理,因此希望借助 AI 来处理定制化版本升级合并中的冲突问题。
在过去几个月里,团队基于过往专家经验,设计了一套相当复杂的升级合并策略,并投入了大量精力进行实现,但实际依旧存在不少的问题。在这种背景下,我尝试抛开所有既有的专家经验和先验判断,从一个最朴素的策略出发,借助 Codex,在数据集的指引下持续迭代调优,在很短的时间内就迭代出一套相对稳定可靠的技术方案。下面是迭代过程简要描述:
基础版本 v1
第一个版本的实现极其简单粗糙,几乎没有任何方案设计。我直接让大模型写一个 Prompt,用于将主线版本合并到定制化版本中,整个过程没有给出任何额外的指导。Codex 给出的初始版本相当粗糙,对应的提示词甚至与实际是与专家经验是违背的。提示词如下所示:
# Role
你是一名资深 JavaScript 工程师, 负责把两份同源 JavaScript 代码合并成一份.
# Inputs
- source: 来自上游分支的 JavaScript 代码 (含新功能或修复).
- target: 来自当前分支的 JavaScript 代码 (含用户本地改动).
# Objective
基于 source 与 target 的差异, 产出一份合并后的完整 JavaScript 代码, 同时:
1. 保留双方各自的新增逻辑, 不要丢失任一方的代码片段.
2. 当两侧对同一处都做了修改且语义冲突时, 优先采纳 source 的实现.
3. 不要改写未变化的代码, 不要重新格式化, 不要添加无关注释.
4. 保留原有的注释 / 空行 / 缩进风格.
5. 不要输出任何 Markdown 代码块标记 (```), 也不要输出解释文字, 只输出最终合并后的 JavaScript 源代码.
# source
{source_js}
# target
{target_js}
# Output
直接输出合并后的完整 JavaScript 代码, 不要包裹在代码块中.
基于这份提示词,我借助 Codex 快速搭建了一个批量测试脚本,跑出测试结果后将原始数据与 Agent 合并在一起,保存为最终的输出文件。接着同样借助 Codex 实现了一个评测脚本,对输出结果进行快速判定。第一个版本的评分采用的是严格的字符串完全一致比对。
实际测试发现,准确率仅有 40% 左右。于是让 Codex 对结果进行了一轮分析,结论是评分方式本身存在问题——在当前场景下,严格的字符串匹配并不合理:有些输出与标准答案在语义上完全一致,仅在空行等无意义的差异上不一致,却被判定为错误。基于这一发现,我让 Codex 调整了评分规则,准确率随之上升到 60% 左右。
调优版本 v2
在 v1 的基础上,我让 Codex 对异常数据进行了归因分析。这一轮分析给出了一个更贴近业务的判断:原始策略对冲突处理的方向不够准确,实际很多 case 中标准答案并不偏向 source,反而更倾向于保留 target 的实现。同时,Codex 敏锐地注意到原始数据中还存在一列 base 数据——这一列实际上是主线版本与定制化版本的公共基线,对最终合并结果的判定有非常重要的价值,但在 v1 中被完全忽略了。
基于这一发现,Codex 重新设计了方案,将 base、source、target 三列数据同时作为输入,并结合数据中观察到的规律,撰写出一份新的提示词:
# Role
你是一名资深 JavaScript 工程师, 负责基于三方版本把同源 JavaScript 代码合并成一份.
# Inputs
- base: 两个分支共同的原始 JavaScript 代码.
- source: 来自上游分支的 JavaScript 代码.
- target: 来自当前分支的 JavaScript 代码.
# Objective
基于 base/source/target 的差异, 产出一份合并后的完整 JavaScript 代码, 同时:
1. 先比较 base -> source 与 base -> target, 只合并真实发生变化的代码.
2. source 独有且与 target 不冲突的变更要保留; target 独有且与 source 不冲突的变更也要保留.
