背景介绍
在之前的文章 中对 FATE 的调度系统 FATE-Flow 从源码角度进行了介绍,FATE 的可视化 FATE-Board 之前也介绍过了,对于 FATE 底层使用的数据传输机制 Eggroll 一直没有过多介绍。
而这一块的技术细节一直没有太多的资料可以参考,官方文档 上只有 Eggroll 部署相关的内容,网络上基本搜不到 FATE 底层数据传输 Eggroll 原理分析的内容,而 Eggroll 源码 使用的 Python + Java + Scala 的开发语言,导致想了解细节的成本也会更高一些,估计这也是劝退部分人的一些原因。最近刚好有空,阅读了 Eggroll 的实现细节,整理相关内容在这边,希望给后面的人降低点门槛。
注意,本文针对是截止 2023-9 月最新的版本 v2.5.1,后续的版本可能会有所差异。
架构介绍
在开始介绍具体的细节前,先看看建立在 Eggroll 上 FATE 的整体架构:
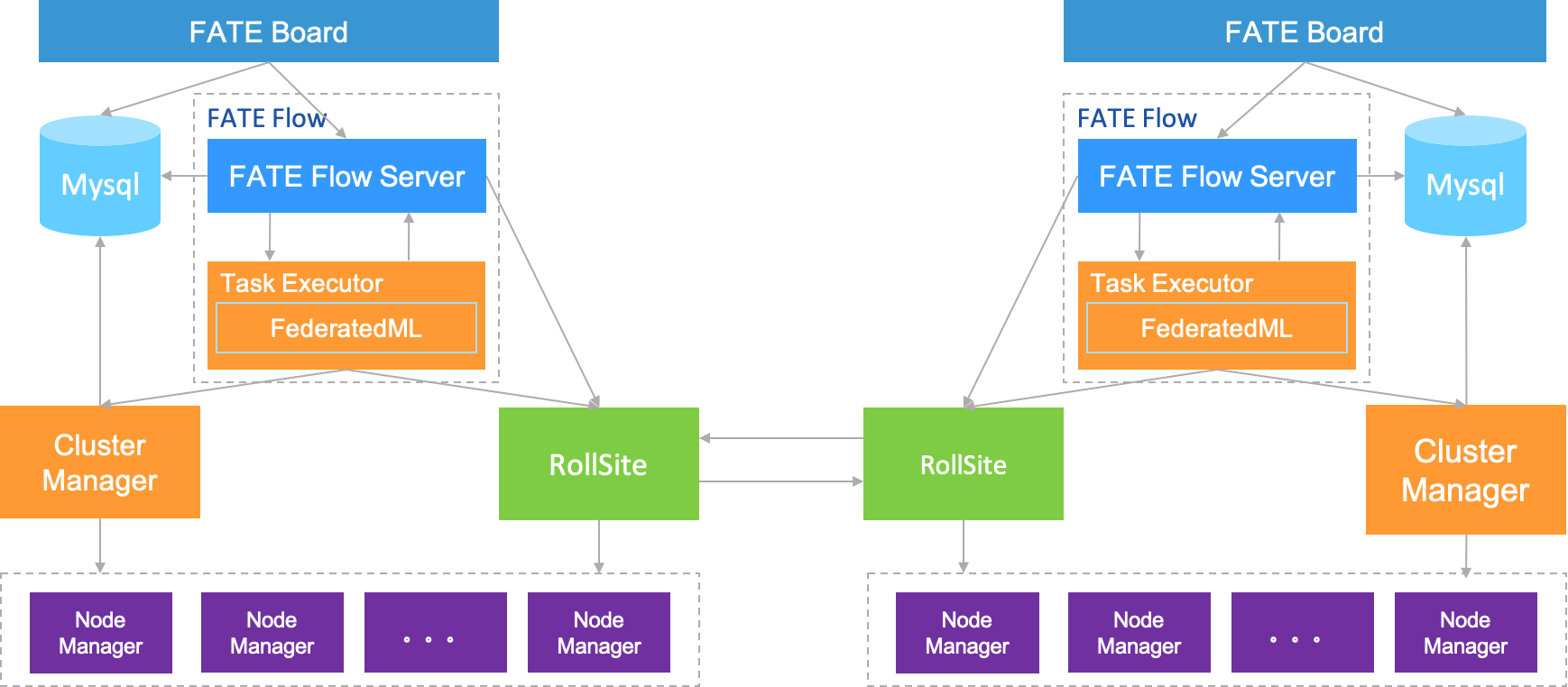
通过上面的架构图可以看到,FATE 部署在 Eggroll 上时,是使用 RollSite 进行数据传输的,Rollsite 作为 Eggroll 的一部分,主要承担各个互相通信的支撑,这篇文章主要分析 RollSite 的实现细节。
FATE 作为一个联邦学习框架,需要承载多方进行机器学习模型的训练,部分机器学习模型的体积可能会比较大,为了支持这部分的数据传输需求,RollSite 预期是具备大数据传输的能力,本篇文章就会揭开其中的实现细节。
RollSite 原理介绍
在进行源码层面的分析前,先对 RollSite 的原理进行概述,方便部分不想深入到源码层面,但是又对 FATE 的数据传输机制感兴趣的研发同学们。
RollSite 在数据传输时使用的推拉模式,发送方调用 push() 将数据推送出去,接收方异步调用 pull() 拉取数据。
数据发送
数据发送的一般流程如下所示:
- 使用 pickle 对待发送的数据进行序列化,生成对应的字节数据;
- 对生成的字节数据进行分片,使用分片序号标记分片的顺序,方便接收方进行组装还原得到原始数据;
- 将分片序号与分片数据组装成字节流
batch,对应的格式如下所示:
- 将字节流
batch包装为 gRPC 包Packet,通过 gRPC 请求发送出去;
数据拉取
数据拉取的流程如下所示:
- 根据 namespace 和 name 获取对应的存储对象 store;
- 依次从 store 中包含的各个分区 partitions 中获取对应的字节流
batch; - 将字节流
batch进行反向分解,获取原始数据分片序号与分片数据; - 按照分片序号对分片数据进行排序后拼接,将拼接后数据进行反序列化得到原始数据;
数据发送源码解析
调用入口 RollSite.push
数据推送对应的入口为 eggroll/python/eggroll/roll_site/roll_site.py 中的 RollSite.push() 方法,实现代码简化后如下所示:
def push(self, obj, parties: list = None, options: dict = None):
futures = []
for role_party_id in parties:
# 本次推送相关的信息保存至 ErRollSiteHeader 中,包括源 party 的 id,目的 party 的 id 等信息
rs_header = ErRollSiteHeader(
roll_site_session_id=self.roll_site_session_id, name=self.name, tag=self.tag,
src_role=self.local_role, src_party_id=self.party_id, dst_role=dst_role, dst_party_id=dst_party_id,
data_type=data_type)
# 使用线程池中线程发起实际的数据推送,避免进行阻塞主线程,同时提升并发效率
# 实际的传输处理是在 RollSiteContext 初始化时注册上的,目前仅注册了 gRPC,因此实际是通过 RollSiteGrpc 发起数据传输
if isinstance(obj, RollPair):
