背景介绍
自 2025 年下半年以来,AI 编程技术迎来了爆发式发展, AI 编程也逐渐从编程的补全演进化自主 Agent 编程。然而尽管大模型在代码生成能力上突飞猛进,它们在实际应用中依然呈现出一种现象:在小型项目或从零开始的新项目中表现优异,但在面对历史包袱重、逻辑复杂的大型代码库时,往往显得有些力不从心。
这一困境的核心原因在于:大型项目通常存在庞大而复杂的上下文依赖。实际开发中需要考虑的代码约束、全局状态和历史设计非常多,而大模型由于上下文窗口的限制或检索能力的不足,很难考虑到所有信息。这就像是一个极其聪明但完全不了解你团队业务背景的“空降”技术专家,很难直接给出完美契合当前架构的实现方案。
在过去的解决方案中,诸如 Claude Code 等开发辅助工具主要依赖传统的 CLI 工具(如 grep、rg 等)来帮助模型快速检索相关信息。这种基于文本精确匹配的方案,在面临语义层面的查询时往往力不从心。虽然现代大模型通过增强意图理解,在一定程度上优化了构造查询条件的能力,但依然无法突破精确匹配的固有局限。
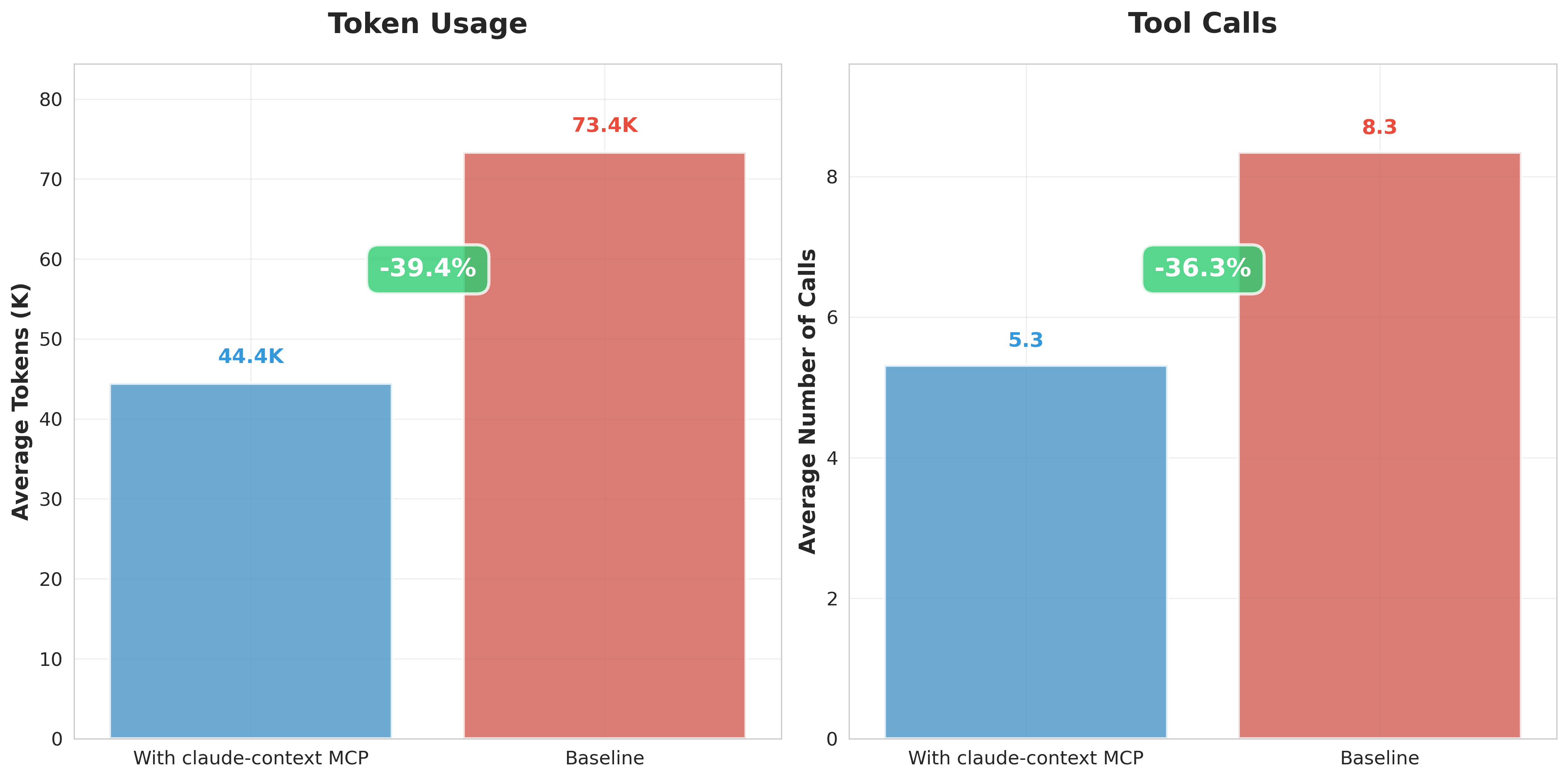
Claude-context 项目为此提供了一种全新的解法:基于 RAG(检索增强生成)技术,赋予 AI 更强的代码语义检索能力。它利用多维向量打通了自然语言与代码之间的壁垒,使得基于语义的代码查找成为可能。在官方提供的基准测试中,该方案能够降低高达 40% 的 Token 消耗,显著提升检索效率。
核心架构
当前项目的核心架构如下所示:
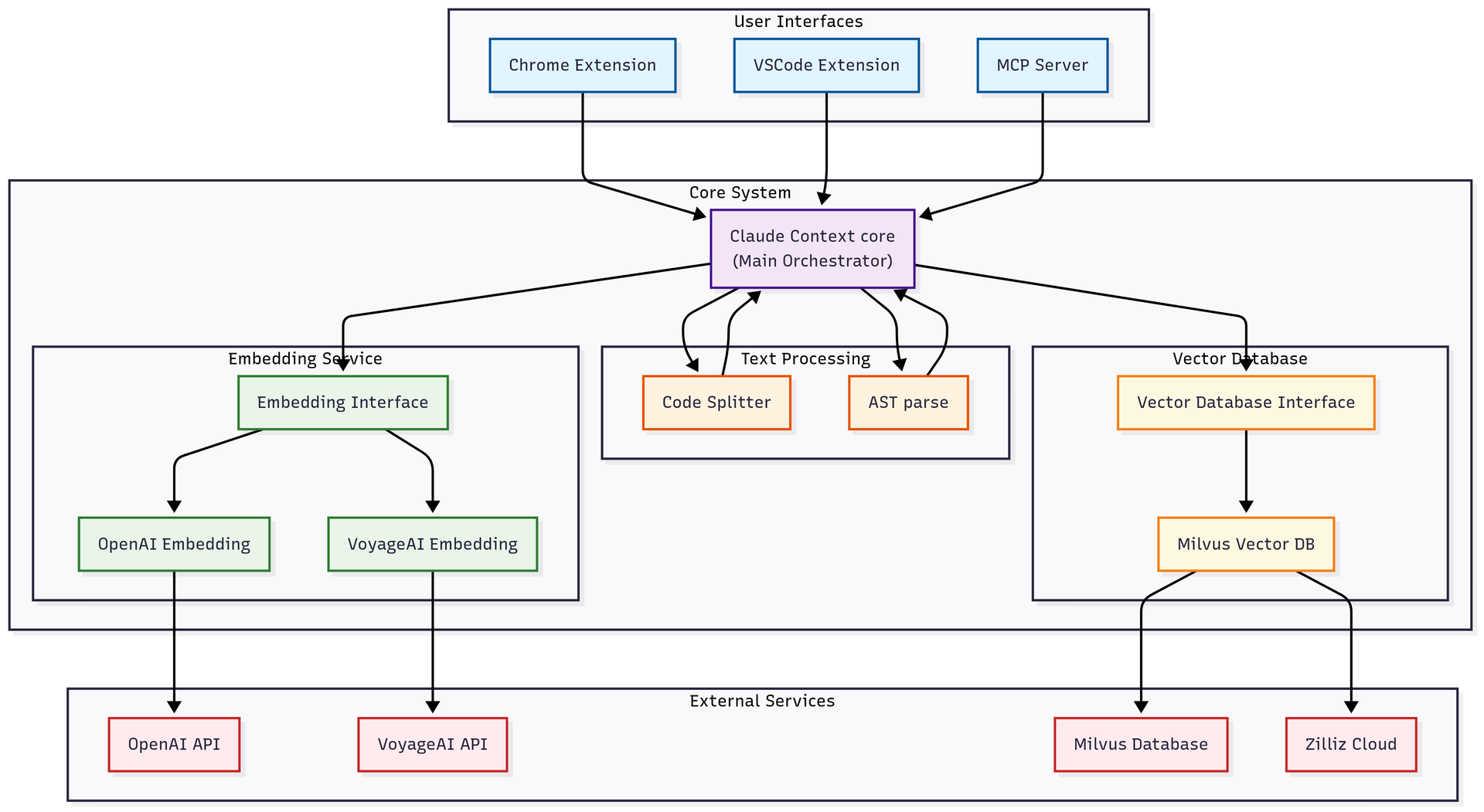
熟悉 RAG 的工程师一眼就能看出,这是一个非常经典的 RAG 架构,只不过它被专门定制用于解决代码库的检索问题:
