纵向联邦学习
在之前的文章 联邦学习下线性回归算法实现概述 与 深入探索联邦学习框架 Flower 中,主要介绍的都是横向联邦学习的实践。最近针对纵向联邦做了一些探索,整理相关内容在这边。
横向联邦是 Google 在 2016 年提出的,主要解决拥有类似数据的多方进行联合训练的问题。而纵向联邦是 2018 年杨强教授提出的,主要解决跨行业的企业之间联合进行模型训练的问题。比如淘宝与银行之间,数据的特征重叠较少,但是重复用户较多的情况。针对两者的差异论文中有一个比较容易理解图示:
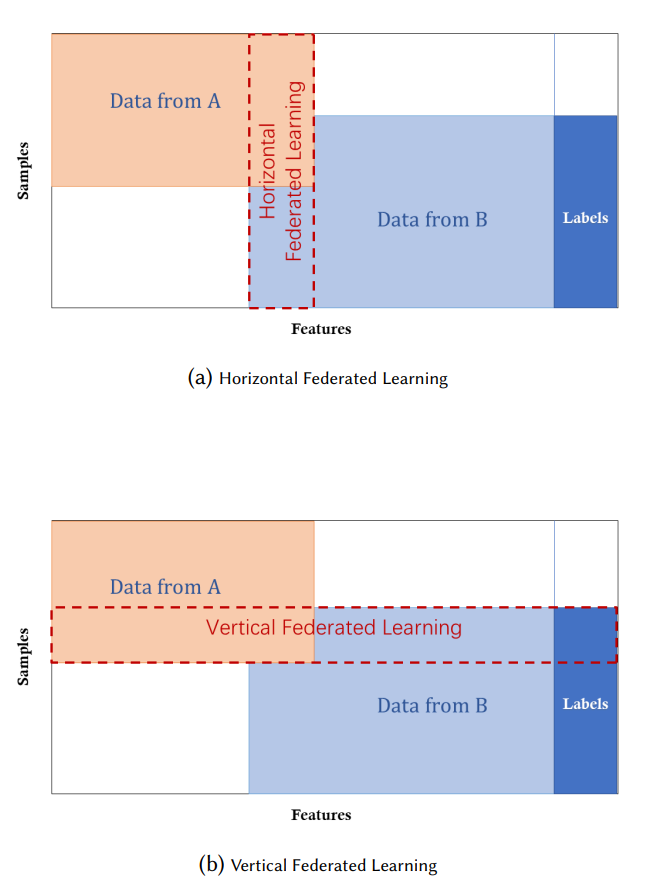
上面图示中下面这张图对应的就是纵向联邦,中间红色区域对应的就是重叠的用户数据。这种情况下可以通过联合训练充分利用两方的特征,从而训练出更好的机器学习模型。
纵向联邦训练流程
纵向联邦学习的常规模型训练流程如下所示:
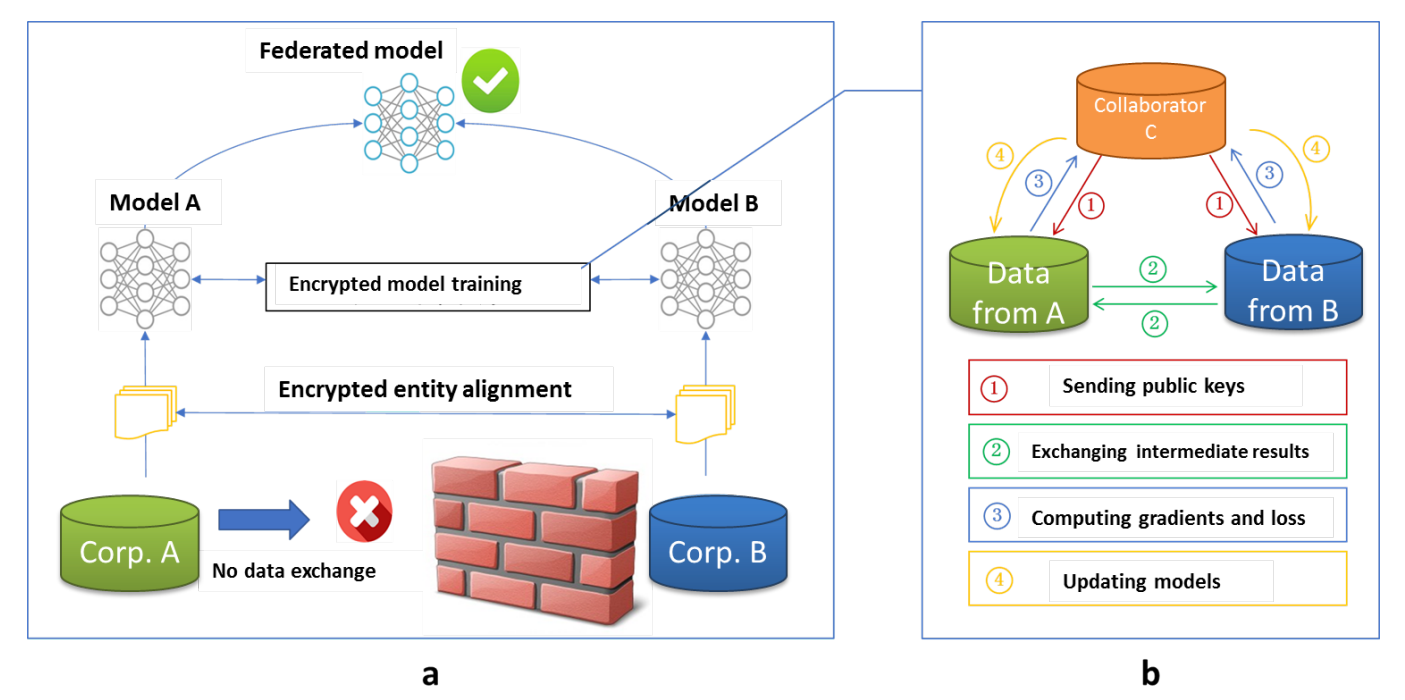
核心的步骤如下:
- 加密样本对齐,只有两方都存在的样本才能被纳入进行联合训练,因此需要确定这部分交集样本;
-
两方联合进行模型训练,这个阶段一般情况下会包含如下所示的步骤:
- 协作方 C 向数据所有方分发公钥,用于加密传输数据;
- 数据拥有方 A 和 B 基于自己数据的特征进行模型训练,并交换中间结果,用于计算各自的梯度和损失;
- 数据拥有方 A 和 B 将加密的梯度并添加掩码发送给 C,拥有标签的一方计算出损失后发送给 C;
- C 解密梯度和损失后回传给 A、B,A、B去除掩码后更新各方的模型;
但是要注意这个只是最初论文提出的纵向联邦学习的步骤,实际的纵向联邦会存在一些差异。比如实际工业界的实现中比较难找到合适的协作方,可能会使用没有协作方的方案,比如下面的 FATE 实现的纵向联邦神经网络就没有使用协作方。
在纵向联邦的模型训练中,与横向联邦有一个最明显的区别,就是只有一个参与方存在标签 y,因此部分没有标签的一方是无法独立完成的模型的完整训练流程的,必须借助存在标签的参与方确定损失与梯度,然后才能完整反向传播更新模型。
同时要注意,因为实际的目标是通过使用各个参与方的特征训练出来的,而各个参与方只有与自己的特征相关的模型,因此纵向联邦中需要联合多方才能完成模型推理。
FATE 纵向联邦探索
FATE 纵向联邦支持了不少算法,在 examples/dsl/v2 目录下可以看到以 hetero 开头的就是纵向联邦学习算法,本次我们选择的就是 hetero_nn 算法,实现的纵向联邦神经网络算法。
我们可以查看算法执行时提交的任务文件,文件在 examples/dsl/v2/hetero_nn/hetero_nn_train_binary_dsl.json 目录下,从文件中可以看到算法涉及的组件,更容易理解算法的实现。文件内容如下所示:
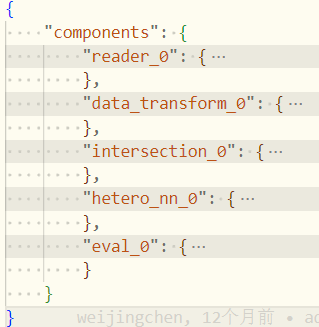
可以看到 FATE 中的纵向联邦神经网络训练任务会包含如下所示的步骤:
- 数据读取(reader_0);
- 数据转换(data_transform_0);
- 隐私集合求交,即加密样本对齐(intersection_0);
- 纵向联邦神经网络(hetero_nn_0);
- 模型验证(eval_0);
可以看到其中最核心的就是步骤3、4, 本次主要关心的是多方如何进行纵向联邦训练的流程,因此主要关注步骤 4,而步骤 4 对应的组件为 HeteroNN,此组件的对应的实现主要在 python/federatedml/components/hetero_nn.py 中实现,接下来就深入探索这部分内容。
在纵向联邦中需要特别注意参与方是否存在标签,在 FATE 中使用不同的角色进行区分,其中 Guest 是指存在标签的参与方,而 Host 是指不存在标签的参与方
