背景介绍
做了几年大模型 Agent,我对一件事的体会越来越深:把一个 Agent 跑起来只是起点,让它从“能用”走到“敢上线”,才是真正消耗时间的地方。
而这中间的成本,大多不花在写 prompt 或调模型上,而是堆在两件又脏又慢的事情上。一是准备一份靠得住的评测数据集和 ground truth;二是面对一大堆执行结果,逐条判断哪里错了、为什么错、这一版改动到底有没有用。后者尤其折磨人——它依赖经验,依赖人盯着结果一行行看,很难规模化,也很难复现判断。
Agent Tune Kit(下文简称 ATK)就是为了把这两件事工程化而做的。它的目标不复杂:先让数据集和 ground truth 稳定下来,再让评测、异常发现、归因、调优和跨版本验证连成一个能反复跑的闭环。前者决定了你的评测依据是否可信,后者决定了每一轮调优是不是真的有效。
Agent 的能力不是一次设计出来的
做 Agent 时一个常见的惯性,是先把策略想透、把 prompt 写漂亮,期望一次实现到位。但这种”先设计后实现”的姿势,背后其实有一个隐含假设:你提前就知道模型在这个场景下能做到什么程度、会在哪里翻车。
而现实是,到今天为止,并没有哪一类业务场景是大模型能保证 100% 解决好的,也没有一套可以套用在所有 Agent 上的标准化设计方案。同一个 prompt、同一份策略,换一类输入、换一个模型版本,表现就可能完全不一样。模型究竟在哪些子问题上稳定靠谱、在哪些边界上会失手,光靠设计阶段的脑补很难判断,只能拿真实样本跑一遍才知道。
所以更合理的做法,是把”设计”压成一个尽量轻的起点,把更多精力放在迭代上:跑一轮、看哪些 case 错了、归因、改一版、再跑一轮,让 Agent 的策略沿着真实失败一点点长出来。
数据集构建:被低估的第一步
真正开始调优之前,最容易被跳过的其实是数据集构建。它要回答一个朴素的问题:怎么把业务知识变成一份能跑、能判断、能复用的评测资产。