- 左侧 Embedding Service(向量化服务):负责将代码和自然语言转换为向量。由于需要实现跨模态关联,向量模型的选型必须针对代码场景进行过专门训练。目前项目主要推荐使用 OpenAI 和 VoyageAI 的 Embedding 模型。
- 右侧 Vector Database(向量数据库):目前项目选用了 Milvus。对于代码检索场景而言,检索的准确性主要取决于前置的 Embedding 模型质量。在向量库层面,只要选用业界主流、稳定可靠的产品,通常都能很好地胜任。
- 中间的文本处理层(代码分片):这是整个方案的个性化之处。为了保证代码片段的语义完整性,项目优先采用基于 AST(抽象语法树)的切分方案;当代码块过大时,再执行必要的二次切分。
检索方案
Claude-context 采用了向量检索 + BM25 稀疏检索的混合检索方案。具体实现在 packages/core/src/context.ts 的 semanticSearch() 方法中。
得益于底层 Milvus 向量库的良好封装,这部分的代码设计极为简洁。系统只需将用户的查询意图转换为 Milvus 的混合检索请求,并在最后使用 RRF(Reciprocal Rank Fusion,倒数排名融合) 算法对检索结果进行重排。简化后的核心逻辑如下:
const searchRequests: HybridSearchRequest[] = [
{
data: queryEmbedding.vector,
anns_field: "vector",
param: { "nprobe": 10 },
limit: topK
},
{
data: query,
anns_field: "sparse_vector",
param: { "drop_ratio_search": 0.2 },
limit: topK
}