FATE HeteroNN 实现
FATE HeteroNN 流程概述
FATE HeteroNN 实现的方案与前面介绍的常规纵向联邦的实现方案存在一些差异,在 FATE HeteroNN 中没有使用额外的协作方,仅仅包含了两种类型的参与方 Guest 与 Host,训练的流程如下所示:
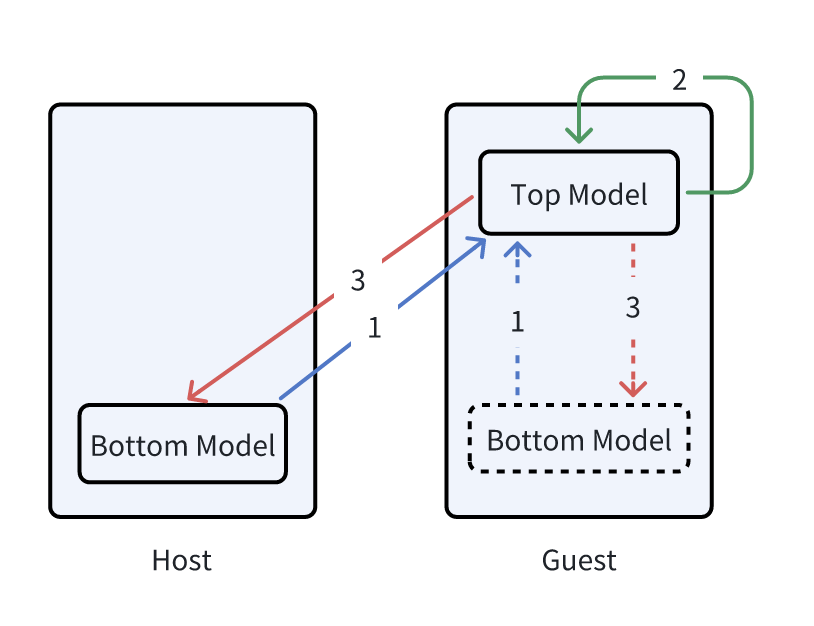
具体的步骤如下所示:
- Host 与 Guest 各自基于本地已有的特征训练使用本地模型 Bottom Model 进行前向推理获得模型的输出,并将模型前向推理的结果发送给 Guest;
- Guest 将收到的多个 Bottom Model 的前向推理的输出进行合并,并将合并的数据作为 Top Model 的输入,使用 Guest 上的标签作为预期输出,训练后得到对应的损失与梯度,然后计算获得各个 Bottom Model 对应的损失与梯度;
- Guest 将损失与梯度分别发送给对应的 Bottom Model,各个 Bottom Model 基于收到的梯度进行模型的更新;
在实际中 Host 会存在本地模型 Bottom Model,而 Guest 服务上如果存在可用的数据则会构造一个对应的本地模型 Bottom Model,如果没有也可以不构建 Bottom Model,但 Guest 服务上必然会构建一个全局模型 Top Model,此模型的输出会对应于标签,并基于 Guest 中的标签确定损失与梯度。
FATE HeteroNNHost 源码实现
HeteroNNHost 类位于 python/federatedml/nn/hetero/host.py 中,主要实现纵向联邦中 Host 服务所需的方法。涉及到模型训练的主要流程都实现在 fit() 方法中,具体的代码如下所示:
def fit(self, data_inst, validate_data=None):
# 构造训练集与验证集
train_ds = self.prepare_dataset(data_inst, data_type='train')
if validate_data is not None:
val_ds = self.prepare_dataset(validate_data, data_type='validate')
else:
val_ds = None
for cur_epoch in range(epoch_offset, epoch_offset + self.epochs):
self.iter_epoch = cur_epoch
for batch_idx, batch_data in enumerate(DataLoader(train_ds, batch_size=batch_size)):
# 实际的模型训练
self.model.train(batch_data, cur_epoch, batch_idx)
可以数据集的构造与模型的训练类似常规 pytorch 的流程,而实际的是调用 model.train() 完成的,此方法位于 python/federatedml/nn/hetero/model.py 中的 HeteroNNHostModel 类中,具体的实现如下:
def train(self, x, epoch, batch_idx):
if self.bottom_model is None:
# 构造 Host 本地模型,会基于模型定义 dict 构造出一个 pytorch 神经网络模型
self._build_bottom_model()
# 用于构造交互 model,用于与 Guest 传输数据,内部包含使用同态加密
self._build_interactive_model()
