背景介绍
之前整理了一篇文章 FATE 纵向联邦学习实现探索 整体介绍了纵向联邦神经网络模型训练的流程,从中可以大致了解 FATE 纵向联邦神经网络中的模型设计:
- 包含训练的数据的参与方会训练一个本地模型(Bottom Model),此模型用于提取本地数据中包含的特征;
- 包含标签的参与方会额外训练一个全局模型(Top Model),此模型用于整合各个参与方提取的特征,根据整合的特征信息匹配对应的标签 y,实现损失最小化;
但是在前面的文章中没有涉及 FATE 如何将不同参与方的构建的模型进行整合,以及各个独立的本地模型(Bottom Model)如何获取到对应的梯度进行反向更新。本文就针对详细的模型设计与更新机制进行介绍,为了避免内容过于复杂,不涉及 FATE 模型安全性机制,这个后续再介绍。
模型结构
FATE 纵向联邦神经网络详细的模型设计在 FATE 官方文档 可以看到,具体如下所示:
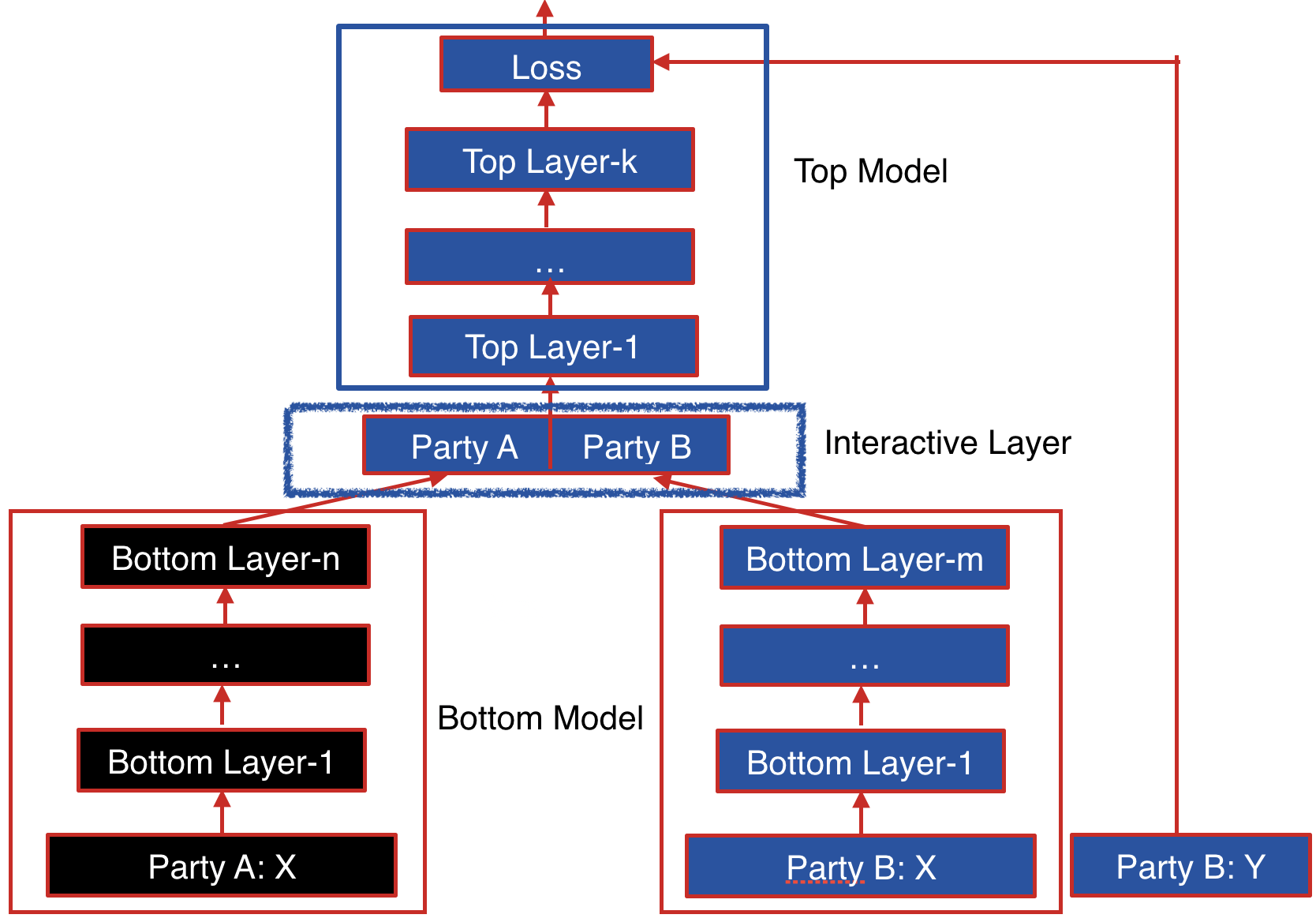
下面对图中参与方角色信息进行介绍:
- 左下角 Party A 代表的是 Host 参与方,此参与方没有标签信息(y),因此只训练了一个本地模型 (Bottom Model),模型的输出作为全局模型(Top Model)的输入,Host 参与方实际中可以存在多个;
- Party B 代表的是 Guest 参与方,此参与方包含标签信息(y),因此包含了本地模型(Bottom Model)和全局模型(Top Model)。Guest 参与方如果没有可供提取特征的数据,本地模型(Bottom Model)可以不存在,Guest 参与方只会存在一个;
接着了解下具体的模型,各个参与方的本地模型(Bottom Model) 与 全局模型(Top Model) 都是根据配置信息生成的,可以完全自定义,可以理解为常规的神经网络模型。而让所有模型能顺利运转的核心就是中间的 Interactive Layer (交互层)
交互层(Interactive Layer)
交互层在整个模型中承担着类似胶水的职责,其输入为各个参与方本地模型(Bottom Model)的输出,其输出为全局模型(Top Model)的输入。主要设计两个核心的任务:
- 执行必要的 shape 转换,因为各个参与方的数据与本地模型都是不同的,因此最终的输出很可能也是不同的,为了保证全局模型能正确处理,需要转换为全局模型可以处理的 shape,即进行矩阵维度的转换;
- 合并各个参与方本地模型输出的数据,因为全局模型只有一个,不可能处理多个输入,因此多个输入需要合并;
FATE 的交互层最终实现如下所示:
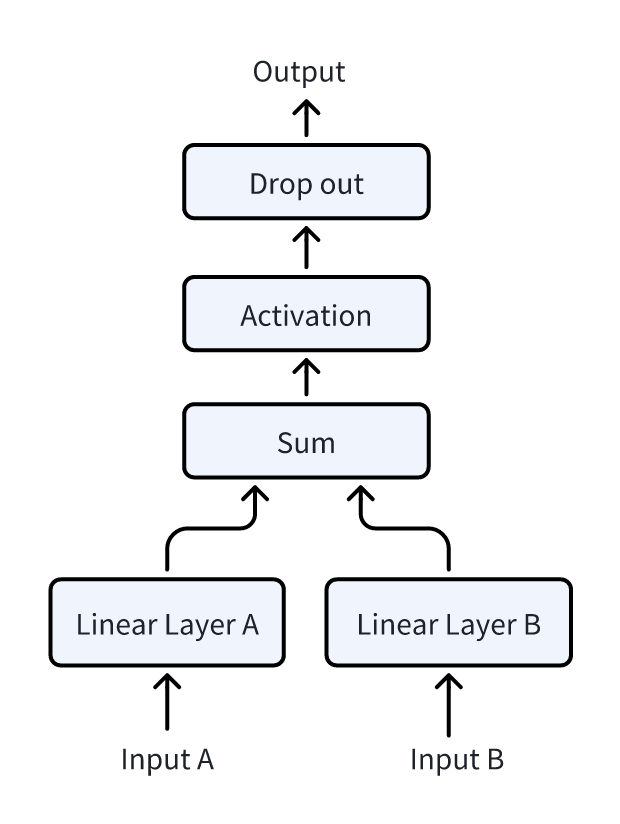
下面解释下交互层中各层的情况:
- 本地模型(Bottom Model)会对应一个全连接层(Linear Layer),此全连接层可以本地模型的输出转换为全局模型(Top Model)可以处理的 shape;
- 经过全连接层转换后的输出会被直接相加,从而实现各方特征信息的合并;
- 接下来对合并的数据额外处理,先经过自定义的激活函数进行转换,然后经过 Drop out 的处理,得到是输出就可以作为全局模型(Top Model)的输入了;
交互层模型训练实现细节
前向传播
前向传播的过程相对简单,基本上就是对上面过程的完整复现,主要需要注意的是 shape 的选择,对应的实现在 python/federatedml/nn/hetero/interactive/he_interactive_layer.py 中的 HEInteractiveLayerGuest.forward() 方法中。简化后的版本如下所示:
