背景介绍
最近在学习和实践机器学习相关内容,日常的工作主要是涉及联邦学习相关工程领域的开发,这次就从算法的角度来介绍一个联邦学习下的机器学习算法是怎样的。虽然是以线性回归算法为例,事实上其他的机器学习算法,比如逻辑回归,MLP 等也完全适用,进行少量的改造即可。
本文的开发主要基于 Pytorch 实现,主要以实践为主,不包含具体的公式推导。
线性回归算法实现
线性回归 是机器学习领域最基础的算法,通过直线 y = wx + b 拟合现有数据,最终实现损失的最小化。如果对基础的机器学习算法感兴趣可以去 B 站学习吴恩达的入门课
一般情况下,机器学习算法都是基于 Sklearn 实现的,而本文的实践主要是基于 Pytorch 实现的,这样可以用类似的机制做法直接适配实现深度学习相关算法。本文的算法实践过程参考 PyTorch深度学习实践 ,这个视频课程也做的比较好,感兴趣可以看看
目前 Pytorch 的算法实现过程主要分为如下所示的步骤:
- 准备数据集 (dataset);
- 设计模型 (model);
- 构建损失函数和优化器 (loss, optimizer);
- 实现完整的训练流程 (train cycle);
下面的算法实现也从这四个步骤来介绍。
准备数据集
数据集是用于训练过程的原始数据,在实际中根据实际情况进行准备。这边出于介绍方便,就直接使用刘老师课程中使用的人工构造的数据:
import torch
x_data = torch.tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0]])
其中的 x_data 是自变量,y_data 是对应的因变量,本例子中期望找到最合适的参数 w, b,从而实现 y = wx + b 对应的损失最小化。
设计模型
基于 pytorch 实现的模型都需要继承自 torch.nn.Module,并需要实现对应的前馈方法 forward(),线性回归算法的实现如下所示:
class LinearRegressionModel(torch.nn.Module):
def __init__(self, in_features) -> None:
super().__init__()
self.linear = torch.nn.Linear(in_features, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearRegressionModel(1)
在上面的实现中我们初始化时使用了 torch 提供的线性回归模型 Linear,实现的前馈过程也是简单调用线性回归模型的 __call__() 方法即可。我们传入的参数 in_features 为 1,表示对应的特征维度为 1,对应一维线性函数 y = wx + b。
构建损失函数和优化器
对于线性回归模型,损失函数一般使用均方误差,对应于 1/n * (y_pred - y)^2, 误差为预测值 y_pred 与实际值 y 的差值取平方,最后再取均值,对应的代码如下所示:
criterion = torch.nn.MSELoss()
对于算法执行中,一般都是通过梯度下降来调整现有的参数,从而实现更小的的损失值,最终保证模型的效果在现有数据中表现越来越好的。优化器有很多选择,目前我们就选择简单的 SGD 优化器即可,对应的代码如下所示:
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)
其中 lr 表示学习率,决定了梯度下降的速度,如果太小则训练需要的时间会比较久,如果太大会导致模型无法收敛,最终可能训练失败。
实现完整的训练流程
常规的模型训练过程一般是进行多轮的迭代,在单个轮次内,执行下面的步骤:
- 前馈模型训练;
- 获取模型损失值;
- 反馈调整梯度;
一个简单的代码示例如下所示:
for epoch in range(100):
# 前馈,得到预测值
y_pred = model(x_data)
# 基于预测值与实际值,得到损失值
loss = criterion(y_pred, y_data)