3. source 和 target 对同一处都做了修改且无法安全组合时, 优先保留 target 当前分支实现.
只补入 source 中独立且不改变 target 语义的改动.
4. 如果 source 相比 base 删除了注释、console 日志或示例代码, 但 target 保留了它们,
不要仅因为 source 删除就移除 target 中的内容.
5. 不要把注释掉的示例代码改成可执行代码, 也不要把可执行代码改成注释.
除非这种改变能从 base -> source 或 base -> target 的真实变更中明确看出.
6. 不要推断、补写 source/target/base 中都不存在的新业务逻辑.
7. 不要改写未变化的代码, 不要重新格式化, 不要添加无关注释.
8. 保留原有的注释 / 空行 / 缩进风格.
当 source 与 target 仅格式不同而语义一致时, 以 target 的文本为准.
9. 不要输出任何 Markdown 代码块标记 (```), 也不要输出解释文字, 只输出最终合并后的 JavaScript 源代码.
# base
{base_js}
# source
{source_js}
# target
{target_js}
# Output
直接输出合并后的完整 JavaScript 代码, 不要包裹在代码块中.
在这一版本下,准确率提升到了 87%。同时,Codex 在异常数据分析中又发现,当前的评分标准仍然不够合理:部分 case 中输出与标准答案的差异仅来自空格缩进,从语义上应被判定为正确。调整评分标准后,实际的准确率进一步提升到了 92%。
调优版本 v3
继续对剩余的异常 case 进行分析,Codex 发现数据中存在一个比较明显的规律:在忽略空行和缩进之后,base 在部分情况下会与 source 或 target 中的某一方完全一致。当两两一致时,最终答案通常与发生了修改的另一方保持一致。基于这一规律,Codex 给出了一个明确的短路策略——当 base 与 source 一致时,直接返回 target;当 base 与 target 一致时,直接返回 source。可以简单理解为:谁做了修改,就以谁为准。这部分完全符合既往的专家经验,但是专家经验中没有提到任何忽略空行与语义的等价策略。简化后的代码如下所示:
