背景介绍
最近因为工作内容的变化,开始更多关注代码知识库的构建与检索方案,因此集中调研了一些相关实践,包括基于 RAG 的 claude-context,以及基于知识图谱的 Graphify。
在研究 Continue 的过程中,我注意到它已经将早期基于 RAG 的 @Codebase 标记为 deprecated,并把 Agent Mode 下的文件探索、关键词搜索和上下文注入作为更推荐的代码库理解方式。那么,为什么会出现这种转变?在真实项目中,又应该如何做架构选型?
方案比较
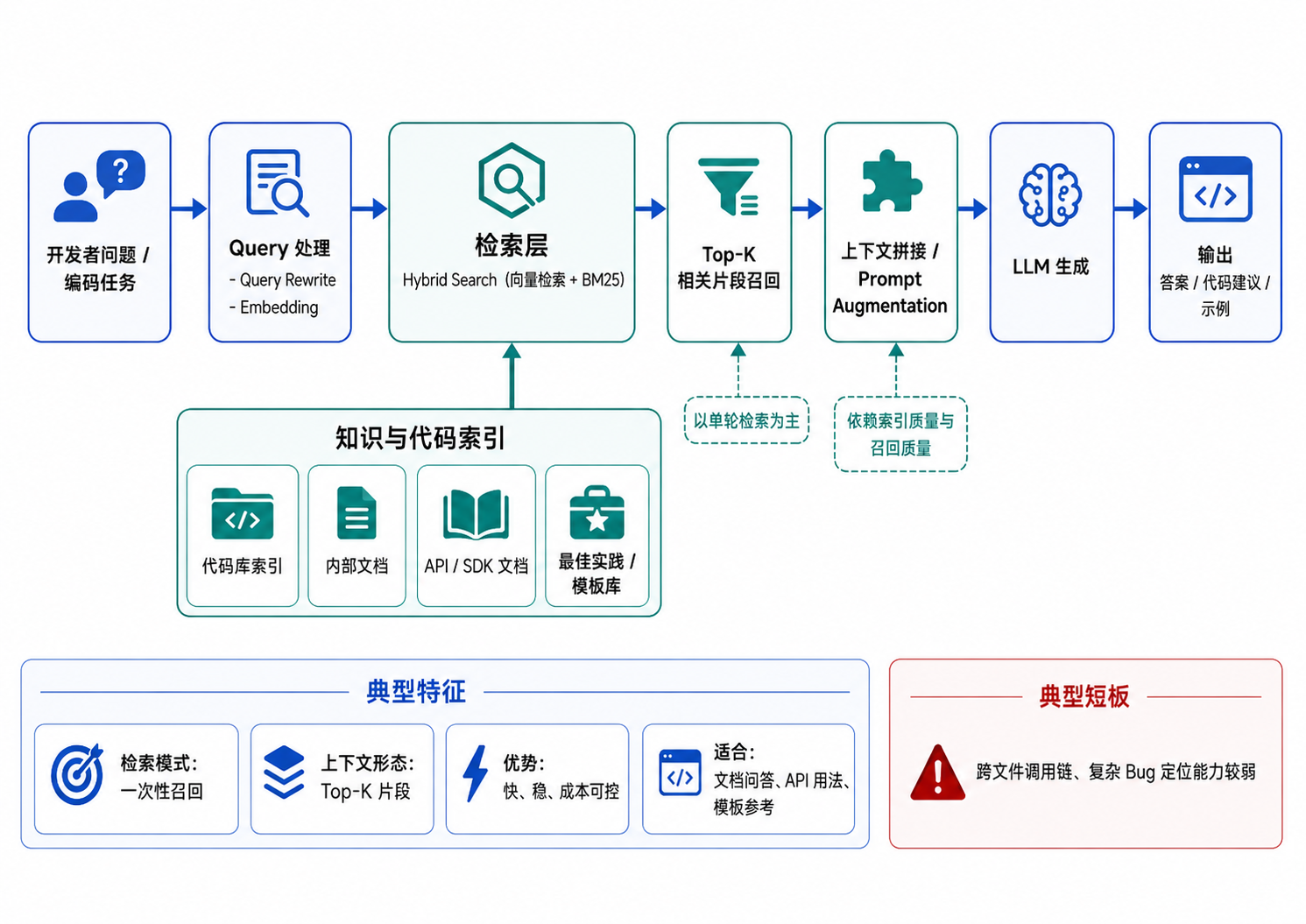
RAG 是一种相对静态的“检索 + 生成”方案。系统在接收到问题后,通常会先从知识库或代码库中检索相关文档、代码片段,再将这些内容拼接进 Prompt,交给大模型生成答案。这种方式实现路径清晰、响应速度较快、推理成本相对可控,适合上下文边界明确、问题意图稳定、不需要跨文件多轮推理的代码问答或报错解释场景。claude-context 就是这类方案中比较典型的开源项目。典型架构图如下所示:
Agentic Search 则是一种动态的“智能体搜索”方案。它将大模型作为决策核心,让模型根据任务目标自主规划、拆解问题,并结合中间结果决定何时搜索、搜索什么、是否继续读取文件或调整查询策略。在编程场景中,它更适合处理需要多步定位、跨文件分析、理解工程目录结构,或者需要在多个线索之间反复对比的复杂开发任务。Claude Code 是这类方案中最有代表性的产品之一。
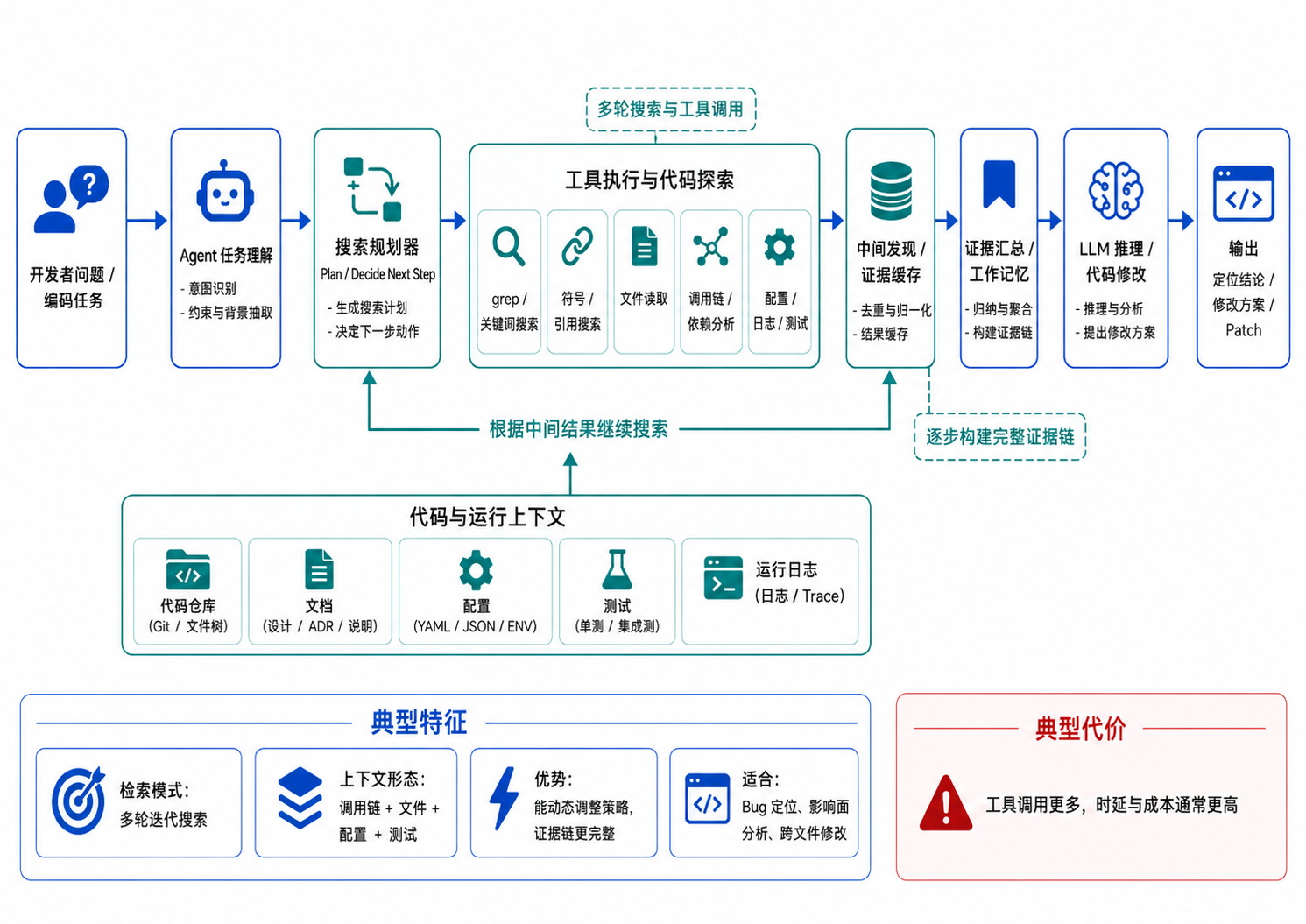
RAG vs Agentic Search
最近的一篇论文 Is Grep All You Need? 对这类检索策略进行了系统比较。它的价值不在于简单得出“Grep 一定优于向量检索”的结论,而是提醒我们:在 Agent 场景下,检索工具本身、工具调用方式、结果返回形式以及 Agent Harness 的设计,都会显著影响最终效果。
论文主要关注 AI 编程与长上下文记忆场景下的信息检索,比较的是向量检索与 Grep 检索。需要注意的是,真实工程中的 RAG 往往不只是单纯的向量相似度检索,还会结合 BM25、关键词检索、重排序、结构化索引等手段;而论文为了控制变量,主要聚焦在向量检索与 Grep 这两类工具能力的对比上。
