独立同分布
独立同分布概念
众所周知,在机器学习进行模型训练时,基本上都假设训练样本符合独立同分布(IID)。
- 独立,表示多个抽样样本之间没有相关关系,彼此不会互相影响。比如掷骰子中前后两次互不影响,
- 同分布,表示多个样本遵循同样的分布规律。比如掷骰子中多次都符合同样的规律,即每个数出现的概率都为 1/6
因为机器学习都是通过学习历史数据总结出规律从而预测未来数据的,如果历史数据不符合同分布,那么机器学习就学习不到对应的规律。如果历史数据是互相关联的,可能会导致机器学习学会的都是无法泛化的规律,在未来做出针对个例的预测时,表现就不好。
独立同分布问题
在常规的机器学习中,不符合独立同分布 (Non-IID) 的情况也可能会存在,但是相对容易解决,因为机器学习中可以获得完整的训练样本,在训练前会被随机打乱,常规情况下可以认为数据就是符合 IID 了。
但是在联邦学习中这个问题就会更加明显,因为在联邦学习中单个参与方只能获得有限的数据集,各方的数据集的差异可能会比较大,从而导致各个参与方训练出来的模型差异很大,最终通过 FedAvg 进行聚合时效果不佳。类似如下所示的效果图:
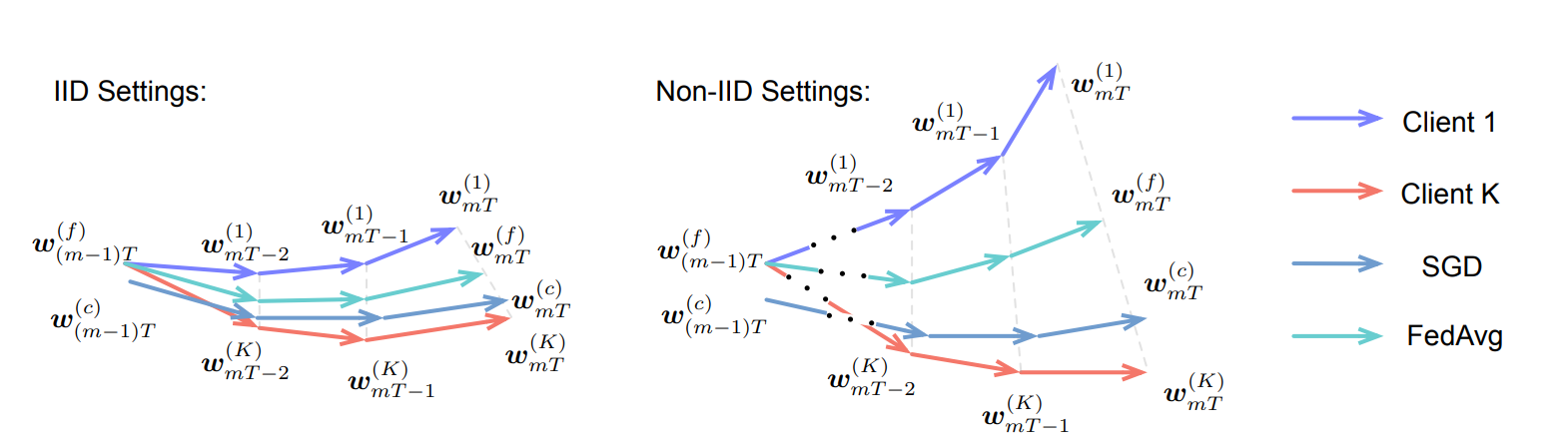
在联邦学习算法中为了解决 Non-IID 的问题,存在着不同的解决方案,在这篇文章中主要介绍基于数据共享的解决方案 FedShare 与 FedMeta,相对容易理解,后续在此基础上进行进一步迭代。
FedShare 算法
Fedshare 是源自 2018 年的论文 Federated Learning with Non-IID Data, 在 CIFAR-10 数据集上通过共享 5% 的数据集实现了 30% 的准确性提升。其步骤如下:
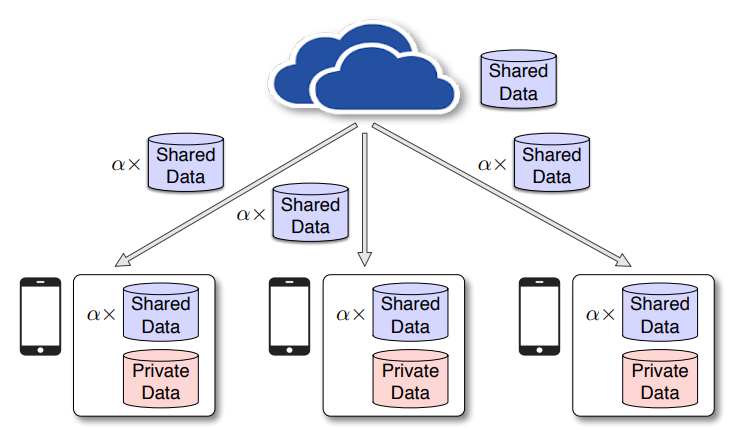
- 各个参与方 Worker 共享一定比例的脱敏数据作为公共数据集发送给 Arbiter,对应的比例定义为 β;
- Arbiter 将收到公共数据集合并为完整的公共数据集,将公共数据集中的一部分数据下发给各个参与方 Worker,对应的比例定义为 α,Worker 将自己原有的数据集与收到的公共数据集进行合并得到训练数据集;
- Arbiter 基于完整的公共数据集训练出初始模型权重下发给 Worker,Worker 基于此模型权重初始化模型,后续在此基础上进行训练;
- Worker 基于本地数据集训练出本地模型权重,传递给 Arbiter,Arbiter 聚合后下发给 Worker,重复执行此步骤直到训练出合适的模型;
关于 Worker 与 Arbiter 属于联邦学习的角色,具体的解释可以参考 联邦学习下线性回归算法实现概述
FedShare 实现
from torch.utils import data as torch_data
class FedShareWorker(object):
def init_dataset(self):
# β 比例的数据分享作为公共数据集
self.train_dataset, self.share_beta_dataset = torch_data.random_split(self.train_dataset, self.beta)
# 将 Worker 中公共数据集传递给 Arbiter
self.arbiter.receive_share_dfs(self.share_beta_dataset)
# 将 Arbite 中 α 比例的数据集与本地训练数据集合并生成完整的训练数据集
def get_share_and_join_dataset(self):
self.share_alpha_dataset = self.arbiter.send_share_data_to_worker()
self.train_dataset = torch_data.ConcatDataset([self.train_dataset, self.share_alpha_dataset])
self.train_dataloader = torch_data.DataLoader(self.train_dataset, batch_size=self.conf.batch_size, shuffle=True)