if base_js is not None and _equivalent_ignoring_blank_lines_and_indent(base_js, source_js):
merged = _match_trailing_newline(target_js, target_js)
return SimpleJsMergeResult(
merged_js=merged,
model=effective_model,
elapsed_seconds=0.0,
prompt=prompt,
raw_output=target_js,
)
if base_js is not None and _equivalent_ignoring_blank_lines_and_indent(base_js, target_js):
merged = _match_trailing_newline(source_js, source_js)
return SimpleJsMergeResult(
merged_js=merged,
model=effective_model,
elapsed_seconds=0.0,
prompt=prompt,
raw_output=source_js,
)
加入短路策略后,准确率提升到 93%。虽然准确率的提升幅度相对有限,但由于大量数据都走到了短路路径,整体的处理效率相比之前版本有了明显提升。
迭代调优 v4
在对剩余 7% 的异常 case 进行分析时,Codex 给出了一个相当意外的结论:之所以这部分 case 无法被正确处理,主要原因并非 Agent 本身的问题,而是数据集本身存在瑕疵——标准答案中包含了一些无法从 base、source、target 中合理推导出来的内容,本质上是最终人工进行了一些额外的后置修改,已经超出了当前业务的需求范围。因此 Codex 建议将这部分数据从数据集中剔除。实际中的分析报告片段如下所示:
7 条 mismatch:
| row | asset_name | 结论 |
| ---: | --- | --- |
| 38 | `checkBKPermission` | `ground_truth` 有额外逻辑,输入三方都没有 |
| 52 | `initBKSystemConfig` | `ground_truth` 有额外配置项,输入三方都没有 |
