背景介绍
在之前的文章 Agent 落地分享一 和 Agent 落地分享二 中,深入探讨了 Agent 无法落地的诸多问题以及相应的解决方案。其中反复强调的核心问题是如何提升大模型产品的确定性——毕竟,没有人会为一个偶尔超常发挥但时不时”抽风”的产品买单。
如何提升大模型产品的确定性,是每一个大模型产品研发团队都需要面对的核心挑战。提升大模型产品的确定性涉及多个维度,本文将从结构化解析这一相对实用且关键的场景入手,分享我在最近 Agent 产品实践中的一些有效解决方案。
踩坑经历
最近在带队开发一款医疗领域的 Agent 产品,与之前的产品形态有很大差异,需要复杂的多 Agent 交互与迭代,原有的基础 Agent 框架灵活性不足,因此考虑基于全新的框架进行开发。
在对热门的多 Agent 框架 CrewAI、AutoGen、LangGraph、Agno、OpenAI Agents、Pydantic AI、MetaGPT 进行调研后,考虑到严肃医学场景对确定性的高要求,我们选择了相对轻量、上手门槛低且海外开发者大量推荐的 Pydantic AI 进行搭建。Pydantic AI 的结构化解析相对简单,对于本来就使用 Pydantic 的团队来说确实非常友好。从下面的简单例子就能看出 Pydantic AI 的简洁与易用。
from pydantic import BaseModel, Field
from pydantic_ai import Agent
class JudgeOutput(BaseModel):
score: float = Field(description="评分,范围 1-5", ge=1, le=5)
justification: str = Field(description="针对评分的详细解释与依据")
agent = Agent(
model=model_name,
system_prompt=build_system_prompt(),
result_type=JudgeOutput,
)
agent.run(prompt)
这个使用方式确实非常优雅,使用体验直追 Python 界优雅鼻祖 requests。当然,在此期间我们也基于 CrewAI 低成本搭建了一个版本,虽然开发速度很快,但灵活性太差,最终迅速放弃了。
在实际使用一段时间后我们发现,大模型的结构化输出稳定性确实令人担忧。在少量样本情况下测试效果还不错,但开启批量大规模测试时就发现出现了不少结构化解析失败的情况。我们尝试了 prompt 调优、增加 Few Shot、调整模型 temperature、增加重试次数等一系列措施,效果有所提升,但依旧不时出现解析失败。更令人头疼的是,在产品迭代过程中,可能因为产品中的小幅调整,结构化解析就会突然大量失败。
在迭代过程中,我们尝试了宝藏项目 BAML。从实际体验来看,结构化解析的效果相当稳定,而且对 prompt 的依赖很低,基本不需要开发人员胆战心惊地优化出一个完美的 prompt。后续的方案将重点介绍这个解决方案。
BAML
BAML 全称为 Basically a Made-up Language,通过自定义语法描述大模型调用的输入与输出,在大模型的协助下完成从输入到输出的可靠转换。
函数定义
有开发基础的都知道,从输入到输出的转换,一个最基础的抽象就是函数(function)。BAML 也采纳了这种思想,将所有的大模型调用都定义为函数,即 LLM Prompts are functions。理解了这个设计理念,BAML 后续的设计就很容易理解了。在实际的定义中,单个 prompt 调用定义如下所示:
class WeatherAPI {
city string
timeOfDay string
}
function UseTool(user_message: string) -> WeatherAPI {
client "openai-responses/gpt-5-mini"
prompt #"
Extract the data from user message
"#
}
上面的定义自解释性还是比较强的,开发者需要定义好函数的输入和输出,并在函数内部通过 client 定义使用的模型,通过 prompt 简单定义功能描述。掌握了 function 的使用,BAML 框架就掌握了一大半。
baml 文件