self.bottom_model.train_mode(True)
# Host 本地模型前向传播得到输出
host_bottom_output = self.bottom_model.forward(x)
# Host 将本地模型前向传播结果加密后传递给 Guest
self.interactive_model.forward(
host_bottom_output, epoch, batch_idx, train=True)
# Host 从 Guest 获取反向传播的梯度
host_gradient, selective_ids = self.interactive_model.backward(
epoch, batch_idx)
# 根据反向传播的梯度更新本地模型
self.bottom_model.backward(x, host_gradient, selective_ids)
可以看到训练流程封装后提供了类似的 pytorch 模型训练的效果,但是在交互类 self.interactive_model 中封装了复杂的传输与加密过程。
FATE HeteroNNGuest 源码实现
HeteroNNGuest 类位于 python/federatedml/nn/hetero/guest.py 中,主要用于实现纵向联邦中 Guest 服务所需的方法。涉及到的模型训练同样位于方法 fit() 中,具体如下所示:
def fit(self, data_inst, validate_data=None):
# 构造训练数据集与验证数据集
train_ds = self.prepare_dataset(
data_inst, data_type='train', check_label=True)
train_ds.train()
if validate_data is not None:
val_ds = self.prepare_dataset(validate_data, data_type='validate')
val_ds.train()
else:
val_ds = None
# 构造训练 dataloader
data_loader = DataLoader(
train_ds,
batch_size=batch_size,
num_workers=4)
for cur_epoch in range(epoch_offset, self.epochs + epoch_offset):
epoch_loss = 0
acc_sample_num = 0
for batch_idx, (batch_data, batch_label) in enumerate(data_loader):
# 实际的模型训练
batch_loss = self.model.train(
batch_data, batch_label, cur_epoch, batch_idx)
# 根据 batch 的损失构造出模型训练的整体的损失
if acc_sample_num + batch_size > len(train_ds):
batch_len = len(train_ds) - acc_sample_num
else:
batch_len = batch_size
acc_sample_num += batch_size
epoch_loss += batch_loss * batch_len
epoch_loss = epoch_loss / len(train_ds)
可以看到训练的流程看起来依旧比较类似,与 Host 服务的一个主要区别是会存在 loss 的处理,主要原因是 Guest 中才存在标签 y,因此可以确定对应的训练 loss。