# 输入 x 为 Guest 本地模型的输出,与 Host 本地的模型的输出进行合并作为全局模型的输入
def forward(self, x, epoch: int, batch: int, train: bool = True, **kwargs):
# 构建 self.guest_model 为 guest 对应的全连接层,在 host_model_list 中为各个 Host 构建一个全连接层
if self.guest_model is None:
self._build_model()
# 通过全连接层 self.guest_model 对 guest 本地模型的输出进行转换,保证 shape 对齐
guest_output = self.guest_model(x)
# 获取 Host 本地模型输出, 将 Host 本地模型前向传播结果直接求和
host_output = self.forward_interactive(
host_bottom_inputs_tensor, epoch, batch, train)
# 将 Guest 本地模型输出与 Host 本地模型的输出合并, 直接取和
if guest_output is not None:
dense_output_data = host_output + PaillierTensor(guest_output, partitions=self.partitions)
else:
dense_output_data = host_output
# 通过激活函数进行前向传播结果的处理
activation_out = self.activation_forward(
dense_out, with_grad=with_grad)
# 执行 Drop out 算法
if train and self.drop_out:
return self.drop_out.forward(activation_out)
return activation_out
可以看到实现与描述基本一致,此方法是在 Guest 参与方上执行的,输入 x 为 Guest 本地模型的输出,通过封装的远程调用获取各个 Host 参与方上本地模型的输出,然后通过各自的全连接层进行处理,之后直接加和,通过激活函数和 Drop out 处理后就可以提供给全局模型了
反向传播梯度分发
反向传播是从后往前进行更新的,因此交互层的输入为全局模型(Top Model)训练获得的反向传播的梯度,交互层的输出是各个本地模型反向传播的梯度,因此交互层在反向传播中需要承担下面的职责:
- 根据全局模型反向传播的梯度更新交互层自身的参数,特别是多个全连接层的参数;
- 需要确定各个参与方本地模型反向传播的梯度,并发送给各个参与方用于更新模型;
最核心的点在于如何确定各个参数对应的梯度,下面就着重介绍相关内容。
前面提到交互层通过全连接层进行转换,此全连接层使用的线性转换,对应的公式如下所示:
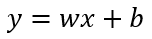
在上面的公式中,x 对应的就是本地模型(Bottom Model)的输出, 此时作为全连接层的输入, w 对应的就是线性函数中的权重,b 对应的就是偏置项。而 y 对应的就是全连接层对应的输出。
在交互层的设计中提到,各方全连接的输出会直接加起来,在两个参与方情况下对应的公式如下所示:
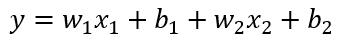
中间激活函数与 Drop out 只是简单的转换关系,在计算梯度时只需要反向传递即可,为了描述简单先忽略,将全局模型 (Top Model) 的转换定义为 f(y),最终的输出可以描述如下:
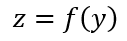
接下来考虑全连接各个参数的梯度的计算过程,在全局模型训练时可以获得全局模型输入对应的梯度 ∂z/∂y,之后就可以根据链式法则确定各个参数对应的梯度。对应的公式如下所示:
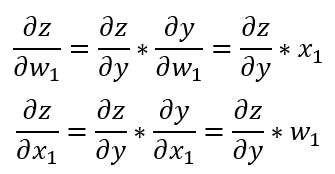
因此需要获得参与方本地模型对应的梯度 ∂z/∂x,只需要将全连接层输出对应的梯度 ∂z/∂y 乘上参与方对应的 w 即可。
同理为了获得全连接层 w 参数对应的反向传播的梯度 ∂z/∂w ,只需要将全连接层输出对应的梯度 ∂z/∂y 乘上参与方本地模型对应的输出 x 即可。
我们可以查看 FATE 中反向传播更新交互层参数对应的实现进行必要印证,具体是 python/federatedml/nn/hetero/interactive/he_interactive_layer.py 中的 HEInteractiveLayerGuest.backward() 方法实现,具体的代码如下所示:
def backward(self, error, epoch: int, batch: int, selective_ids=None):
if len(error) > 0:
if not self.do_backward_select_strategy:
# 执行激活函数的反向传播
activation_gradient = self.activation_backward(error)
else:
act_input = self.host_model_list[0].get_selective_activation_input(
)
_ = self.activation_forward(torch.from_numpy(act_input), True)
# 执行激活函数的反向传播
activation_gradient = self.activation_backward(error)
# 执行 Drop out 反向传播,得到全连接层输出反向传播的梯度
if self.drop_out:
activation_gradient = self.drop_out.backward(
activation_gradient)
# 更新 Guest 全连接层模型,返回 Guest 本地模型对应的梯度
guest_input_gradient = self.update_guest(activation_gradient)
# 更新 Host 全连接层对应的参数,获取 Host 本地模型反向传播的梯度,并发送给 Host 服务
for idx, host_model in enumerate(self.host_model_list):
host_weight_gradient, acc_noise = self.backward_interactive(
host_model, activation_gradient, epoch, batch, host_idx=idx)
host_input_gradient = self.update_host(
host_model, activation_gradient, host_weight_gradient, acc_noise)
# 将 Host 反向传播的梯度发送给对应的 Host
self.send_host_backward_to_host(
host_input_gradient.get_obj(), epoch, batch, idx=idx)
