背景介绍
过去几年,持续在医疗领域的大模型应用进行实践探索,个人在大模型技术专栏 中持续积累了近 60 篇相关技术博客。过往的实践中,尝试了RAG、Agent、模型微调、知识图谱等多种技术路线,医学通用场景下 RAG 的准确率已由最初的不足 50% 提升至 90% 左右。然而,医学作为高度严谨的应用场景,90% 的准确性依旧无法完全满足生产需求。
2025 年以来,进一步聚焦医学细分场景,尝试了不同的场景化大模型应用解决方案,部分方案在特定场景下取得了显著成效,真正满足了生产需求。本文结合过去的实践探索,总结若干大模型落地的心得体会,供大家参考。
通用方案的局限性
2024年,RAG 成为大模型应用领域的热点方向,但 2025 年以来技术创新趋于平缓,正如2025 RAG技术现状盘点所说的,RAG技术已进入瓶颈期。实践表明,依赖通用大模型技术方案比如 RAG 难以应对现实世界的复杂多样需求。
以医疗领域为例,通用 RAG 服务在实际应用中暴露出如下问题:
- 向量检索的精度问题:医学数据的复杂性决定了向量检索在处理细微差异时容易失灵。例如,在病例分析中,患者检查项的细微差异(如某项指标的轻微波动)可能导致完全不同的诊断方向。常规的向量检索基于语义相似性,往往无法精准捕捉这些细微但关键的差异。例如,在处理心电图数据时,ST 段抬高 0.1mV 与 0.2mV 的差异可能指向完全不同的心血管疾病,但通用向量模型可能将二者视为相近内容,导致误判;
- 分片检索的信息完整性问题:为适应模型上下文窗口限制,RAG 方案通常将长文档分片向量化处理。但在医学场景下,分片策略易导致信息不完整。例如,完整病历包含病史、检查结果、医嘱等多部分,分片检索常常只返回部分片段,丢失了上下文,影响医学推理的可靠性,甚至导致完全失去可用性;