BAML 的所有功能定义都是预先定义在 .baml 文件中,之后 Baml Client 会将 .baml 文件转换为对应语言的可执行代码。熟悉 gRPC 的开发者应该很容易理解这种设计,通过自定义通用语法文件,实现跨语言的处理能力。
针对 .baml 到目标语言转换的复杂性,官方提供了简单易用的标准模板来降低上手门槛。下面以 Python 为例,介绍如何快速上手。
- 通过
pip install baml-py安装 BAML 依赖; - 通过
baml-cli init在baml_src目录下生成模板代码,后续可以直接在原始模板的基础上进行修改,补充需要的 function 即可; - 通过
baml-cli generate转换为 Python 代码,转换后的代码在baml_client目录下;
为了方便后续的快速编辑与开发,在 VSCode 或 Cursor 等编辑器上可以安装 baml 插件。
业务调用
因为 BAML 将所有的大模型调用都抽象定义为函数,后续也会通过 Baml Client 将其转换为函数调用代码,因此上层应用只需要将大模型调用作为一个函数调用即可。以上面的例子为例,实际的使用如下所示:
from baml_client.sync_client import b
from baml_client.types import WeatherAPI
def example(raw_msg: str) -> WeatherAPI:
response = b.UseTool(raw_msg)
return response
可以看到,实际调用也很简单,所有的格式化转换和异常处理都由 BAML 框架来完成,所需的开发工作量大幅降低。
优秀背后的秘密
实际测试发现 BAML 进行结构化解析的稳定性相对 Pydantic AI 有明显的优势,但我们需要了解为什么会出现这种差异,只有充分了解背后的原理才能安心使用此框架。
Pydantic AI 对结构化解析方案有具体解释,可以了解到 Pydantic AI 默认是基于大模型提供的 Tool Call 能力进行结构化提取,这种方案的通用性比较好,但结构化输出的稳定性与大模型本身的能力紧密相关。如果大模型自身的 Tool Call 能力支持不强,Pydantic AI 也会极其不稳定。
而 BAML 的结构化解析方案使用的是自研的 SAP (schema-aligned parsing) 算法实现,BAML 将大模型的输出与定义的 Schema 进行对齐,具备良好的容错能力,批量测试结果对比如下所示:
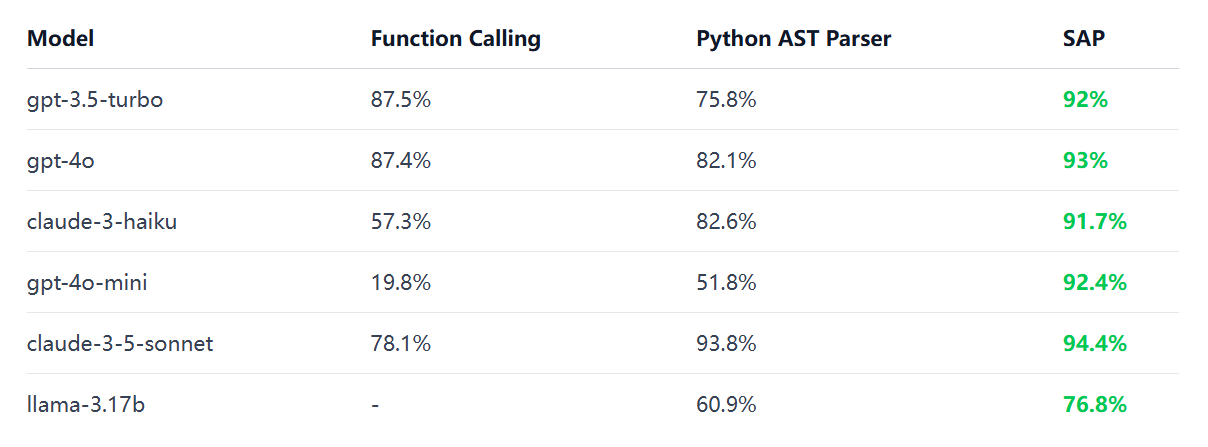
在文章 Prompting vs JSON Mode vs Function Calling vs Constrained Generation vs SAP 中详细解释了 SAP 的具体原理,其背后关键点是实现了一套高度容错的解析算法,其主要思想是 编辑距离,通过最小的编辑距离将原始无法解析的大模型输出转换为定义的 Schema 输出,类似 LeetCode 编辑距离 中的思想。具体的案例如下所示:

在此案例中,原始大模型输出与定义的 Schema 不一致,SAP 会执行必要的编辑,将 prior_jobs 输出的类型从字符串转换为列表,即可正确解析。

在此案例中,可供解析的输出 JSON 前后包含一些无关信息,SAP 会执行必要的编辑,将无关信息删除,即可正确解析。
目前 SAP 支持的错误修复包括如下所示:
- 不带引号的字符串
- 字符串中未转义的引号和换行符
- 缺少逗号
- 缺少冒号
- 缺少括号
- 错误命名的键
- 将分数转换为浮点数
- 删除对象中多余的键
- 删除无关内容
- 如果大模型产生多个结果,则从众多可能的结果中挑选最佳答案
- 修复对象不完整(由于流式传输)
总结
本文是对近期 Agent 探索中遇到的结构化解析问题的解决方案总结。可以看到,Agent 产品在落地过程中,由于大模型的不确定性导致存在不少问题,部分问题可以通过模型的不断迭代来解决,但实际中还是需要算法 + 工程手段结合进行解决。
在这个过程中,如何充分利用开源社区提供的优秀解决方案,尽可能避免重复造轮子,是每一个研发团队都需要面对的问题。同时也致敬开源社区这些提供优秀解决方案的团队与个人,正是他们的贡献让我们的开发工作变得更加高效。