背景介绍
在上周梳理了基于 RAG 的大型代码库解决方案 claude-context 后,本周继续探索另一种方案——基于图谱(Graph)的大型代码库解决方案 Graphify。
历史似乎总在惊人地重复:几年前 RAG 遭遇规模瓶颈时,微软推出了 GraphRAG,将传统的向量检索升级为知识图谱检索。如今在 AI 编程领域,同样的模式再度上演——为了解决大型代码库中的上下文记忆问题,RAG 与 GraphRAG 先后登场。Graphify 正是这一趋势下面向 AI 编程场景的最新实践。
功能简介
在 Claude Code 和 Codex 等 AI 编程工具中,默认采用基于 Grep 的精确检索方案。在中小型代码库中,这一方案运转良好;但随着代码仓库规模的持续扩大,其局限性也愈发明显。Graphify 的思路是:将整个代码库构建为一张知识图谱,以更结构化的方式来支撑检索与理解。
遵循产品界常说的 Dogfooding 理念,我尝试用 Graphify 分析了它自身的代码库。在 Codex 中执行 $graphify . 之后,工具会在本地的 graphify-out/ 目录下生成对应的代码库知识图谱。
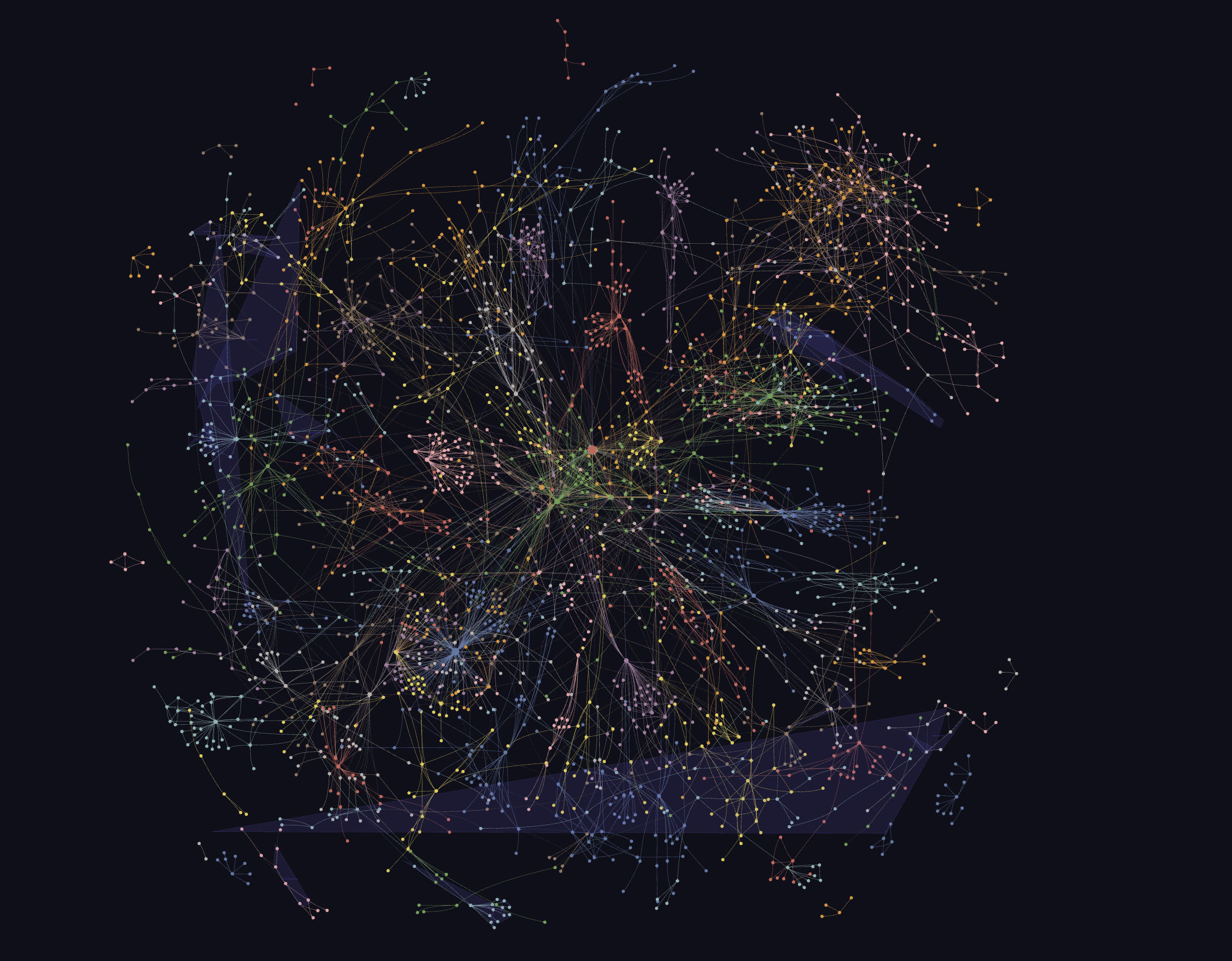
核心产出物主要有两个:
graphify-out/graph.json:以 JSON 格式存储所有图谱节点与边的原始数据;graphify-out/GRAPH_REPORT.md:完整的可读报告,除了大量的索引信息之外,还包含聚类后的 Community 结构信息,示例如下:
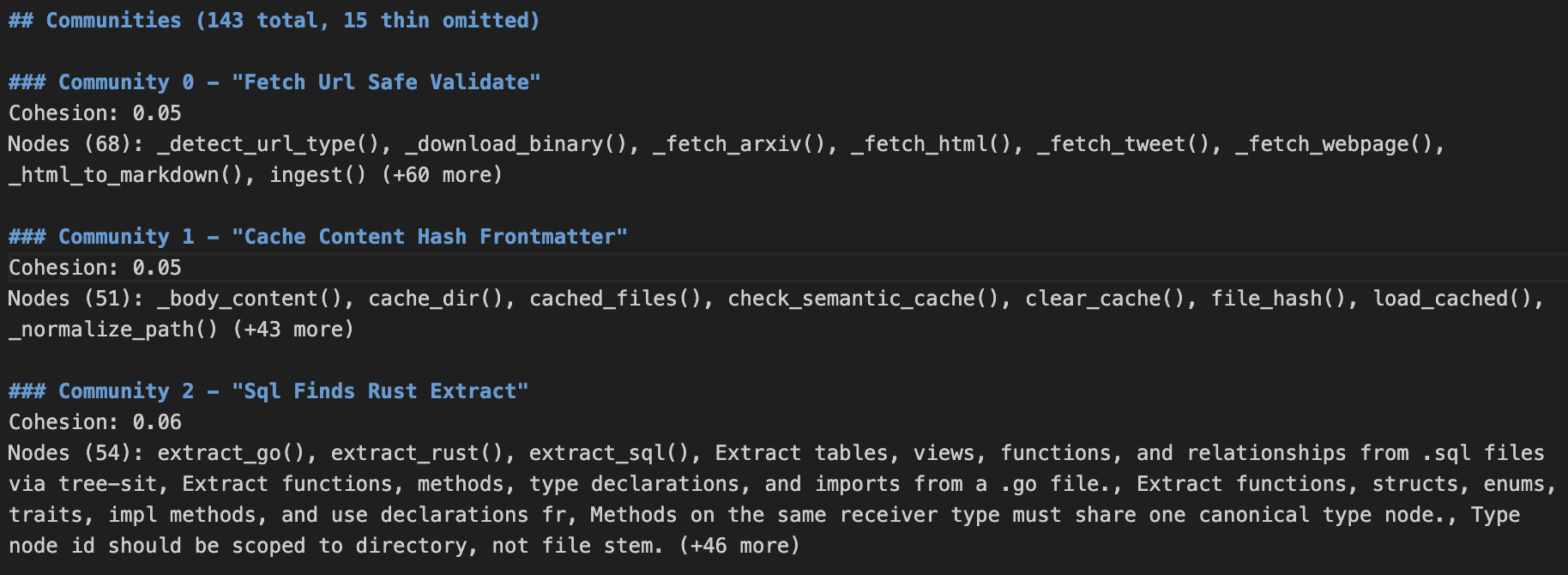
熟悉 GraphRAG 的读者不难发现,这正是 Leiden 聚类算法生成的社区结构。不熟悉的读者可以参考之前的文章:RagFlow 知识图谱实践与优化方案探索。
生成知识图谱之后,还需要让大模型”知道”这些产出物的存在。对于 Codex,可以通过 graphify codex install 命令完成接入。执行后,工具会在全局文件 AGENTS.md 中写入如下元信息,引导大模型在后续对话中主动参考知识图谱:
## graphify
This project has a graphify knowledge graph at graphify-out/.