# 获取模型参数
def get_model_params(self):
params = self.arbiter.send_model_params()
self.model.load_state_dict(params)
# Worker 本地训练模型
def train_local_model(self, ):
for i in range(self.epochs):
for x, y in self.train_dataloader:
pred_y = self.model(x)
loss = self.loss(pred_y, y, self.model)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 发送模型权重给 Arbiter
def send_model_params_to_arbiter(self):
state_dict = self.model.state_dict()
self.arbiter.receive_model_params(state_dict)
class FedShareArbiter(object):
def __init__(self) -> None:
self.share_datasets = []
self.worker_model_params = []
# 接收共享数据集
def receive_share_dfs(self, share_dataset):
self.share_datasets.append(share_dataset)
# 聚合接收到的数据集,合并为公共数据集
def join_share_datasets(self):
full_dataset = torch_data.ConcatDataset(self.share_datasets)
self.train_loader = torch_data.DataLoader(full_dataset, batch_size=self.conf.batch_size, shuffle=True)
# α 比例的数据集切分,这部分数据集传递给 Worker
self.share_alpha_dataset, _ = torch_data.random_split(full_dataset, self.alpha)
# 将 α 比例的数据集传递给 Worker
def send_share_data_to_worker(self):
return self.share_alpha_dataset
# 基于公共数据集训练出初始模型权重
def train_server_model(self):
for x, y in self.train_loader:
pred_y = self.model(x)
loss = self.loss(pred_y, y, self.model)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.model_params = self.model.state_dict()
# 将模型权重发送给 Worker
def send_model_params(self):
return self.model_params
# 接收 Worker 发送的模型权重
def receive_model_params(self, model_params):
self.worker_model_params.append(model_params)
# 聚合 Worker 模型权重
def compute_param_mean(self):
keys = self.worker_model_params[0].keys()
avg_para = {}
for para in self.worker_model_params:
for key in keys:
avg_para[key] = avg_para.get(key, 0) + para.get(key, 0)
for key in keys:
avg_para[key] = avg_para[key] / len(self.worker_model_params)
self.model_params = avg_para
self.worker_model_params = []
def train_loop(workers: list[FedShareWorker], arbiter: FedShareArbiter, max_iter: int):
# Worker 数据集初始化,切分 β 比例数据集传递给 Arbiter
for worker in workers:
worker.init_dataset()
# 合并 Worker 传递的数据,切分 α 比例的公共数据集给各个 Worker
arbiter.join_share_datasets()
# 将自身数据集与 Arbiter 传递的数据集合并,构造 Worker 最终的训练数据集
for worker in workers:
worker.get_share_and_join_dataset()
# Arbiter 基于数据集生成初始的模型权重
arbiter.train_server_model()
# Worker 从 Arbier 中获取初始模型权重
for worker in workers:
worker.get_model_params()
for iter in range(max_iter):
# 基于 Worker 数据集进行模型训练
for worker in workers:
worker.train_local_model()
# Worker 将模型权重发送给 Arbiter 服务
for worker in workers:
worker.send_model_params_to_arbiter()
# Arbiter 聚合模型权重
arbiter.compute_param_mean()
# Worker 从 Arbiter 中获取聚合后的模型权重,更新本地的模型权重
for worker in workers:
worker.get_model_params()
在上面的实现中 train_loop() 是实际的训练流程,FedShareWorker 是 Worker 服务实现的方法,FedShareArbiter 是 Arbiter 服务实现的方法。
在实际的业务中,FedShareWorker 和 FedShareArbiter 会继承自基础类,将方法的调用隐式转换为 gRPC 网络请求调用,这样才能实现真正实用的联邦学习调用。
FedMeta 算法
FedMeta 是源自 2019 年的论文 Federated Learning with Unbiased Gradient Aggregation and Controllable Meta Updating,其主要步骤如下:
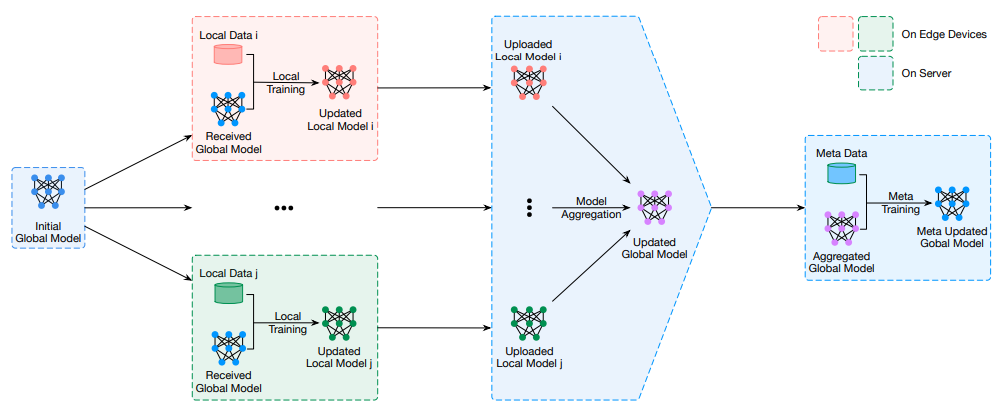
- 各个参与方 Worker 共享部分脱敏数据作为训练数据集发送给 Arbiter;
- Arbiter 合并 Worker 发送的训练数据集,作为元训练集(meta training set) 用于后续的模型训练;
- Worker 训练出本地模型,论文中引入无偏梯度聚合方案(Unbiased Gradient Aggregation) 用于模型训练;
- Worker 传递训练的模型权重给 Arbiter,Arbiter 进行聚合,并对训练后模型使用元训练集进行训练,并将训练后生成的模型权重下发给 Worker,重复步骤 3, 4 直到训练出合适的模型;
可以看到主流程与 FedAvg 基本上是一样的,主要的变化在于 Arbiter 在每轮模型聚合后使用元训练集进行额外的模型训练,因此效果更好。
总结
本文主要介绍了联邦学习中两个解决 Non-IID 的算法,因为都是基于共享数据的思路去解决问题的,因此整体的流程与思路比较接近,但是从实际来看,基于共享数据的算法虽然可以有效地解决 Non-IID,但是可能会导致数据泄露的风险更高。一定程度上也违背了联邦学习中数据不出域的原则,因此应用场景比较有限,在参与方存在部分可共享的脱敏数据场景下可以考虑使用。