背景介绍
最近因为岗位扩张,经历了密集的简历轰炸。在短短一周内抽空筛查了接近 100+ 的前后端的简历筛选,和 HR 沟通之后,她反馈她那边已经做过一轮简历筛选,过滤掉接近 90% 的简历了,预期 HR 在短期内需要处理 1000+ 的简历筛选。考虑到这个工作的重复性,而且简历内容的筛查还存在一些明显的技术门槛,没有相关的技术背景容易误判,似乎有自动化的必要性。
我们当前有一台测试服务器,上面部署了一套 Dify 的服务,相关的大模型也已经部署好了,因此考虑直接基于现有服务快速搭建一套 HR 简历筛选服务,帮助减少人力筛选的工作量。实际通过 1H 的尝试,搭建了基础原型服务,实现效果如下所示:
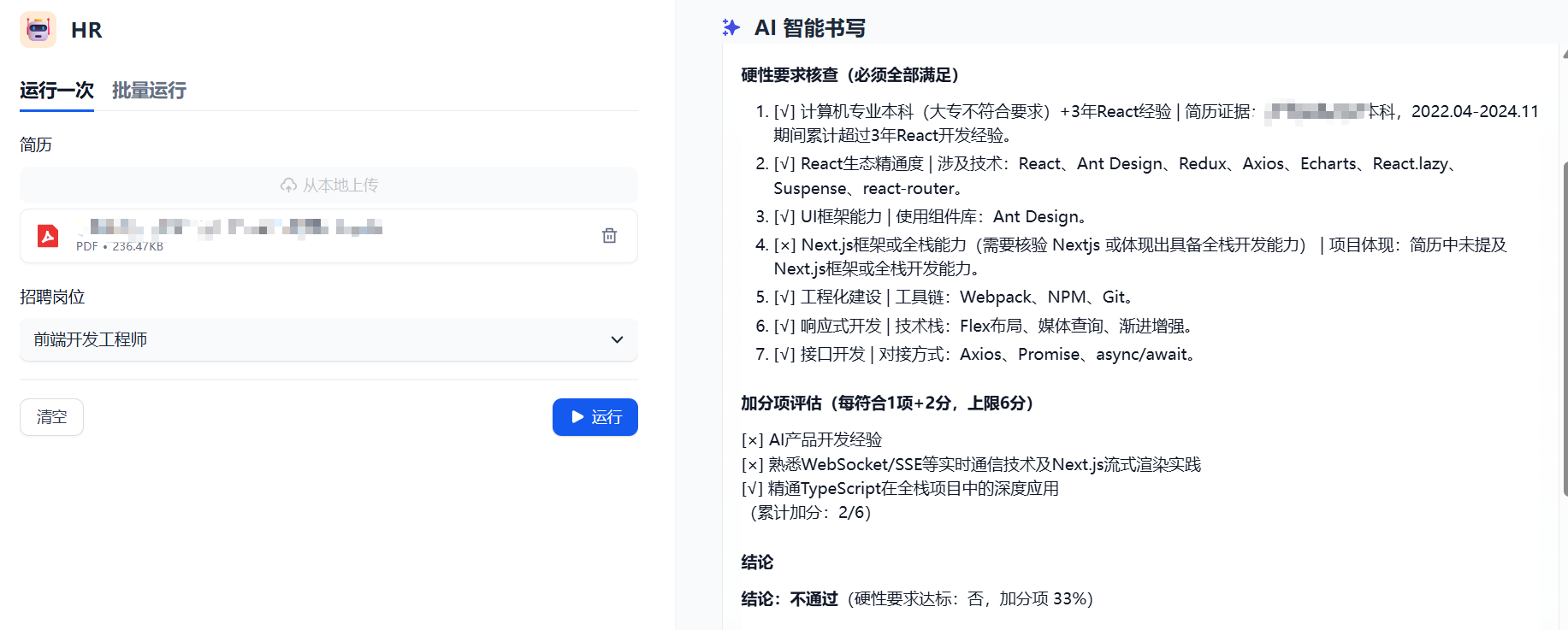
整体效果比较预期,上线后 HR 小姐姐反馈效果不错,可以帮助她节省不少时间,提效明显。因此整理了相关实践过程给大家,期望对大家有所帮助。
方案设计
简历筛选最重要的职责是完成人岗匹配,确定求职者与岗位匹配度,过滤掉相关度不高的简历。此流程中包含如下所示的关键功能:
- 简历内容解析:简历一般情况是 PDF 格式,需要解析出的文本内容,方便进行后续的匹配度分析。
- 岗位选择:一般情况下,公司招聘一般会同时存在多个岗位,简历需要根据对应的岗位要求进行匹配。