# 反馈,基于梯度下降调整梯度
optimizer.zero_grad()
loss.backward()
optimizer.step()
通过不同迭代,最终得到满足要求的模型。
联邦学习下线性回归算法实现
联邦学习 是 Google 2016 年提出一种多方联合进行模型训练的技术方案,通过各个参与方独立进行模型训练,然后将各个参与方训练的模型进行聚合得到新的模型,这样可以在不需要将原始数据给出去,就可以实现联合的模型训练。通过这种方式就解决了数据孤岛问题,各方都可以在不需要拿到其他方隐私数据的情况下就获得了使用这些数据训练出更好模型的能力
对于模型聚合方案,Google 给出的聚合方案是 FedAvg,事实上这个方案极其简单,就是通过对多方的模型参数取平均值即可。
联邦学习训练流程
联邦学习训练的基础流程如下所示:
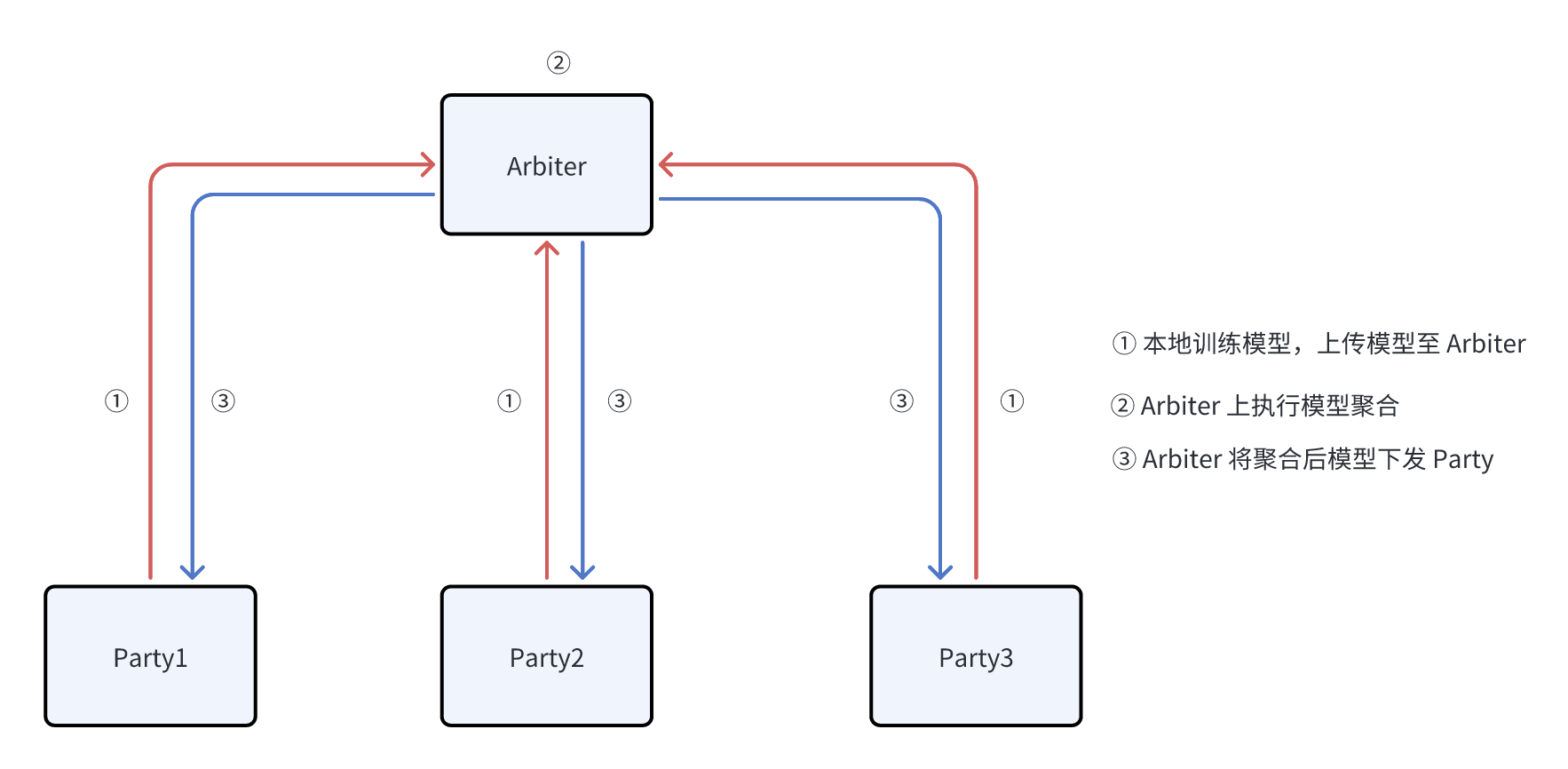
可以看到主要包含两种角色:
- Arbiter,此角色主要负责协调各方进行模型训练,在当前的情况下主要进行模型的聚合。
- Party,此角色主要负责执行本地模型训练,Party 方是可以访问到数据,因此可以基于本地的数据进行模型的训练;
可以看到整体的流程主要包含如下所示:
1.本地模型训练,此步骤下模型训练与常规的机器学习的流程类似,训练得到单次迭代生成的模型,并将对应的模型上传至 Arbiter;
- Arbiter 使用 FedAvg 算法执行模型聚合,聚合后得到的模型接近使用各个 Party 的数据合并在一起训练的模型;
- Arbiter 将聚合后的模型下发至各个 Party,Party 使用聚合后的模型更新本地的模型,开始新一轮的训练;
Party 方算法实现
Party 方的主要完成本地模型的训练,因此执行的算法与常规的模型的训练类似,定义数据集,模型,损失函数与优化器与之前的流程没有明显的差异,这边不再过多介绍了,主要关注模型训练过程,单个迭代周期内只执行一轮的模型训练,实现的算法如下:
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
optimizer.zero_grad()
loss.backward()
optimizer.step()
在执行完单次的模型训练后,会将训练的模型发送给 Arbiter,模型对应的参数通过 model.state_dict() 获取到,模型的发送目前常规的隐私计算框架选择的是 GRPC,其他框架只要能实现数据的通信预期也是 OK 的。
Arbiter 方算法实现
Arbiter 方主要基于 FedAvg 完成各方模型的聚合,并将聚合后的模型下发至各个 Party 方。此算法只是基于已有的参与取平均值即可。在获取到各个 Party 方传输的模型后,先暂存至 model_params 列表中,后续的处理如下:
keys = model_params[0].keys()
avg_para = {}
for para in model_params:
for key in keys:
avg_para[key] = avg_para.get(key, 0) + para.get(key, 0)
for key in keys:
avg_para[key] = avg_para[key] / len(model_params)
上面 Arbiter 基于各个 Party 方传入的模型列表 model_params,生成了最终的聚合模型 avg_para,并将聚合生成模型发送至各个 Party 方,而 Party 方获取到对应的模型后通过 model.load_state_dict(avg_para) 更新本地的模型。
上面的过程就是一次迭代的完整流程,通过持续迭代多轮,最终即可完成最终模型的训练
总结
本文主要以线性回归算法为例介绍了常规的机器学习模型训练过程,以及基于 FedAvg 的联邦学习模型训练的过程,主要是对完整流程进行综述,对于部分细节没有展开,比如具体的多方数据传输的封装,以及算法评估等问题。但是通过这篇文章,足够对如何使用 Pytorch 进行算法训练,以及联邦学习的基础训练过程有一定的了解了。