];
const searchResults: HybridSearchResult[] = await this.vectorDatabase.hybridSearch(
collectionName,
searchRequests,
{
rerank: {
strategy: 'rrf',
params: { k: 100 }
},
limit: topK,
filterExpr
}
);
代码分片方案
由于代码本身具有极强的逻辑连贯性,传统的按字符长度分片很容易破坏代码的完整上下文。因此,选择一个合理的代码分片策略至关重要。
Claude-context 默认采用基于 AST(抽象语法树)的分片方案。其核心思想是:利用 tree-sitter 将源码解析为语法树,随后按语言特性中的“逻辑单元”(如函数、类、方法、接口等)进行切分,从而最大限度地保留代码的结构完整性。具体实现位于 packages/core/src/splitter/ast-splitter.ts 中。具体流程如下所示:
- 语言支持校验:
split()方法首先检查目标语言是否受支持(目前支持 JS、TS、Python、Java、C++、Go、Rust、C#、Scala 等)。对于 Markdown 等不支持 AST 的格式,直接使用 LangChain 的后备分片策略。 - 构建解析器:根据文件类型加载对应的
tree-sitter解析器,并生成当前代码的语法树(this.parser.parse(code))。 - 加载节点白名单:针对每种语言,项目预定义了适合作为独立 Chunk 的节点类型。例如,TypeScript 的白名单中包含了