| 60 | `queryBKCustomerSystemConfigs` | `ground_truth` 有额外 key 与参数变化,输入三方都没有 |
| 72 | `queryBKPermissionSPI` | `ground_truth` 有完整 RBAC 查询逻辑,输入三方都没有 |
| 85 | `queryBKStoreOrderBriefList` | `ground_truth` 多了 `searchContent/timeSortRule`,输入三方都没有 |
| 87 | `queryBKStoreOrderList` | `ground_truth` 多了 `searchContent/timeSortRule`,输入三方都没有 |
| 89 | `queryBKStoreResourceOrder` | `ground_truth` 与 target 的字段访问方式冲突,且包含输入中不存在的 log |
## 核心结论
### Rank 1 — 主要原因:`ground_truth` 无法由 `base/source/target` 推导出来
**Confidence: High**
我对相关数据进行了人工复核,确认 Codex 给出的结论是成立的——这部分 case 的标准答案确实无法从输入中正确推导出来,在当前业务背景下不应作为参考答案。剔除这部分数据后,当前版本的准确率甚至接近 100%。这个结果远超出了我原本的预期:Codex 最终找到的是一条执行效率极高、准确率惊人的解决方案,远远超出了我最初对这个尝试的预期。甚至帮助找到了完全意料之外的数据集问题。
Agent-Tune-Kit 简介
基于本次迭代的实际经验,我对整个调优过程进行了必要的抽象,并将其沉淀为一个可持续迭代的 Codex 插件 Agent-Tune-Kit。整体架构如下图所示:
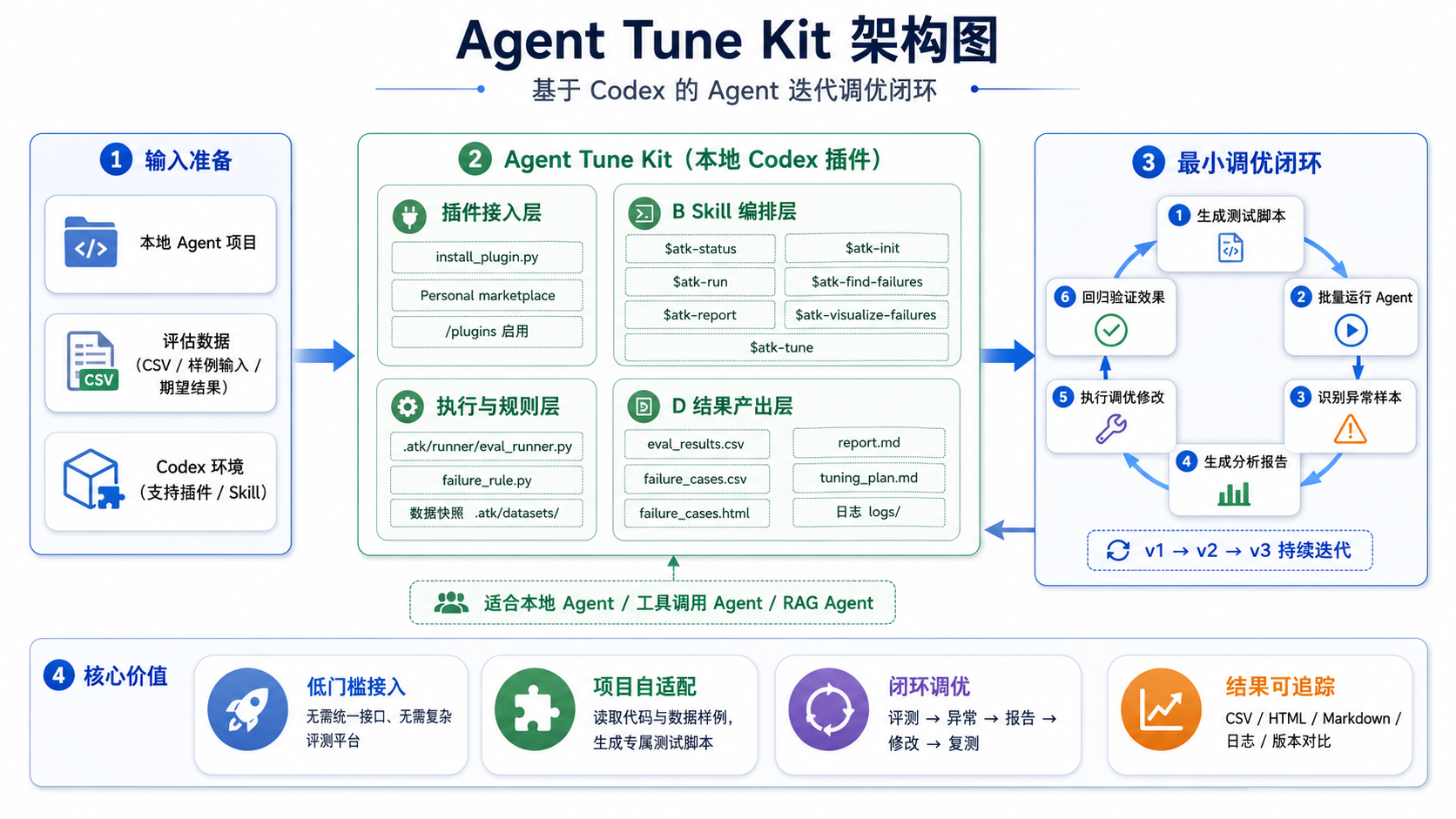
我将整个项目定位为:基于 Codex 的、无需预设指标的 AI First Agent 调优框架。其核心思路是尽可能利用 AI 自身的分析与推理能力,在不预设方向的前提下,由 AI 结合本地代码自动完成问题定位、归因分析与调优实施,从而形成完整的闭环,将 Agent 持续迭代优化,直到达到上线标准。核心步骤如下:
- atk-init:用于生成批量测试脚本。你只需告诉插件 Agent 的位置以及评测数据集的位置,插件会自动完成批量测试脚本的生成。
- atk-run:执行批量测试并生成结果。
- atk-find-failures:借助 AI 的推理能力,从批量测试结果中识别并过滤出异常数据,方便后续分析。如果你已有明确的异常判定标准,也可以通过命令 atk-init-failure-rule 直接告诉 AI,它会据此生成相应的过滤脚本并执行。
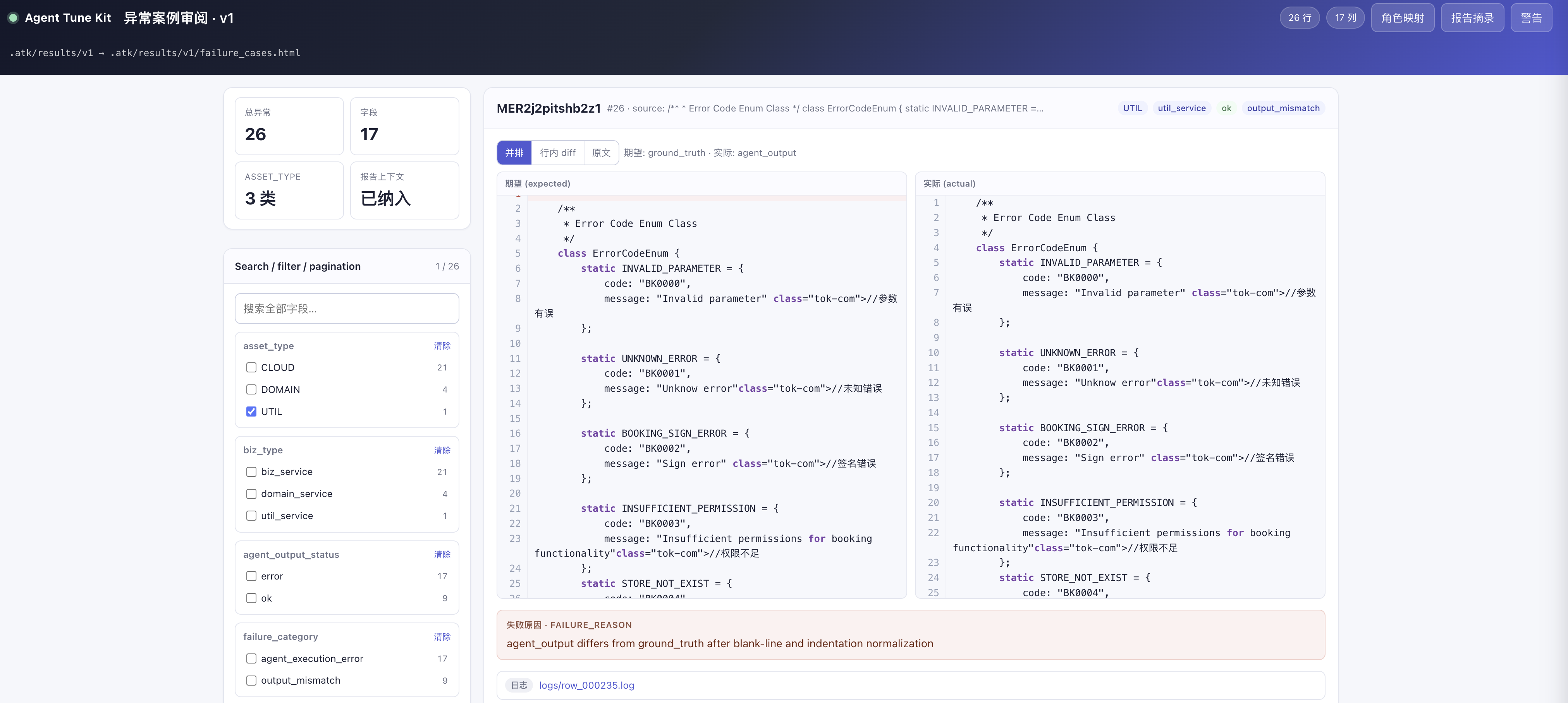
- atk-visualize-failures:将筛选出的异常数据生成本地可视化的 HTML 浏览页面,支持搜索、筛选与人工复核。在异常 case 需要人工介入确认的场景下,这一步可以显著降低复核成本,也方便把异常数据直接分享给团队中的业务专家进行交叉确认。
- atk-report:对异常数据进行分析推理,定位异常原因并给出调优建议。
- atk-tune:根据 atk-report 给出的方向自动执行 Agent 调优,直接修改你的代码。
完成一轮调优后,重新执行 atk-run 进行回归测试,此时 atk-report 会自动对比上一轮的调优计划,针对上一轮识别出的每个问题给出明确结论:已解决 / 部分解决 / 未解决 / 无法判断,并同时识别本轮新引入的回归问题。这样调优过程不再是”跑一轮看一眼准确率”的黑盒,每一轮的改动是否真正解决了目标问题、是否带来了新的副作用,都会被显式追踪下来,让整个迭代过程可观测、可回溯,避免在长链路调优中陷入”按下葫芦浮起瓢”的困境。异常数据的分析页面如下所示:
总结
本文是对过去一周探索的一个阶段性总结。在面对 Agent 调优这一长期困扰我的难题时,我最终找到了一条相对简洁的迭代路径。当然,AI 并不能解决所有问题,但对于流程相对固定、重复性较高的任务,完全可以放心地交给 AI;人则应当把精力集中在 AI 无法完成的部分。个人的时间和精力是稀缺资源,我们更应该珍惜自身相较于 AI 的优势能力,把所有能够外包给 AI 的工作都交出去。
在当下的 AI 时代,我们也需要学着与 AI 和解,充分利用其已有能力来放大个人的产出,才能在这一轮 AI 浪潮中持续生长。本项目仍在持续迭代中,难免存在一些问题,欢迎大家积极反馈,我会及时跟进优化。如果对你有所帮助,也欢迎给我一些鼓励。