future = self._run_thread(self._impl_instance._push_rollpair, obj, rs_header, options)
else:
future = self._run_thread(self._impl_instance._push_bytes, obj, rs_header, options)
futures.append(future)
return futures
可以看到实际的发送封装在 self._run_thread() 方法中的,实际的数据在线程中执行,这样可以避免阻塞执行主线程,同时在 IO 密集型的数据发送任务效率更高。
实际的发送是通过调用 RollSiteGrpc._push_rollpair() 或 RollSiteGrpc._push_bytes() 实现的,后续选择基于最原始的 _push_bytes() 介绍发送流程
发送流程 - 数据分片
gRPC 默认的数据传输上限为 4MB, 虽然可以通过调整配置将上限提高至 2GB,但是在单个网络请求中发送过大的数据依旧不太可靠谱,传输中意外的中断可能就意味着完整的数据都需要重新发送。
RollSite 对数据进行了分片发送,数据分片是由 _push_bytes() 中包含的 _generate_obj_bytes() 方法完成,具体的实现如下所示:
# 对数据进行分片,返回分片序号以及对应的分片数据
def _generate_obj_bytes(py_obj, body_bytes):
key_id = 0
# 基于 pickle 进行序列化,保证支持不同类型的数据
obj_bytes = pickle.dumps(py_obj)
obj_bytes_len = len(obj_bytes)
cur_pos = 0
while cur_pos <= obj_bytes_len:
# 分片返回数据,每片返回包含 `分片序号, 分片数据`,后续可以基于分片序号进行组装
yield key_id.to_bytes(int_size, "big"), obj_bytes[cur_pos:cur_pos + body_bytes]
key_id += 1
cur_pos += body_bytes
可以看到实现中基于 pickle 进行了序列化,之后按照 body_bytes 定义的大小对原始数据进行了分片,并通过迭代器返回分片序号和对应的数据
发送流程 - 数据组装为 batch
分片序号与分片数据需要组装为一个整体进行发送,实际的组装是调用 eggroll/python/eggroll/roll_pair/transfer_pair.py 中的 pair_to_bin_batch() 方法完成的,此方法可以将多个分片的序号,分片数据组合成一个 batch ,方便后续进行发送,实现的格式如下:
具体的实现简化后如下所示:
def pair_to_bin_batch(input_iter, limit=None, sendbuf_size=-1):
pair_count = 0
# 临时缓冲区
ba = None
buffer = None
writer = None
# 返回缓冲区内的数据,并清空缓冲区
def commit(bs=sendbuf_size):
nonlocal ba
nonlocal buffer
nonlocal writer
bin_batch = None
if ba:
bin_batch = bytes(ba[0:writer.get_offset()])
# 指定缓冲区大小,通过缓存中限制了单次传输的数据量大小
ba = bytearray(bs)
buffer = ArrayByteBuffer(ba)
writer = PairBinWriter(pair_buffer=buffer, data=ba)
return bin_batch
# 首次 commit 初始化缓冲区
commit()
# 通过持续迭代处理,将原始数据转化为 二进制 batch
for k, v in input_iter:
try:
writer.write(k, v)
pair_count += 1
if limit is not None and pair_count >= limit:
break
except IndexError as e:
# 报错时反映当前数据的插入超过缓冲区的大小,通过 commit 将数据返回,并清空缓冲区
yield commit(max(sendbuf_size, len(k) + len(v) + 1024))
writer.write(k, v)
# 将缓冲区内的数据返回
yield commit()
上面的实现有点不太好理解,而且因为将缓冲区的修改隐藏在 PairBinWriter 对象中,导致更加不清晰。下面给出一些关键点,帮助大家更容易理解这段代码:
- 上面的
ba实际是一个临时缓冲区,而commit()实现的能力是每次调用时都会返回缓冲区ba中已有的数据,并清空缓冲区; - 单次 commit() 返回的数据就是
batch,其长度受缓冲区的大小限制,可以通过sendbuf_size指定。 batch数据头的写入是在commit()中初始化PairBinWriter对象时完成的,写入的格式与前面图示一致;batch数据段是在调用writer.write()写入,此方法事实上就是往缓冲区ba的空间中直接写入,并配合上偏移量offset的不断更新;batch写入时如果超出了缓冲区ba定义的大小,就会触发IndexError, 从而触发commit()返回数据并清空缓冲区;
通过上面的方法可以将原始的 分片序号,分片数据 组合成 batch,方便后续进行发送
发送流程 - batch 分组
将原始的数据转换为 batch 后,理论上就可以直接进行发送了,但是为了提升发送的效率,单次 gRPC 请求会发送多个 batch。
Rollsite 通过 _generate_batch_streams() 实现 batch 分组,单次 gRPC 就会发送一个组的数据。实现的代码如下所示:
实现的方法就是在生成器中嵌套生成器的方法,_generate_batch_streams() 方法迭代返回的每个元素都是一个 chunk_batch_stream 生成器。这样为了获取元素可以通过如下所示形式
def _generate_batch_streams(self, pair_iter, batches_per_stream, body_bytes):
# 将原始 key, value 的迭代器转换为一个自定义格式的自定义字节流格式 batch, 单个 batch 中数据不超过 body_bytes 的大小
batches = TransferPair.pair_to_bin_batch(pair_iter, sendbuf_size=body_bytes)
try:
peek = next(batches)
except StopIteration as e:
self._finish_partition = True
# 将原有的 batch 进行了分组,每组包含 batches_per_stream 个 batch
def chunk_batch_stream():
nonlocal self
nonlocal peek
cur_batch = peek
try:
for i in range(batches_per_stream - 1):
next_batch = next(batches)
yield cur_batch
cur_batch = next_batch
peek = next(batches)
except StopIteration as e:
self._finish_partition = True
finally:
yield cur_batch
while not self._finish_partition:
self._rs_header._stream_seq += 1
# 这边使用 yield 返回,因此迭代访问 _generate_batch_streams 获取的每个元素是一个生成器,需要通过 list(xxx) 获取每个元素的列表
yield chunk_batch_stream()
上面的代码实际上一个生成器嵌套生成器的模式,_generate_batch_streams() 方法迭代返回的每个元素都是一个 chunk_batch_stream 生成器,获取 batch 实际上需要采用类似如下所示的形式才能获取到:
batch_streams = _generate_batch_streams(pair_iter, batches_per_stream, body_bytes)