很多 Agent 项目调优效率低,根子不在模型,也不在 prompt,而在于手里压根没有一组稳定、能人工校准的评测样本。没有数据集,调优就只能靠临时输入和主观感觉;数据集本身不稳,后面的失败判断、归因和调优方向就会跟着一起漂。
所以在 ATK 里,数据集构建是一条独立链路,而不是某次评测的附属品。典型流程是:
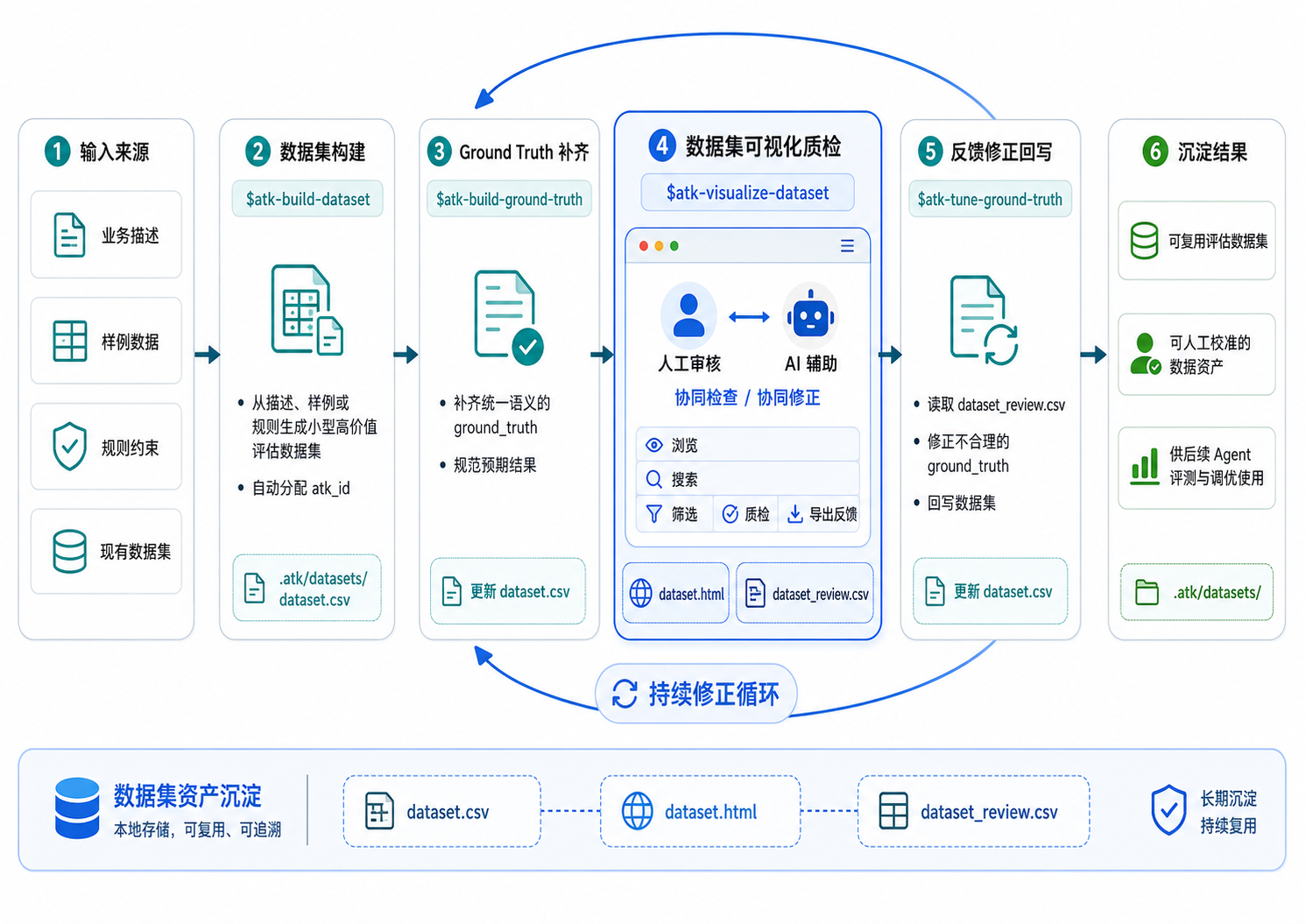
atk-build-dataset 从业务描述、样例、流程规则或验收标准里整理出一份小而精的数据集。它不追求一上来就生成大规模 benchmark,而是优先覆盖主流程、边界情况、模糊输入、拒答场景、格式约束和高风险业务 case。对多数项目来说,几十条高质量样本就足以暴露第一批关键问题。
atk-build-ground-truth 处理一个更隐蔽的问题:预期结果到底该怎么写。有些任务适合精确答案,有些更适合自然语言验收标准。一旦同一个数据集里混用了几种判断口径,后面的失败筛选就会变得很不稳定。所以 ATK 把 ground truth 当成一类需要被明确校准的资产,而不是随手填进某个 expected 字段。
atk-visualize-dataset 把数据集渲染成本地 HTML 页面,方便搜索、筛选和人工复核。这一步看起来不起眼,却很关键——数据集不是只给机器看的。专家在翻样本时常常会发现:某些预期结果不完整,某些 case 根本不该进评测集,某些验收标准压根没说清楚。最终渲染的内容可以方便在本地进行快速查看
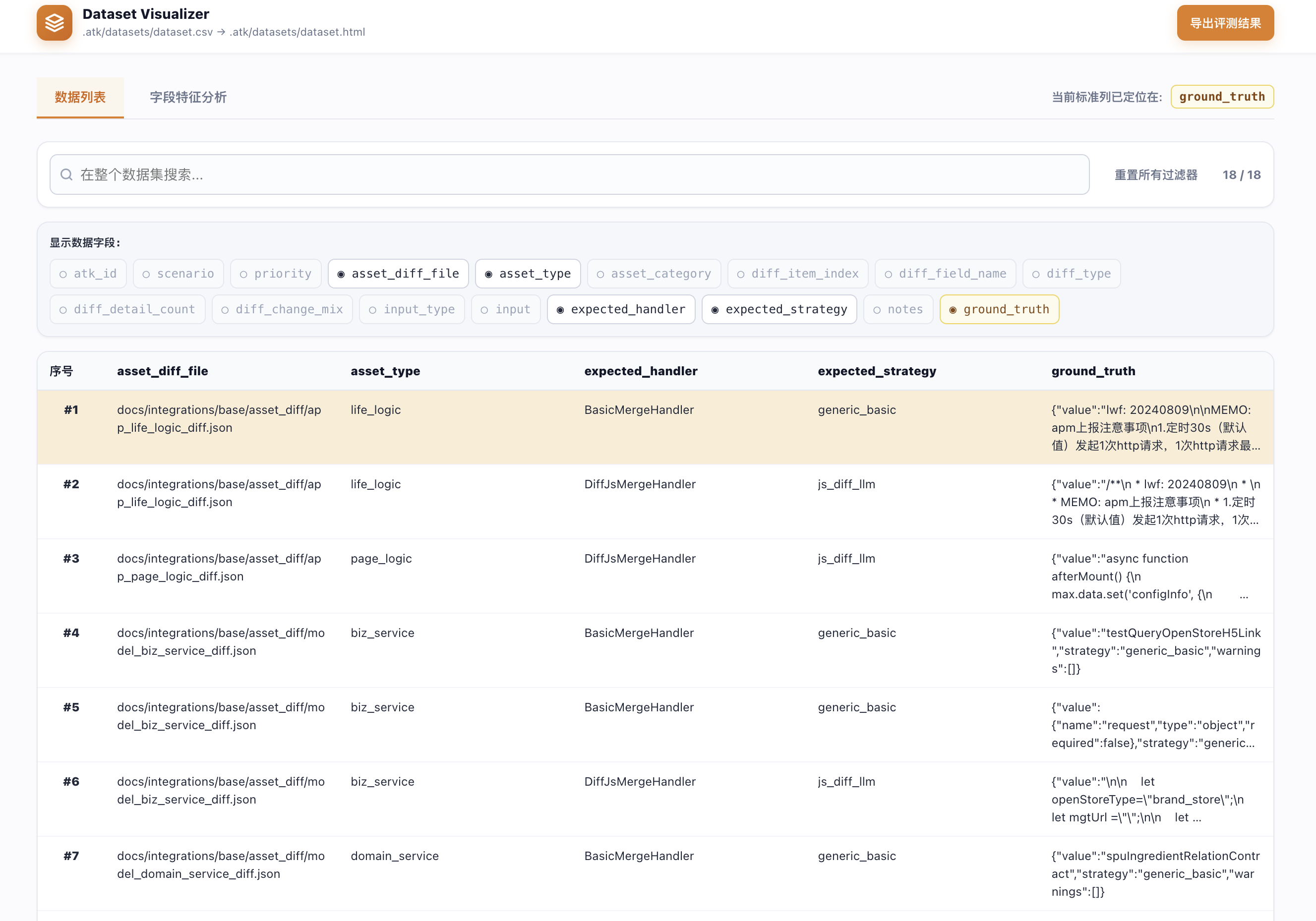
最后,atk-tune-ground-truth 会根据人工复核的反馈去修正数据集里的 ground truth。这让数据集本身也能被迭代,而不是一旦建好就成了不容质疑的标准答案。
