背景介绍
我一直认为,大模型竞赛是检验方案有效性的宝贵试验场。以 RAG 实践为例,相关论文层出不穷,但真正落地且有效的策略却相对有限。竞赛则为各类方案提供了客观、公正的比拼环境,在合适的验证集下,方案优劣一目了然。
在之前的文章 RAG 最佳实践 中,我结合过往实践与相关研究,总结了经过实际验证的最佳策略组合。近期注意到 Ilya Rice 分享了其在企业 RAG 竞赛中获奖的方案,本文将拆解其核心策略,期望为最佳实践体系带来有益补充。
整体架构
方案整体架构如下:
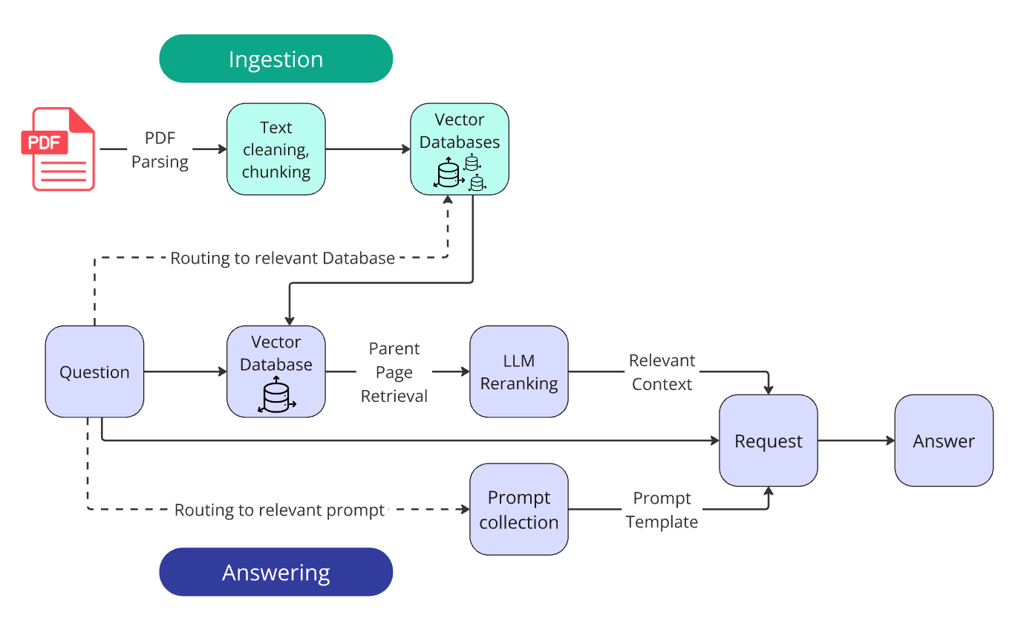
从架构图可以看出,与常规 RAG 方案相比,存在以下显著差异:
- 知识库的路由,根据问题进行知识库路由,这样可以收缩需要检索的文档范围,提升检索效率与准确性;
- prompt 路由,根据实际的问题路由选择对应的 prompt,问题分类合理的情况可以提升大模型回答的质量;
- 父子检索,此方案可以避免检索信息不完整的问题,此方案因为使用性价比高而且效果不错,实践中使用广泛;
- 大模型重排序,一般情况下会使用重排序模型进行重排序,但是此方案中直接使用了大模型,预期效果会更好,但是成本也会更高;
项目开发者 Ilya Rice 认为,以下策略组合对效果提升贡献最大:
- Custom PDF parsing with Docling(基于 Docling 实现的自定义 PDF 解析器)
- Vector search with parent document retrieval(父子检索)
- LLM reranking for improved context relevance(大模型重排序)
- Structured output prompting with chain-of-thought reasoning(基于 COT 推理的结构化输出)
- Query routing for multi-company comparisons(用于多公司比较的查询路由)
在下面的方案分析会重点关注这些独特之处。
知识库构建
文件解析
解析器选型
项目需处理大量 PDF 文件,而 PDF 文本解析一直是业界难题。经过在项目中的实际测试,表现最佳的是 Docling,这是一款由 IBM 开源、社区热度较高的 PDF 解析工具,实际效果确实优异。
即便如此,Docling 也无法实现完美解析。项目中将 PDF 解析为 JSON 文件,并结合正则表达式进行文本修正。
表格数据处理
在向量检索场景下,表格数据的检索效果普遍较差。表格中可检索的信息主要来自表头与当前行的信息组合,且常需跨越多个分隔单元才能定位目标数据。项目开发者给出了如下示意图:
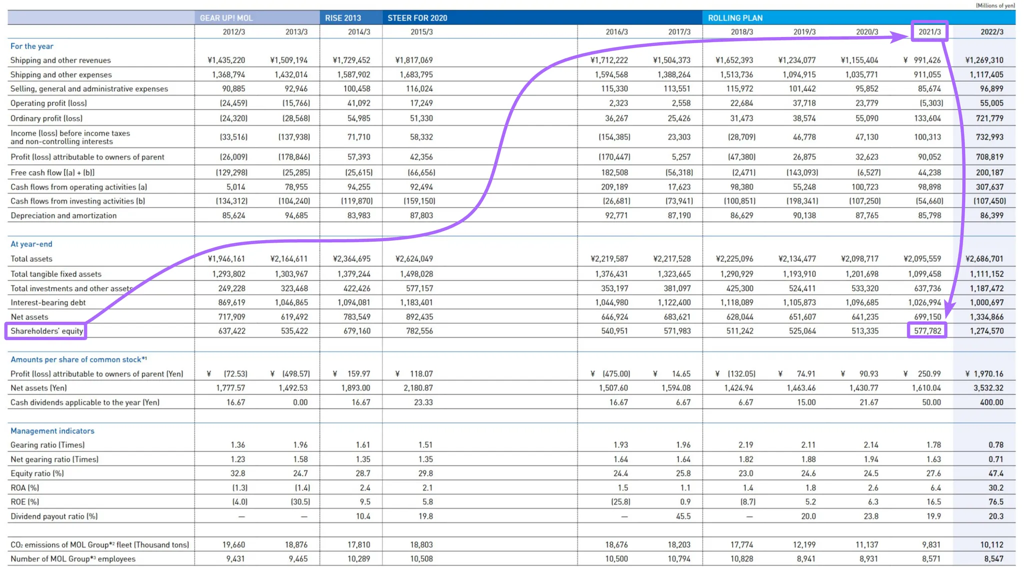
如果 RAG 的检索中没有做出合适的表格预处理,表格数据基本无法正确检索到。针对表格有两种比较常规的做法:
- 表格切片检索,命中片段后获取完整表格,并构造表格 Agent 进行数据检索,类似于 langchain 的 Pandas Agent;
- 按行序列化表格,将表头信息扩展至每一数据行,避免无表头数据行无法检索,Dify 的 Csv Parser 有类似实现;
- 直接将完整表格及其上下文交由大模型处理,实现自动序列化。
在此项目中采用的是第三种方案,其使用的是 GPT-4o-mini 将原始表格信息以及表格前后的内容提供给大模型,之后利用大模型直接进行序列化,对应的实现如下所示:
for table in json_report["tables"]:
# 获取表格前后的内容
context_before, context_after = self._get_table_context(json_report, table_index)
# 获取表格对应的 html 格式内容
table_info = next(table for table in json_report["tables"] if table["table_id"] == table_index)
table_content = table_info["html"]
# 构造大模型查询的 prompt
query = ""
if context_before:
query += f'Here is additional text before the table that might be relevant (or not):\n"""{context_before}"""\n\n'