return guest_input_gradient
else:
return []
在上面的方法中,输入 error 对应的就是全局模型(Top Model) 反向传播的梯度,通过激活函数与 Drop out 方法的反向传播后得到全连接层输出反向传播的梯度,此时对应与上面公式中的 ∂z/∂y。
事实上 Guest 与 Host 本地模型的参数获取与全连接层的参数更新机制原理上是完全一样的,但是 Host 使用了额外的安全机制,因此会有略微的差异,本次以 Guest 本地模型对应的全连接为例进行介绍。
Guest 本地模型对应的全连接层对应的参数更新是通过调用 self.update_guest() 实现的,我们可以进一步了解相关实现:
def update_guest(self, activation_gradient):
# 获取 Guest 本地模型反向传播的梯度
input_gradient = self.guest_model.get_input_gradient(
activation_gradient)
# 获取 Host 全连接层 y = wx + b 中 w 反向传播对应的梯度
weight_gradient = self.guest_model.get_weight_gradient(
activation_gradient)
# 根据 Host 全连接层 w 对应的梯度更新参数
self.guest_model.update_weight(weight_gradient)
# 获取 Host 全连接层 b 对应的梯度并更新对应的参数
self.guest_model.update_bias(activation_gradient)
return input_gradient
方法 update_guest() 对应的输入 activation_gradient 为全连接层输出反向传播的梯度,即上面公式中对应的 ∂z/∂y,基于上面的实现预期 Guest 本地模型反向传播的梯度 ∂z/∂x 应该为 ∂z/∂y * w,我们可以查看对应的实现 get_input_gradient() 如下:
def get_input_gradient(self, delta):
error = np.matmul(delta, self.model_weight.T)
return error
实际代码中 model_weight 对应的就是全连接参数中对应的 w。
同样的到底可以查看 Guest 全连接层中 y = wx + b 中 w 对应的反向传播的梯度 ∂z/∂w 应该为 ∂z/∂y * x,对应的实现 get_weight_gradient() 如下所示:
def get_weight_gradient(self, delta):
delta_w = np.matmul(delta.T, self.input)
return delta_w
而实际代码中的 input 就是 Guest 本地模型对应的输出 x,也是符合预期的。
总结
通过上面的介绍,可以看到 FATE 纵向联邦神经网络的模型实现的完整细节,从中也能了解到如何将分散的多个多个小模型合并为一个完整的模型。从目前来看,FATE 的设计方案有如下的优点:
- 各个参与方可以根据数据需要设计自己所需的模型,利用交互层将模型 shape 进行转换,使用比较灵活;
- 全连接层转换之后将结果直接求和,反向传播的梯度计算相对比较简单,实现更容易;
如果对比 FATE 官方文档 对应的流程实现,可能会发现官方文档的描述的流程相对本文复杂不少,原因是因为本文忽略了因为安全机制而引入的复杂性,这一块后续再额外介绍。