整条链路只动 .atk/datasets/,不运行 Agent,也不产出 .atk/results/vN/。它存在的意义,就是先把“评测依据”立稳。毕竟如果 ground truth 本身是错的,后面再怎么调优,也只是把系统推得离正确答案更远。
Agent 调优链路:从评测到再验证
数据集稳定之后,才进入调优链路。它要回答的是:怎么从 Agent 的执行结果里把异常捞出来、完成归因,再把归因结论变成一次有效的修改。
ATK 是一个本地 Codex 插件。它不提供远程平台,也不要求你把 Agent 改造成某种固定接口,而是让 Codex 在你自己的项目里读懂 Agent、生成 runner、跑评测、分析失败并辅助调优。典型流程是:
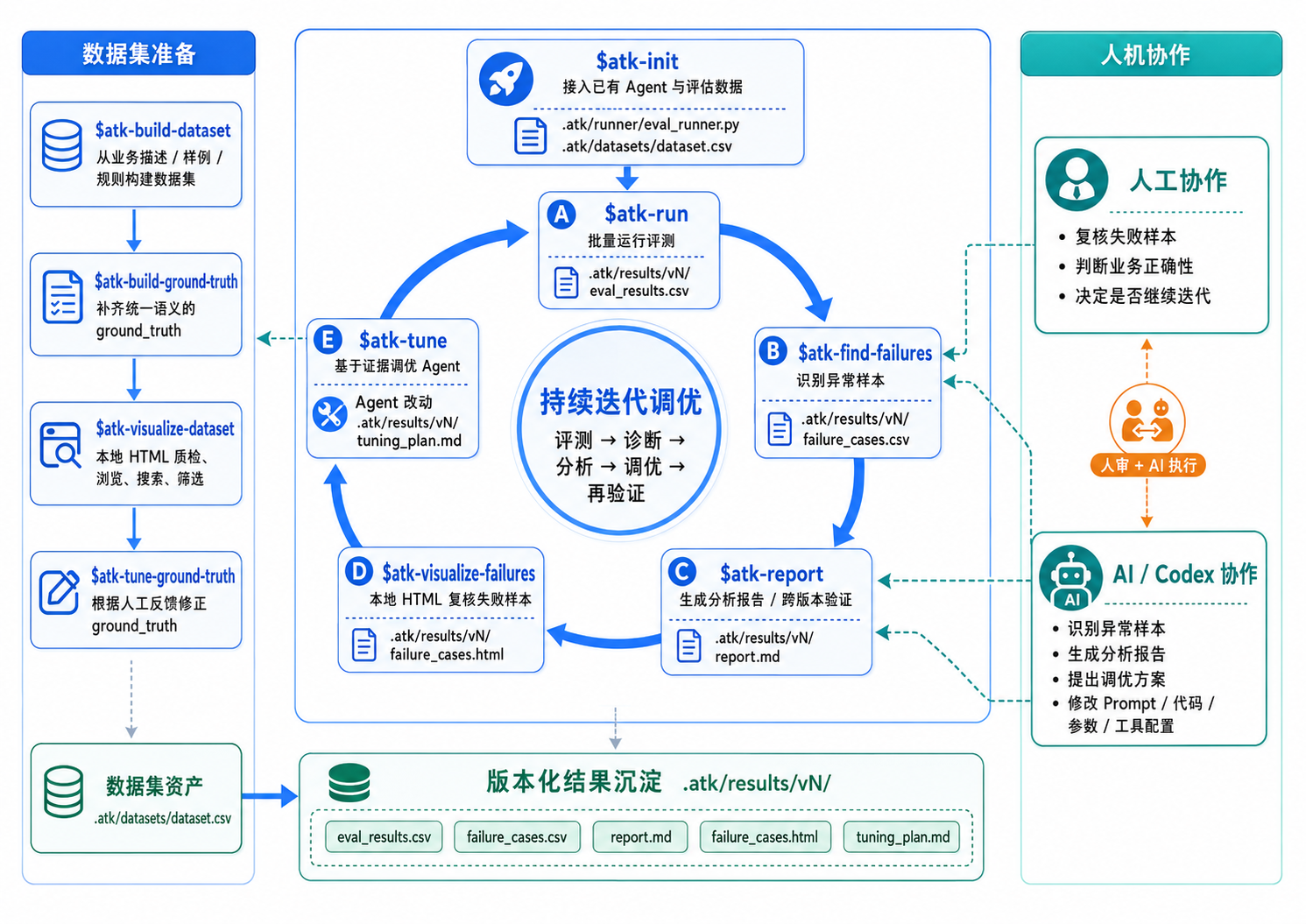
atk-init 接入你的本地 Agent 和评估数据集,生成 .atk/runner/eval_runner.py。数据集会被规范化到 .atk/datasets/dataset.csv,并用 atk_id 保持每条样本的身份稳定。
atk-run 执行批量评测,结果写进 .atk/results/vN/eval_results.csv。每一轮都落在独立的版本目录下,比如 v1、v2、v3。
atk-find-failures 从评测结果里识别异常样本,输出 failure_cases.csv。如果你已经有明确规则,也可以走规则脚本来筛。这一步要解决的,就是“从成百上千条结果里逐条捞异常”的人力成本。
atk-report 是整个闭环的关键。它不只分析当前失败原因,还会在存在上一轮 tuning_plan.md 时做跨版本验证:上一轮想解决的问题,这一轮到底是解决了、部分解决了、没解决,还是无法判断。这一步对应的,正是过去最吃人工经验的异常归因。
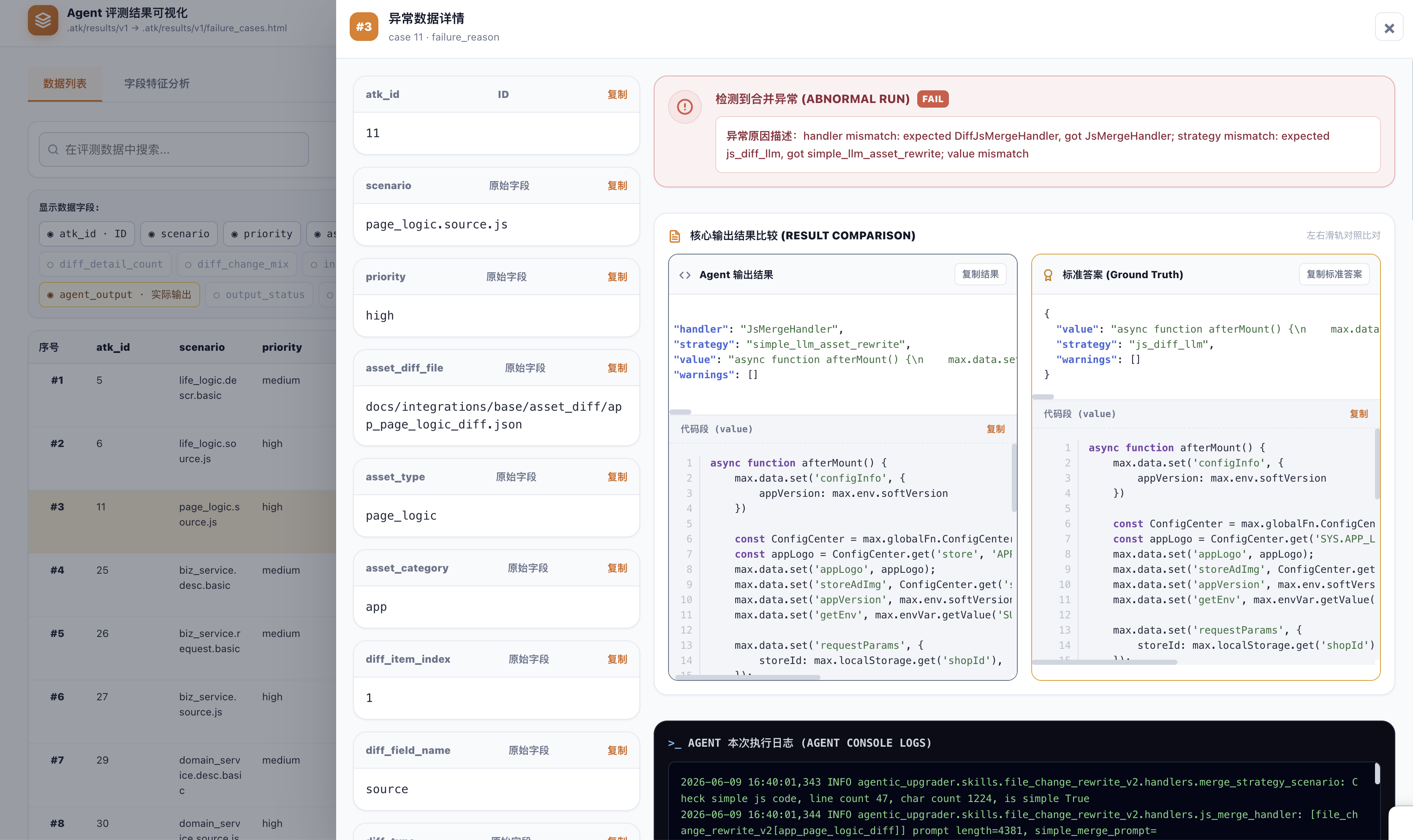