query += f'Here is a table in HTML format:\n"""{table_content}"""'
if context_after:
query += f'\n\nHere is additional text after the table that might be relevant (or not):\n"""{context_after}"""'
queries.append(query)
# 调用大模型生成序列化
results = await AsyncOpenaiProcessor().process_structured_ouputs_requests(
model='gpt-4o-mini-2024-07-18',
temperature=0,
system_content=TableSerialization.system_prompt,
queries=queries,
response_format=TableSerialization.TableBlocksCollection,
preserve_requests=False,
preserve_results=False,
logging_level=20,
requests_filepath=requests_filepath,
save_filepath=results_filepath,
)
此方案相对其他方案的优势在于实现方便,而且可以结合表格前后的数据,这些地方可能会包含表名的信息,可以有效提升表格召回率。但是劣势在于预处理的成本会更高一些。
分片
为保证向量模型召回效果,需对原始文本进行切片。参考 RAG 最佳实践,建议采用递归字符切片与特定文档格式切片结合,分片长度建议为 256~512 tokens。
本项目实际采用递归字符切片,分片长度 300 tokens,重叠 50 tokens。
向量模型与向量数据库
向量模型对检索效果影响显著。本项目选用 OpenAI 的 text-embedding-3-large。模型选型可参考 MTEB 榜单,Qwen3-Embedding 系列近期表现优异,建议结合自有数据集评估选型。
向量数据库方面,竞赛项目采用 Faiss,生产环境建议使用 Milvus 以保障服务可靠性。
知识库问答
检索
在项目的检索方案中,项目探索了向量检索与 BM25 的混合检索方案。但是按照他的最简化实现,效果表现不佳,最终放弃了这个优化方向。一般而言,混合检索可以相对有效提升向量检索的召回率,建议大家在自己的实际项目中还是建议尝试。
知识库路由
这是一个相对简单而高效的检索策略,因为向量检索基于相似性去判断匹配的内容往往准确性有限,在当前项目中,由于文档以公司为单位,因此为单个公司构建了一堆对应的知识库,这样问题会路由至对应的知识库并在当前知识库进行检索,这样带来的好处十分明显:
- 检索空间大幅收缩,在这个项目中收缩了 100 倍;
- 检索效率与准确性都会有明显提升,避免了大量的干扰文档;
这个策略在实际生产环境可以通过知识分库路由或检索分片的元数据过滤来实现,如果知识库中文档存在明显的元信息标签可供使用,建议尽可能保留与利用,可以有效提升检索质量。
检索增强(Passage augmenter)
本项目采用 RAG 最佳实践 推荐的父子检索策略。父子检索实现成本低,能有效缓解分片信息不完整问题,是当前主流增强方案之一。
LLamaIndex 的 Building Performant RAG Applications for Production 提出:检索分片与大模型上下文分片应解耦。父子检索正是该思想的典型实现。
重排序(Passage Rerank)
传统重排序依赖专用模型。随着大模型能力提升,越来越多方案直接用大模型微调实现重排序,如 gte-Qwen2-7B-instruct 和 qwen3-reranker 系列。
本项目更为直接,直接用大模型对文本相关性打分并重排序,同时将大模型分数与向量相似度加权,确定最终得分。实现如下:
def get_rank_for_single_block(self, query, retrieved_document):