Rules:
- Before answering architecture or codebase questions, read graphify-out/GRAPH_REPORT.md for god nodes and community structure
- If graphify-out/wiki/index.md exists, navigate it instead of reading raw files
- After modifying code files in this session, run `graphify update .` to keep the graph current (AST-only, no API cost)
从这一流程可以大致把握 Graphify 的核心价值:通过图谱化代码库,利用聚类算法提炼出更具层次感的结构信息,再将结果注入到 AI 编程工具的全局上下文中,从而提升大模型在大型代码库场景下的检索质量与推理准确性。
核心流程
Graphify 的完整处理管道如下:
detect()→extract()→build_graph()→cluster()→analyze()→report()→export()
各阶段职责简述:
| 阶段 | 职责 |
|---|---|
detect() |
扫描项目目录,识别所有可处理的源文件 |
extract() |
从文件中提取代码实体(节点)与关系(边) |
build_graph() |
将节点和边组装成 NetworkX 知识图谱对象 |
cluster() |
对图谱进行社区检测,划分功能/语义聚类 |
analyze() |
识别核心节点(God Nodes)和关键跨社区连接 |
report() |
将分析结果写入可读的 Markdown 报告 |
export() |
将图谱导出为 HTML、JSON 等格式,便于浏览和复用 |
下面对几个关键模块作进一步解析。顺便提醒下,Graphify 中的每个阶段对应一个对应的 python 文件,感兴趣的的可以搜索查看项目中对应的代码实现。
extract() 解析
extract 阶段主要做的是“抽取结构和语义关系”。
在代码文件上,它走 AST 抽取:识别文件、类、函数、方法、导入、继承、调用等实体和关系。核心入口是 graphify/extract.py 中的 extract() 方法,通用 AST 解析框架是基于 tree_sitter 实现。
在文档、论文、图片上,它走语义抽取:通过 LLM/后端抽取概念节点、语义边和 hyperedges,然后与 AST 结果合并,实现了文档与代码的统一抽取。统一的格式如下所示:
{
"nodes": [...],
"edges": [...],
"hyperedges": [...],
"input_tokens": ...,
"output_tokens": ...