atk-visualize-failures 把当前轮筛出的异常样本渲染成本地 HTML,支持搜索、筛选和逐条浏览。它不做聚合分析,重点是把每一条异常样本摊开看:异常原因描述、Agent 输出与 ground truth 的左右对照、原始字段、本次执行日志,都摆在同一个详情页里。报告给的是结论,这里给的是现场——通过这种方式直接看具体的错误形态,比看一句”语义不一致”更容易对 Agent 当前的真实表现形成柔软、立体的理解,也更容易判断下一步该改 prompt、改代码,还是补充工具配置。
atk-tune 则根据报告和失败证据去改 Agent——可能是 prompt、代码、参数或工具配置。改完之后,它会写下 tuning_plan.md,给下一轮验证留一个明确目标。于是调优不再是“凭感觉改一版”,而是带着证据和结论去做有目标的修改。
合起来看,ATK 就是两条互相衔接的链路:
数据集构建链路:简化数据集整理和 Ground Truth 校准
Agent 调优链路:简化异常获取、归因分析和调优验证
这也是它和一次性测试脚本最大的区别。它不是为了临时跑一批样本,而是把数据准备、评测执行、异常归因、调优实施和结果验证,固化成可以反复执行的工程流程。
为什么要版本化
很多调优流程的通病在于:每一轮都是临时的。
今天改 prompt,明天换规则,后天又动数据集。几轮下来,没人说得清当前效果到底来自哪一处改动,也判断不了某个问题是不是真被修掉了。
ATK 用 .atk/results/vN/ 把每一轮隔开。每轮都会留下如下所示的文件:
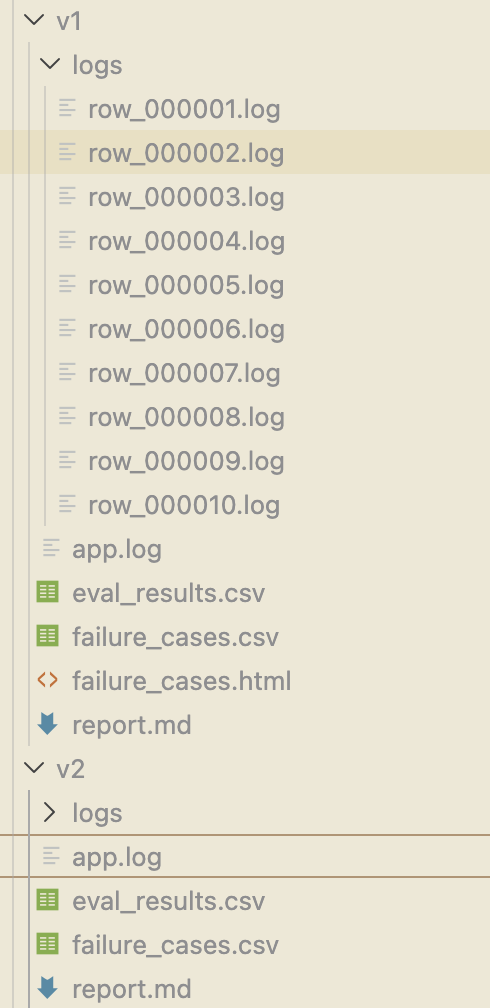
它们合在一起,就是一条朴素但有效的调优记录:
eval_results.csv记 Agent 的实际输出;failure_cases.csv记当前的失败样本;failure_cases.html是异常样本的本地可视化页面;report.md记失败归因和跨版本判断;app.log是本轮 Agent 执行链路的完整日志;logs/row_XXXXXX.log则按atk_id为每一条测试样本独立留一份执行链路日志。