user_prompt = f'/nHere is the query:/n"{query}"/n/nHere is the retrieved text block:/n"""/n{retrieved_document}/n"""/n'
completion = self.llm.beta.chat.completions.parse(
model="gpt-4o-mini-2024-07-18",
temperature=0,
messages=[
{"role": "system", "content": self.system_prompt_rerank_single_block},
{"role": "user", "content": user_prompt},
],
response_format=self.schema_for_single_block
)
response = completion.choices[0].message.parsed
response_dict = response.model_dump()
return response_dict
# 基于大模型确定文本评分
ranking = self.get_rank_for_single_block(query, doc['text'])
doc_with_score = doc.copy()
doc_with_score["relevance_score"] = ranking["relevance_score"]
# 将大模型评分与向量相似分进行加权确定最终得分
doc_with_score["combined_score"] = round(
llm_weight * ranking["relevance_score"] +
vector_weight * doc['distance'],
4
)
结果生成(Generator)
Prompt 路由
竞赛对输出结果有明确规范,通用回答虽正确但格式不符难以得分。为此,项目针对不同问题类型设计多组 prompt,并根据问题类型路由至匹配 prompt,结合 one-shot/few-shot 示例,引导输出规范化结果。如下图所示:
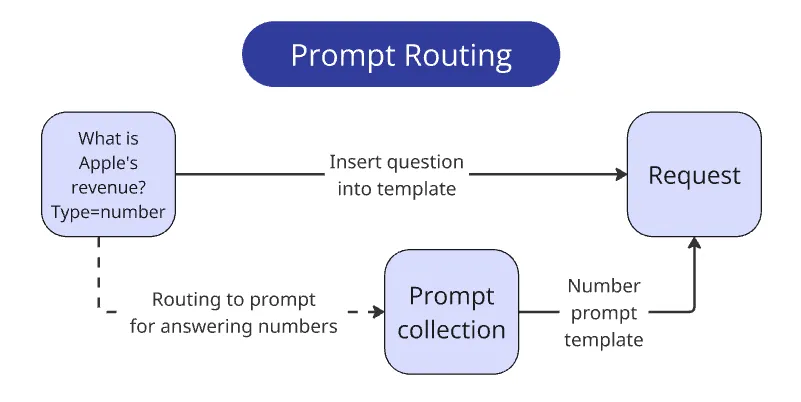
虽然项目 prompt 无法直接复用,但针对特定场景设计路由的思路值得借鉴。建议先梳理应用场景,再为每类场景设计专属 prompt 及 few-shot 示例,进一步提升答案准确性与规范性。
COT 生成
COT 能显著提升大模型输出质量,但常规 Think step by step 远远不够。作者实践表明,显式推理步骤能有效提升推理质量。
本项目针对不同问题类型,设计了专属 COT 推理路径,并通过 Few Shot 进一步引导,提升生成质量。例如针对数字问答,COT prompt 设计如下:
step_by_step_analysis: str = Field(description="""
Detailed step-by-step analysis of the answer with at least 5 steps and at least 150 words.
**Strict Metric Matching Required:**
1. Determine the precise concept the question's metric represents. What is it actually measuring?
2. Examine potential metrics in the context. Don't just compare names; consider what the context metric measures.
3. Accept ONLY if: The context metric's meaning *exactly* matches the target metric. Synonyms are acceptable; conceptual differences are NOT.
4. Reject (and use 'N/A') if:
- The context metric covers more or less than the question's metric.
- The context metric is a related concept but not the *exact* equivalent (e.g., a proxy or a broader category).