}
除了完成文档与代码的统一抽取外,它还承担几个关键质量目标:
- 让节点 ID 稳定、可复现,避免不同机器绝对路径导致图不一致。
- 给边打上
EXTRACTED/INFERRED置信标记,区分确定 AST 事实和推断关系。 - 过滤悬空边、跳过模糊调用,减少后续 god nodes、community、surprising connections 被噪声污染。
- 通过缓存和并行抽取降低大仓库重复运行成本。
核心执行路径如下:
-
按文件类型分流 :
detect()先把文件分成 code、document、paper、image。code 进入 AST 抽取,docs/papers/images 进入语义抽取,具体见graphify/__main__.py文件。 -
选择对应的 extractor :
extract()通过扩展名 dispatch 到对应语言解析器,例如 Python、JS/TS、Go、Rust、Java、Markdown、SQL、Pascal 等,不同语言的解析器都放在graphify/extract.py文件中。 -
单文件 AST 抽取 : 对每个代码文件,用 tree-sitter 解析 AST,抽出:
file node、class node、function/method node,以及contains、method、inherits、imports、calls等边。节点和边统一带source_file、source_location、confidence。 -
缓存与并行 : 先查
graphify-out/cache,命中则跳过;未命中文件超过阈值时用ProcessPoolExecutor并行抽取,失败时回退顺序执行。 -
跨文件关系补全 : 单文件内找不到的调用会先存在
raw_calls,等所有文件节点合并后再解析跨文件调用。若有 import 证据,调用边提升为EXTRACTED;否则作为INFERRED。 -
合并 AST 与语义结果 : CLI 层把 AST 结果和文档/论文/图片的语义抽取结果合并,语义侧还可能提供
hyperedges。这个合并结果就是下一步build_graph()的输入。
build_graph() 解析
build_graph() 的职责相对集中:将 extract() 产出的节点与边数据,转换为后续可聚类、可分析、可导出的 NetworkX 图对象。
具体而言,它先将所有 nodes 注册为图中的实体顶点,再将所有 edges 转换为顶点间的有向关系;对于 source 或 target 无法匹配到节点的边,会在此阶段被过滤剔除,确保图的完整性。
cluster() 解析
cluster() 对图谱进行社区检测(community detection),将密集连接的节点归入同一”社区”。相比直接面对数千个原始节点,社区结构能显著降低认知负担,让人先在模块粒度上把握全局,再逐步深入细节。
这个阶段的目的不是再抽取新信息,而是把一张大图变得“可读、可导航、可分析”。它解决三件事:
- 降低认知负担:几千个节点直接看很乱,聚成社区后可以按功能区域浏览。
- 支撑后续分析:analyze() 会用 community 判断跨社区连接、意外关系、桥接节点、低内聚模块。
- 支撑导出体验:graph.json、HTML、Obsidian、Canvas 都依赖 community 给节点分类、着色、过滤。
聚类算法的具体实现如下,优先使用质量更好的 Leiden 算法,若依赖不可用则回退至 NetworkX 内置的 Louvain:
def _partition(G: nx.Graph) -> dict[str, int]:
try:
from graspologic.partition import leiden
old_stderr = sys.stderr
try:
sys.stderr = io.StringIO()
with _suppress_output():
result = leiden(G)
finally:
sys.stderr = old_stderr
return result
except ImportError:
pass
kwargs: dict = {"seed": 42, "threshold": 1e-4}
if "max_level" in inspect.signature(nx.community.louvain_communities).parameters:
kwargs["max_level"] = 10
communities = nx.community.louvain_communities(G, **kwargs)
return {node: cid for cid, nodes in enumerate(communities) for node in nodes}
analyze() 解析
analyze() 阶段本质上是把已经构建并聚类好的图,转成“可解释、可汇报、可追问”的洞察层。此阶段主要产出三类内容:
-
God Nodes 核心节点 : 通过
god_nodes()找出连接度最高的真实实体,也就是系统里的核心抽象、关键函数或高影响节点。 -
Surprising Connections 意外连接 : 通过
surprising_connections()找出跨文件、跨社区、跨类型、跨目录的非显而易见关系,并解释为什么它值得注意。 -
Suggested Questions 建议追问 : 通过
suggest_questions()生成后续探索问题,例如模糊关系、桥接节点、低内聚社区、弱连接节点等。
总结
本文对 Graphify 的核心流程进行了详细的梳理,可以看到基于图谱的知识库完整解决方案,虽然整体的思想与之前的 GraphRAG 有不少相似之处,但是也确实解决 AI 编程实际场景去增加了一些个性化的内容,比如基于代码本身的 AST 解析,从 AST 解析的结果去构建节点和边,这样效率更高,也相对更加稳定。另外在 analyze() 也结合图谱本身的特性,去发现了项目的关键节点和可疑连接,这样对于发现系统中的瓶颈以及不合理的设计都会有一些明显的的帮助。从这个角度来看,我觉得 Graphify 会是一个在 AI 编程中一些比较有价值的补充工具。