for bs in batch_streams:
for batch in bs:
print(batch)
而 chunk_batch_stream() 实际上时通过不断调用 next() 方法获取 batch 对象的,最终实现的效果是将一维的 batch 列表转变为二维的数据列表。
注意上面的实现实际上存在一个隐患,如果仅仅进行一维的遍历会因为 _finish_partition 一直无法结束进入死循环。
发送流程
数据推发送是通过调用 RollSiteGrpc._push_bytes 方法完成,通过上面介绍的 _generate_batch_streams 生成的 batch 组,依次将 batch 转化为 gRPC 包 Packet,然后调用 gRPC 服务的 push() 方法进行数据发送。简化后实现如下:
def _push_bytes(self, obj, rs_header: ErRollSiteHeader, options: dict = None):
# 执行数据分片,并将分片的数据转换为 batch 组迭代器
bs_helper = _BatchStreamHelper(rs_header=rs_header)
bin_batch_streams = bs_helper._generate_batch_streams(
pair_iter=_generate_obj_bytes(obj, self.batch_body_bytes),
batches_per_stream=self.push_batches_per_stream,
body_bytes=self.batch_body_bytes)
# 构造 gRPC Client
grpc_channel_factory = GrpcChannelFactory()
channel = grpc_channel_factory.create_channel(self.ctx.proxy_endpoint)
stub = proxy_pb2_grpc.DataTransferServiceStub(channel)
for batch_stream in bin_batch_streams:
# 获取单个 batch 组,对应一个生成器,通过 list 方法转换为列表
batch_stream_data = list(batch_stream)
# 基于 batch 组构造的 Packet 迭代器,通过 gRPC 进行发送
stub.push(bs_helper.generate_packet(batch_stream_data, cur_retry), timeout=per_stream_timeout)
完整的实现中会包含异常处理,每次调用 push() 时都支持异常重试,通过分片发送,避免了异常时需要重发完整的数据,而且发送的数据量更小,也更容易发送成功,整体效率会更高。
数据发送对应的服务端实现位于 java/com/webank/eggroll/RollSite/grpc/service/DataTransferPipedServerImpl.java,因此服务端的启动应该是需要具备 java 运行环境的,虽然不确定 FATE 团队选择这样的多语言方案的原因,但是确实反映了 gRPC 跨语言的便利性。
数据拉取源码解析
数据拉取是通过调用 eggroll/python/eggroll/roll_site/roll_site.py 中的 pull()方法实现的,和发送的原理类似,此方法就是通过在线程中调用 RollSiteGrpc._pull_one() 实现,这部分的代码比较简单,直接快进至具体数据拉取的实现。
数据拉取流程
数据拉取是在 _push_one() 中完成的。在开始数据拉取前,会通过反复调用 get_status() 确认所有的数据都已经传输完成,确认完成则开始进行实际的数据拉取。具体的实现如下所示:
def _pull_one(self, rs_header: ErRollSiteHeader, options: dict = None):
for cur_retry in range(self.pull_max_retry):
pull_attempts = cur_retry