这里要特别强调的是日志这一块。app.log 让你能从整体上回看本轮跑了什么、Agent 内部的工具调用和模型交互是怎么走的;而 logs/row_XXXXXX.log 则让每一条样本的执行链路都可以单独被翻出来——遇到一个异常 case,不用再去复现整轮评测,直接打开对应的 row_*.log 就能看到这一条样本从输入到输出之间,Agent 调了哪些工具、走到哪一步开始偏、最后为什么给出了错误结果。配合 failure_cases.csv、failure_cases.html 一起用,异常定位可以精确到”哪条数据、哪一步、出在哪里”,这对调优和归因的准确性是质变级的提升。
从第二轮起,报告会自动拿当前结果去对上一轮的调优计划。这样你能问的就不再是”感觉准确率好像提高了”,而是具体到:上一轮盯的那几个异常还在不在?这轮新冒出了什么问题?失败数量的涨跌只是表象,目标问题有没有被真正解决,才是核心。
一个完整的例子:三方代码合并 Agent
我实际做的一个三方代码合并 Agent,正好把调优里最耗时的两个点全踩中了:一边要不断修评分标准和 ground truth,一边要从异常结果里归因、再反推策略。详细的迭代过程在文章 将技术方案迭代出来 中有详细的记录。下面进行简要介绍:
它要处理的是主线版本、各国定制化版本和公共基线之间的合并冲突。过去团队基于专家经验设计过一套相当复杂的合并策略,投入不小,问题却依旧不少。我索性反着来:抛开所有先验,从一个最朴素的 prompt 起步,让 Codex 在数据集的指引下一轮轮迭代。
v1:一个粗糙的起点。 第一版几乎没有设计,只给了 Codex 一句话——把 source(上游分支)合并进 target(当前分支)。评分用的是最严格的字符串完全一致比对,跑出来准确率只有 40% 左右。让 Codex 分析一轮,结论是评分方式本身就不合理:很多输出只是多了个空行,语义其实完全正确,却被判成错误。把评分规则放宽到语义一致后,准确率升到 60%。