- Answering requires calculation, derivation, or inference.
- Aggregation Mismatch: The question needs a single value but the context offers only an aggregated total
5. No Guesswork: If any doubt exists about the metric's equivalence, default to `N/A`."
""")
Few-Shot 示例如下:
example = r"""
Example 1:
Question:
"What was the total assets of 'Waste Connections Inc.' in the fiscal year 2022?"
Answer:
{
"step_by_step_analysis": "1. **Metric Definition:** The question asks for 'total assets' for 'Waste Connections Inc.' in fiscal year 2022. 'Total assets' represents the sum of all resources owned or controlled by the company, expected to provide future economic benefits.\n2. **Context Examination:** The context includes 'Consolidated Balance Sheets' (page 78), a standard financial statement that reports a company's assets, liabilities, and equity.\n3. **Metric Matching:** On page 78, under 'December 31, 2022', a line item labeled 'Total assets' exists. This directly matches the concept requested in the question.\n4. **Value Extraction and Adjustment:** The value for 'Total assets' is '$18,500,342'. The context indicates this is in thousands of dollars. Therefore, the full value is 18,500,342,000.\n5. **Confirmation**: No calculation beyond unit adjustment was needed. The reported metric directly matches the question.",
"reasoning_summary": "The 'Total assets' value for fiscal year 2022 was directly found on the 'Consolidated Balance Sheets' (page 78). The reported value was in thousands, requiring multiplication by 1000 for the final answer.",
"relevant_pages": [78],
"final_answer": 18500342000
}
"""
项目实际输出中,将 COT 分析过程与最终结果分开保存,便于追踪推理链路和后续优化。
总结
本项目拆解了 RAG 竞赛冠军方案,与之前的 RAG 最佳实践 在实现思路和选型上高度一致,同时补充了若干优化策略。个人认为,最具启发性的优化点包括:
- 高质量文件解析,为后续所有策略奠定基础;
- 检索路由机制,利用元信息缩小检索空间,提升精度;
- 基于 COT 的 prompt 路由机制,针对不同场景设计高质量推理路径,最大化提升大模型输出质量。