function_declaration、class_declaration、interface_declaration,method_definition等。 - 遍历与提取:通过深度优先搜索(DFS)遍历语法树。一旦遇到命中白名单的节点,便利用其起始和结束索引,从源码中截取相应的代码块作为 Chunk,并记录其行号及文件路径等元数据。
- 处理超大块与边缘情况:
- 若整个文件未匹配到任何关键节点,系统不会丢弃它,而是将全文件作为一个 Chunk 保留。
- 若截取出的 Chunk 依然过大(默认超过 2500 字符),则会基于
refineChunks()按行进一步拆分成更小的 Chunk。
- 添加 Overlap:为了防止拆分导致的上下文断裂,
addOverlap()会在第 2 个及之后的 Chunk 头部,补充前一个 Chunk 末尾的一段内容(默认 300 字符),以此保留上下文的连续性。
举例而言,假设有一个 TypeScript 文件 user.ts:
interface User {
id: string;
name: string;
}
function formatUser(user: User) {
return `${user.name} (${user.id})`;
}
class UserService {
getUser(id: string) {
return { id, name: "Ada" };
}
deleteUser(id: string) {
return true;
}
}
通过上述 AST 分片逻辑,该文件最终会被优雅地切分为多个独立的语义区块:
- Chunk 1 (interface):
interface User { ... } - Chunk 2 (function):
function formatUser(user: User) { ... } - Chunk 3 (class):
class UserService { ... } - Chunk 4 (method):