如果只用一次 Grep 与向量检索做离线对比,结论通常缺乏代表性:Grep 依赖关键词命中,向量检索则具备更强的语义泛化能力。但真实的 Agentic Search 并不是一次性搜索,而是由大模型根据任务不断生成查询、阅读结果、修正假设并继续检索。因此,论文将两类检索方式都放在 Agent 框架下评估,更接近实际开发工具中的使用方式。
在实验设计上,论文验证了两种工具结果返回模式:一种是标准内联模式 Standard (Inline),即直接将检索结果写入当前上下文中供模型回答。这种模式实现简单、反馈直接,但当检索结果较长时,容易占用大量上下文窗口,并引入无关信息干扰。另一种是基于文件的延迟加载模式 Programmatic (File-Based),即先将检索结果写入本地文件,由 Agent 在后续步骤中按需读取。这种方式更适合结果较长、需要分阶段消化信息的场景。
基于 LongMemEval-S 的数据集,评价标准为总体的准确率,测试结果如下所示:
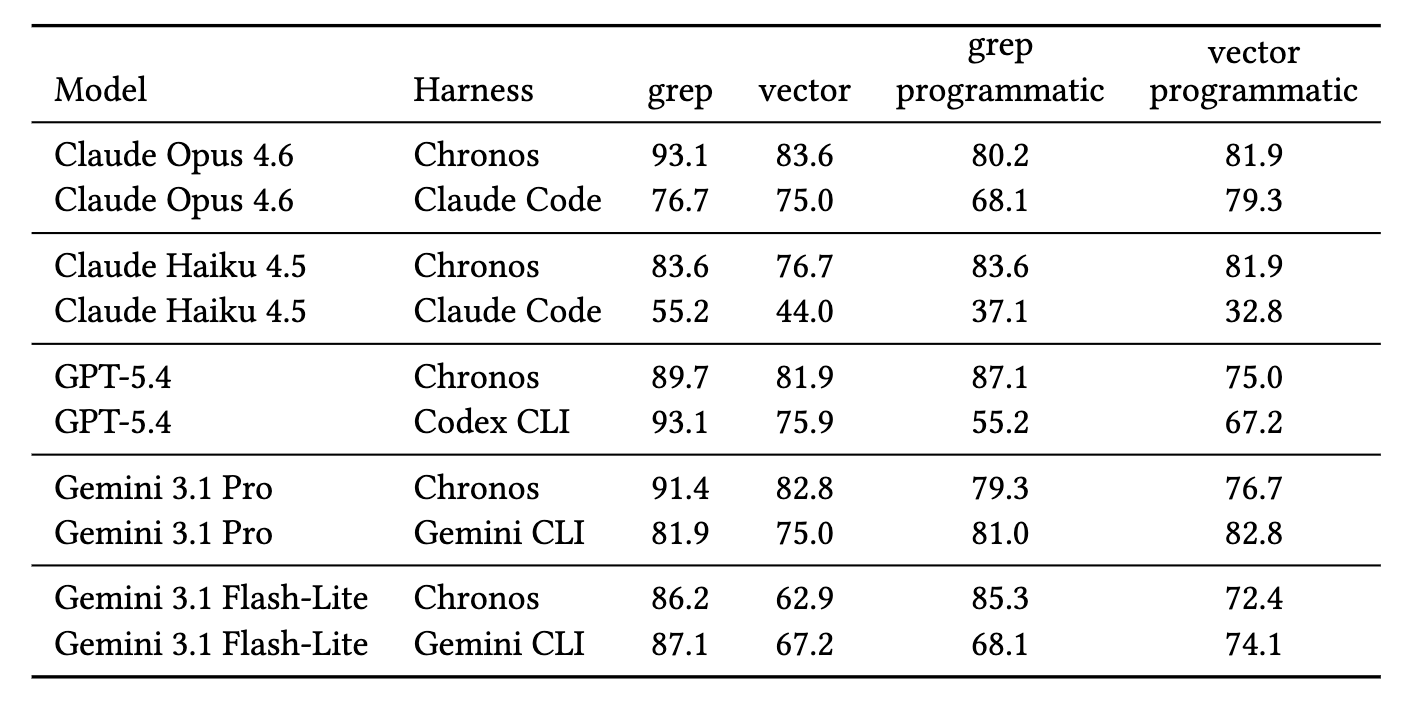