v2:找回被忽略的关键输入。 继续对异常归因,Codex 给出一个更贴近业务的判断:原始策略冲突时偏向 source 是错的,标准答案其实更倾向保留 target。更要紧的是,它注意到原始数据里还有一列 base——主线与定制版的公共基线,对判定合并结果至关重要,却在 v1 里被完全无视了。改成基于 base/source/target 三方差异来合并后,准确率跳到 87%。随后又一次评分修正(继续放过纯空格缩进的差异),把准确率推到 92%。
v3:从数据里长出确定性规则。 再往下分析,Codex 发现一条规律:忽略空行和缩进后,base 有时会和 source 或 target 中的某一方完全一致;这时最终答案通常就等于发生了改动的另一方。于是它给出一个明确的短路策略——base 等价于某一方时,直接返回另一方,连模型都不用调。准确率小幅升到 93%,但大量样本走上短路路径,整体处理效率明显提升。
v4:调优反过来发现了数据问题。 剩下 7% 的异常,Codex 给了一个意外的结论:它们处理不对,根本不是 Agent 的锅,而是标准答案里掺了无法从 base/source/target 推导出来的内容——本质是人工事后做的额外修改,已经超出了业务范围。它列出了这 7 条样本(比如某些 ground truth 平白多出一整套 RBAC 查询逻辑或额外配置项),并建议从数据集中剔除。我人工复核后确认结论成立。剔掉这部分脏数据,当前版本的准确率逼近 100%。
这个案例最有意思的地方,不是某一版 prompt 有多强,而是调优过程同时改进了两个东西:Agent 的策略,以及数据集本身的质量。所谓持续进化,从来不只是让模型“更聪明”,而是让整个系统——策略、评分标准、数据集和 ground truth——在证据里一起变好。
如何开始