getUser(id: string) { ... } - Chunk 5 (method):
deleteUser(id: string) { ... }
(注:因为 method_definition 也在白名单中,类中的方法会被单独提取,使得检索粒度更加精细)
动态更新机制
在实际开发过程中,代码库是频繁变动的。每次代码修改如果都触发全库的重新向量化,显然是不切实际的。因此,系统必须具备高效的差异发现与增量更新机制。
基于文件内容计算 SHA-256 哈希并基于哈希确定文件的变更是比较常规的做法,但在对超大型代码库时,持续对大量文件进行逐个比对依然会比较慢。为此,项目引入了类似 Merkle DAG 的思想来进行快速的全局差异判定。
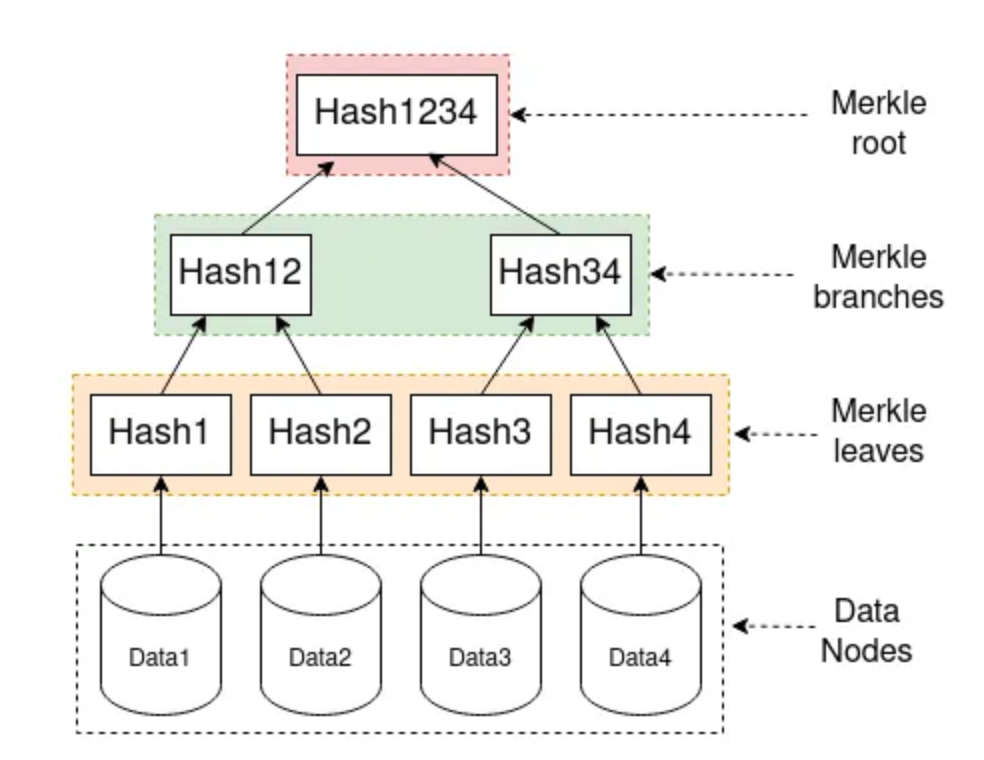
虽然 Merkle DAG 听起来高深,但它的核心思想其实非常朴素:通过文件的哈希聚合,将整个代码库的信息压缩成一个固定长度的指纹(Root Hash)。这样可以方便进行快速的差异确认。在常规情况下会针对每个目录构建目录级别的 Merkle DAG,可以逐个目录确认是否存在变更,如果目录没有变更就不需要对文件进行一一比较。核心思想如下所示:
Claude-context 的设计更为精简:它没有使用严格的多层级目录树结构,而是一个挂载所有文件节点的 Root 节点,这样可以快速确认整个代码库是否有变更,简化的原始的设计。对应的图示如下所示:
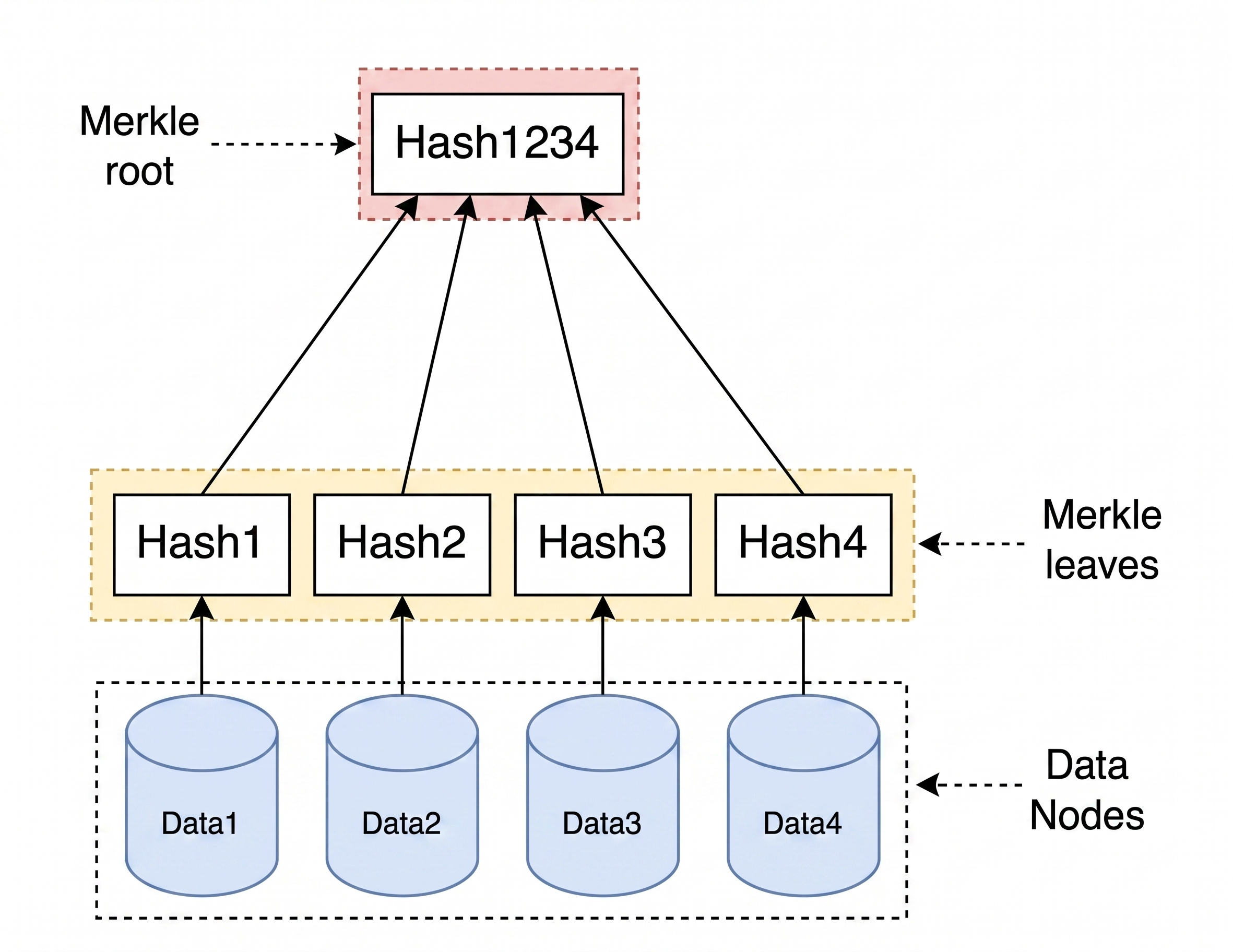
针对动态更新的核心步骤如下所示:
- 构建 Merkle DAG:系统提取所有文件路径及其哈希值。根节点(Root)的哈希值由其下所有文件的哈希拼接计算而成。只要有任意一个文件发生改动,Root 节点的整体指纹就会改变。