# 获取数据传输是否全部完成
pull_status, all_finished, total_batches, cur_pairs = get_status(self)
if not all_finished:
if last_cur_pairs == cur_pairs and cur_pairs > 0:
raise IOError(f"roll site pull waiting failed because there is no updated progress: rs_key={rs_key}, "
f"rs_header={rs_header}, pull_status={pull_status}, last_cur_pairs={last_cur_pairs}, cur_pairs={cur_pairs}")
else:
# 数据传输完成,获取数据对应的 RollPair 对象
rp = self.ctx.rp_ctx.load(name=rp_name, namespace=rp_namespace)
if data_type == "object":
# 从 RollPair 中获取完整的对象
# 基于包序号进行排序,并将排序后的数据组装起来,执行反序列化得到原始数据
result = _serdes.deserialize(b''.join(map(lambda t: t[1], sorted(rp.get_all(), key=lambda x: int.from_bytes(x[0], "big")))))
else:
result = rp
return result
通过上面的代码可以最核心的代码就是 _serdes.deserialize(b''.join(map(lambda t: t[1], sorted(rp.get_all(), key=lambda x: int.from_bytes(x[0], "big"))))),这行代码实现了如下功能:
- 调用
get_all()获取分片的数据; - 基于分片序号排序分片数据;
- 通过
join()方法拼接分片数据; - 调用
_serdes.deserialize()进行反序列化,得到原始数据。
数据获取的 get_all() 方法就是通过调用 transfer_pair.gather() 完成数据的获取,下面对这个方法进行分析
实际数据获取
实际的数据获取是通过调用 eggroll/python/eggroll/roll_pair/transfer_pair.py 中的 gather() 方法完成的,传入的 store 包含了数据存储对应的分区 partition,通过对 partition 进行遍历,依次获取 partiton 中包含的 batch 数据块列表,并执行反向分解,即可得到对应的分片数据。具体的实现如下所示:
def gather(self, store):
client = TransferClient()
for partition in store._partitions:
tag = self.__generate_tag(partition._id)
# 请求地址
target_endpoint = partition._processor._transfer_endpoint
# 获取 tag 对应的数据块
batches = (b.data for b in client.recv(endpoint=target_endpoint, tag=tag, broker=None))
# 解析数据块,得到 `分片序号, 分片数据` 对
yield from TransferPair.bin_batch_to_pair(batches)
上面的实现中通过 client.recv() 调用获取原始数据,实际就是通过发起一次 gRPC 调用获取数据,然后调用 TransferPair.bin_batch_to_pair() 分解 batch 获取分片序号与数据,由于 batch 的格式已经预先定义后,分解的过程也就是解析对应的字节,并进行类型的转换。
总结
通过前面的梳理,从源码角度对 FATE 中的 Eggroll 中的数据传输机制进行了介绍,FATE 中通过数据分片与编号,通过设计良好的数据流格式,实现了鲁棒性更高的大数据传输需求,从而支撑了 FATE 进行了多方的模型与其他类型的数据传输需求。