安装与详细命令可以直接参考项目 README,这里只给一个最小路径:装好插件,在 Agent 项目里按需调用对应的 $atk-* Skills 即可——没有数据集就从 atk-build-dataset 起步,已有数据集就直接进入 atk-init → atk-run → atk-find-failures → atk-report → atk-tune 的调优闭环,完成一轮后用 atk-run --only-failures 回放上一轮失败样本。
不必一上来就准备大规模 benchmark。多数时候,一小组高质量样本就够把最关键的问题逼出来。真正重要的,是把数据集构建、ground truth 校准、异常获取、失败归因和调优记录沉淀下来,让后面每一次改动都能被验证。
写在最后
做 Agent 这几年,我一直在反复琢磨一个问题:设计和迭代之间,权重到底该怎么分配。传统软件开发更偏前者——先把需求分析透、把架构设计完整,再逐步实现,争取一次成型;在边界清晰、约束稳定的场景里,这套做法依然非常有效。但 Agent 面对的是开放输入和模糊语义,很多关键判断在编码前并不会完整浮现,只能在跑过真实样本之后才被一次次校正。这并不是说前期设计不重要,而是它的作用边界可能比我们习惯认为的更窄一些:设计给出一个可行的起点,剩下的判断要靠评测、失败归因和 ground truth 修正一起补齐。从这个角度看,产品、技术方案乃至 Agent 架构,与其说是被一次“设计”出来的,不如说是在数据和反馈里被持续“迭代”出来的——架构依然重要,但它更像一组会被持续验证的假设,而数据集,就是这些假设接受检验的地方。
ATK 想提供的就是这条路径——不是一个单次评测工具,而是一套本地 Agent 调优工作流。它先压低数据集构建和 ground truth 标注的成本,再压低异常获取、人工归因和调优验证的成本,让 Agent 在一份稳定的依据上反复评测、归因、修改和验证,一步步从“能跑”走向“可靠”。