从结果可以看到,在 Chronos、Claude Code、Codex 和 Gemini CLI 等不同 Agent Harness 中,Grep 在多数配置下取得了更高准确率,尤其是在标准内联模式下优势更明显;而在基于文件的延迟加载模式下,向量检索在部分组合中能够追回甚至取得一定优势。这说明检索策略不能脱离工具接口、上下文组织方式和模型行为单独评价。
考虑到会话中的无关信息可能影响检索与回答准确性,论文进一步向上下文中混入其他无关会话,并比较不同干扰强度下的检索准确率。其中,s5 表示混入 5 轮会话,s20 表示混入 20 轮会话,最终结果如下所示:
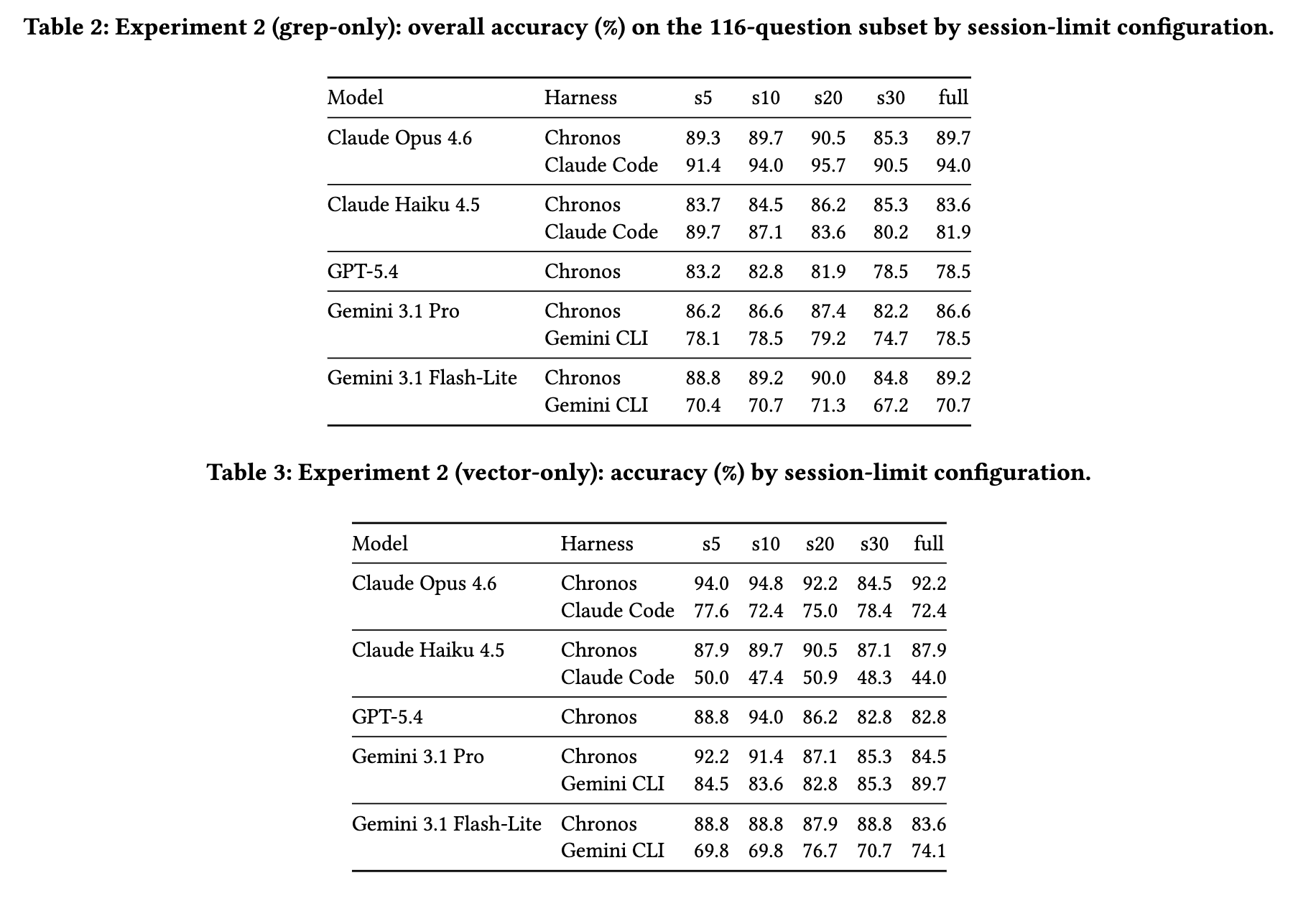
从上面的对比可以看到,随着干扰会话增加,准确率并不是简单地单调下降,而是会受到模型、Harness、工具返回方式等多重因素影响。在 Claude Code 等环境中,Grep 相对于向量检索表现出明显优势;而在 Gemini CLI 的部分设置下,向量检索仍然有更好的表现。这也再次说明,Agentic Search 的效果不是由某一种检索算法单独决定,而是由模型能力、工具接口、上下文管理策略和任务类型共同决定。
总结