root: hashA + hashB + hashC ├── src/index.ts:hashA ├── src/context.ts:hashB └── README.md:hashC - 差异对比:在同步时,系统生成新的 DAG 并与本地历史记录进行比对(
MerkleDAG.compare)。如果 Root 哈希发生变化,系统才会深入比对具体的文件级映射,从而精确定位:- 新增文件:新映射中有、旧映射中没有。
- 修改文件:新旧均存在,但哈希值不同。
- 删除文件:旧映射中有、新映射中没有。
- 精准清理与重建:
在明确了增删改的文件列表后,
Context.reindexByChange()会按以下顺序处理:- 清理失效数据:对于被移除(removed)或发生修改(modified)的文件,系统会根据其文件路径查询 Milvus 向量库,批量删除这些文件对应的所有旧 Chunk。
- 增量重嵌入:随后,系统仅将发生变更的文件(新增 + 修改)送入切片和 Embedding 流程,并重新写入向量库。
由于全程仅针对变更文件进行重嵌入处理,避开了对整个仓库的重复计算,这成为了该方案在面对巨型代码库时,依然能保持极高更新效率的根本原因。
总结
本文深入探讨了 Claude-context 项目的核心架构与设计思路。随着 AI 辅助编程逐渐步入“深水区”,AI 工具需要直面复杂老旧大型项目的维护挑战。在这种背景下,如何更高效、更精确地进行代码检索与上下文匹配,其价值日益凸显。
尽管 Claude-context 目前的整体架构相对轻量,解决方案也仍在不断迭代中,但它已经为构建工业级的 AI 代码检索系统提供了一个极具参考价值的范本。希望本文能为大家在探索大型代码库的 AI 智能化赋能之路上,提供一些有益的参考与借鉴。