实际的训练是通过调用 model.train() 完成的,此方法位于 python/federatedml/nn/hetero/model.py 中的 HeteroNNGuestModel 类中,具体的实现如下:
def train(self, x, y, epoch, batch_idx):
# 构造全局模型,内部是一个封装的 pytorch 神经网络模型
if self.top_model is None:
self._build_top_model()
# 构造本地模型,如果 Guest 没有数据,可以不构造本地模型
if not self.is_empty:
if self.bottom_model is None:
self._build_bottom_model()
self.bottom_model.train_mode(True)
# Guest 本地模型前向传播生成对应输出,这部分与 Host 本地模型基本一样
guest_bottom_output = self.bottom_model.forward(x)
else:
guest_bottom_output = None
# 构造交互 model,用于与 Host 之间传输数据
if self.interactive_model is None:
self._build_interactive_model()
# 将 Guest 本地模型输出与 Host 本地模型的输出合并,并通过激活函数进行处理,生成新的输出
interactive_output = self.interactive_model.forward(
x=guest_bottom_output, epoch=epoch, batch=batch_idx, train=True)
self.top_model.train_mode(True)
# 使用本地模型输出联合构造出的输出作为全局模型的输入,生成对应的梯度与损失
selective_ids, gradients, loss = self.top_model.train_and_get_backward_gradient(
interactive_output, y)
# 内部封装将 Host 对应的梯度传递给 Host,并返回 Guest Bottom model 反向传播的梯度
interactive_layer_backward = self.interactive_model.backward(
error=gradients, epoch=epoch, batch=batch_idx, selective_ids=selective_ids)
if not self.is_empty:
# 基于 Guest 全局模型反向传播的梯度更新 Guest 本地模型 Bottom model
self.bottom_model.backward(
x, interactive_layer_backward, selective_ids)
return loss
可以看到对应的实现就是基于 Guest 与 Host 中的本地模型 Bottom Model 分别完成各自的特征提取,然后通过 Top Model 执行必要的转换从而匹配到对应的标签,整体还是比较容易理解的。模型的训练过程基本就是前向传播获得输出,反向传播更新模型。核心还在于如何完成梯度的加密与分发,这部分后续再单独梳理。
总结
通过上面的介绍,可以看到 FATE 中如何实现纵向联邦学习神经网络,从整体的实现流程来看,FATE 将纵向联邦学习中存在数据的各方训练出一个局部小神经网络模型,利用这个神经网络模型完成对应特征的提取。然后利用全局模型将所有小模型组合起来,从而从而实现多个局部模型 + 单个全局模型组装成一个完整神经网络模型。此模型可以充分利用各个参与方中存在的特征,从而实现更好的预测效果。