- 应用场景的多样性:现实世界用户需求多样且分散,期望通过一个简单的相似性检索解决所有问题几乎是不可能的。为提升长尾问题的适配性,往往叠加大量“雕花”技巧,导致系统复杂性和维护成本上升,处理效率也会进一步下降;
场景化的解决方案
实践中我们逐步认识到,通用方案难以覆盖医疗的复杂性。唯有深入理解业务流程、锚定具体场景,才能设计出真正可行的技术路径。下面是一个具体的实例:
在医疗场景下,单纯依赖预训练大模型基本都无法满足生产需要,主要是因为幻觉问题、医学知识覆盖不足及知识的时效性限制,因此一般会需要外部知识库进行额外信息补充。一般情况下,RAG 是一个常规的选择。
但在实际应用中,通用的 RAG 可以满足部分场景,但是因为 RAG 自身的局限性,因此会存在不少的问题,比如检索准确性,检索信息不完整,指南文档提取困难等。为了解决 RAG 的问题,行业中存在不少的优化策略,在过去整理过不少的相关的优化手段,比如 RAG 最佳实践 和 2025补充策略 等。但是这些通用方案进行优化后,依旧存在不少问题,行业内甚至将单纯的 RAG 演化为复杂的 Agentic RAG,将单轮的检索演变为复杂的多轮检索。但是这依旧无法解决大量的长尾问题。很多团队就卡在这个阶段无法真正落地下来。
我们也在这个阶段经历过不少的折腾,最终我们发现,期望通用方案能解决所有的问题基本不现实。只有定义好明确的业务场景,针对具体的业务场景设计对应的方案,往往能发现真正有效的解决路径。
比如针对医学应用场景中病例与医学指南的匹配,如果期望借助向量能给出完全准确的医学指南知识往往会陷入无穷尽的匹配不准确长尾问题。基本上很难达到真正能严谨医学所需的准确性。
而我们实践发现,我们实际落地的医学应用场景针对的是有明确诊断病例的处理场景,此时有明确的疾病指向性。而医学指南知识多以疾病为单位组织。借助疾病名称进行知识匹配,可有效规避向量检索的模糊性。
当然,疾病名称匹配存在疾病别名导致的匹配率低的问题,此时可借助 ICD编码 进一步提升匹配范围和精度。因此疾病知识检索的方案最终演化为如下:
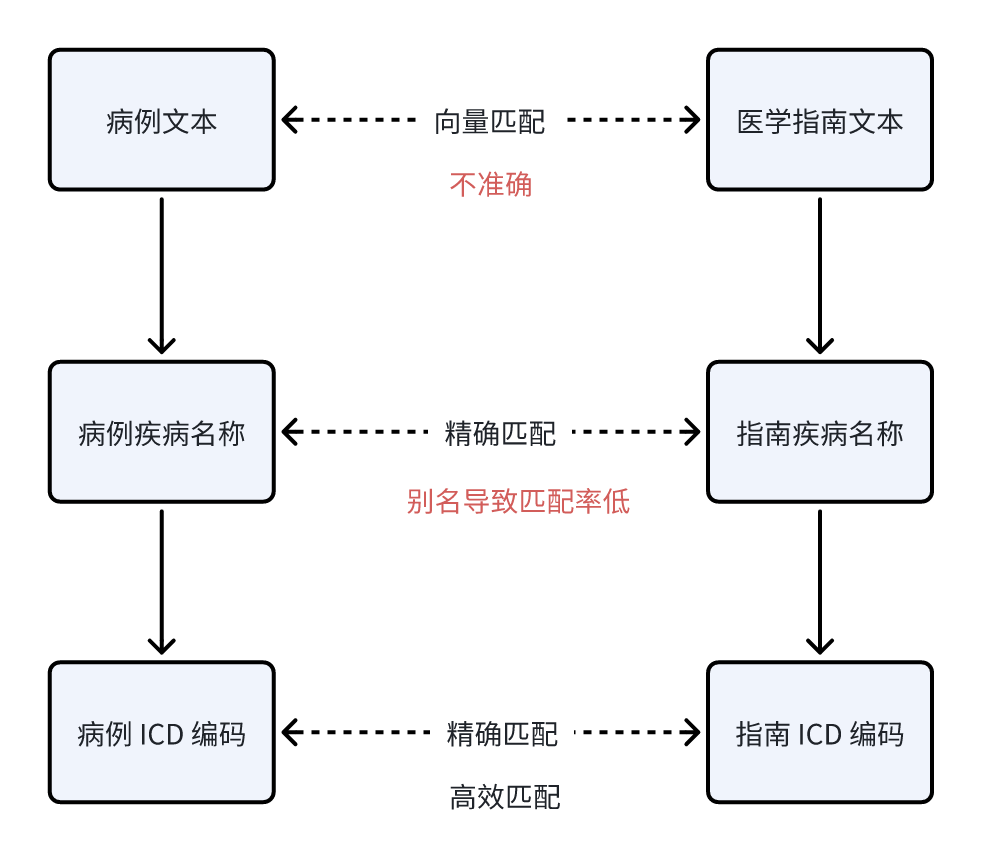
通过上述方法,能够显著提升疾病知识场景下的匹配准确性,实现从90%到100%的跨越。当然,这仅为医疗场景的一个典型案例,实际应用落地需要结合具体行业与业务属性,挖掘最优解。
数据飞轮驱动下的技术迭代
大模型应用落地不仅依赖合适的技术方案,更需完善的评估体系以支撑业务持续迭代。大模型应用多以文本输出为主,若无明确评估机制,人工很难确定优化的效果,而技术演进的长期可靠性难以保障。
基于数据飞轮驱动下策略在大模型领域并不罕见,目前行业普遍通过构建 BenchMark 进行评估。例如,向量模型有 mteb 榜单,大模型则有 lmarena 等多种榜单, 甚至针对医学垂直领域,也存在 MedBench 等医学榜单。
但是从我的实践经验来看,行业的通用榜单无法直接与具体的业务应用场景匹配上。因此建议结合自身业务场景构建专属评估集。而且建议在定义好大模型应用的应用场景时,就着手开始构建标准的评估数据集,在项目迭代的生命周期中,持续借助数据集验证大模型应用的当前水平,并借助批量测试的数据集发现异常 case,确定下一轮的优化点。循环迭代直到达到预期目标。
从我过往的实践来看,大模型应用技术迭代流程如下:
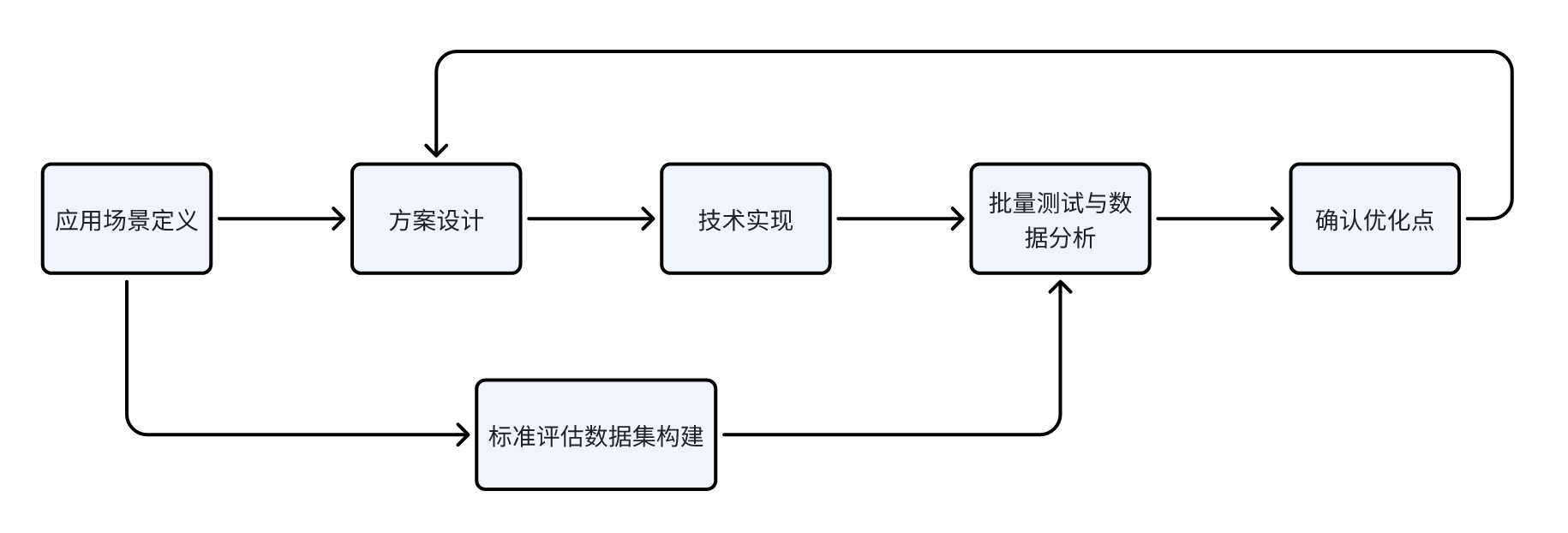
当然这也只是我个人的看法,是否准确还有待大家自行实践和验证。
总结
本文基于医学大模型应用落地的实践,总结了一些思考。虽然我指出了通用 RAG 方案的局限性,但 RAG 依然是知识检索领域极具价值的技术方向,我也还在进行相关探索。
但从我的实践经验来看,相对期望一招鲜解决所有的业务场景,不如先沉下来考虑清楚真实的应用场景,针对具体的行业与应用场景有针对性地构建适配方案,并以数据飞轮驱动持续产品迭代优化,才更容易打造出真正可落地的大模型产品。