综合来看,可以得到几个相对稳健的判断:复杂的 RAG 在代码场景下并不必然带来更好的效果;当 Agent 具备规划、迭代搜索和按需读取文件的能力时,简单的关键词检索反而可能更可靠、更透明,也更容易与开发者已有的工程工具链协同。
此外,代码库是高度动态的知识源。基于索引的 RAG 系统需要处理代码切分、增量更新、向量库同步、检索结果过期、权限隔离和成本控制等问题。如果索引与真实代码之间出现不一致,模型反而可能基于过期上下文生成误导性答案。因此,在没有强语义召回、跨仓库知识沉淀或超大规模私有知识库等明确需求时,基于 Grep、文件读取和 Agent 迭代推理的 Agentic Search,通常是更轻量、更可解释的默认选择。
这也解释了为什么 Continue 会将旧的 @Codebase 路径标记为 deprecated,并在默认体验上转向 Agent Mode 下的代码库探索能力。当然,这并不意味着 RAG 在代码场景中失去价值。对于超大代码库、跨仓库历史知识、文档与代码混合检索,或者需要低延迟重复查询的企业场景,自定义 RAG 仍然有明确价值。更合理的结论是:RAG 不应该成为默认答案,而应该作为 Agentic Search 的补充能力,在确实需要语义召回和长期索引时再引入。