- 简历匹配:根据岗位要求和简历内容进行匹配,确定求职者与岗位的匹配度。
根据对应的功能,在现有的 Dify 平台上,存在对应的开箱即用的组件:
- 简历内容解析:可以使用现有的文件解析组件
文档提取器,从原始文件中提取文件内容; - 岗位选择:通过现有的逻辑判断组件
条件分支,并配合初始化时的下拉选项组件,可以实现根据岗位要求进行选择; - 简历匹配:通过现有的
LLM组件,通过精心设计对应的 prompt, 可以实现岗位和简历的匹配度分析。
实现细节
整体的工作流如下所示:
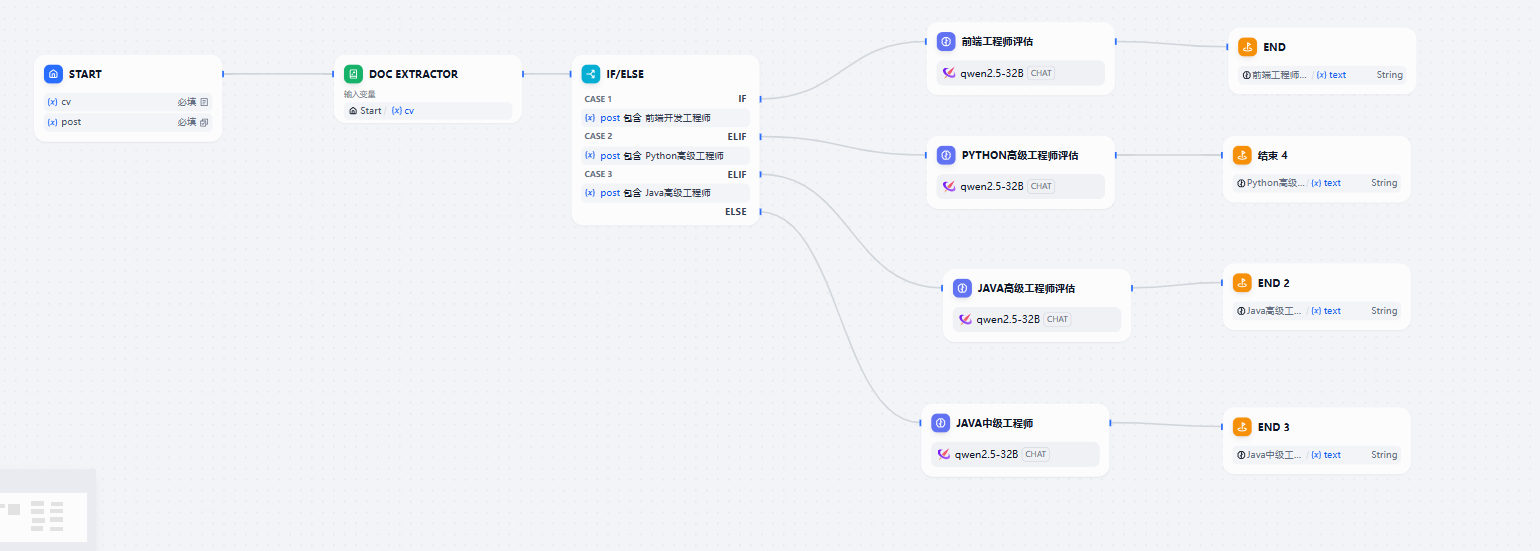
实现相对简单,但是当前阶段自己用下来,还是相对符合预期。实践中可以根据实际筛选的结果确定的正负样本持续微调过滤标准,迭代几轮之后和个人判断的差距就越来越小了。下面介绍下其中的一些关键节点:
初始节点
初始节点决定了可视化页面上可以操作的组件,目前需要在页面上提供的是岗位和简历上传,起始节点需要配置对应的内容选择器。
以简历上传组件为例,在起始节点选择了单文件类型,可视化页面就会出现对应的文件选择器。具体如下所示:
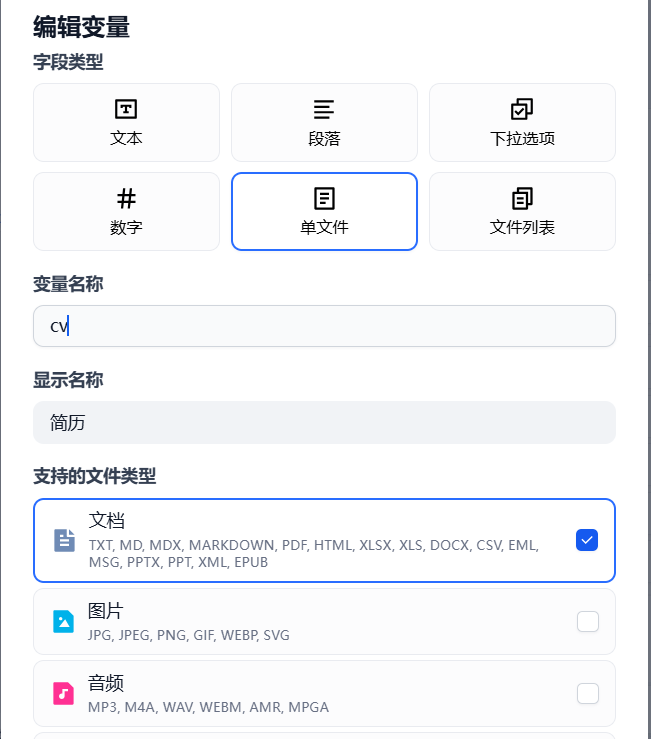
可视化页面对应的文件上传选择器会展现如下所示:

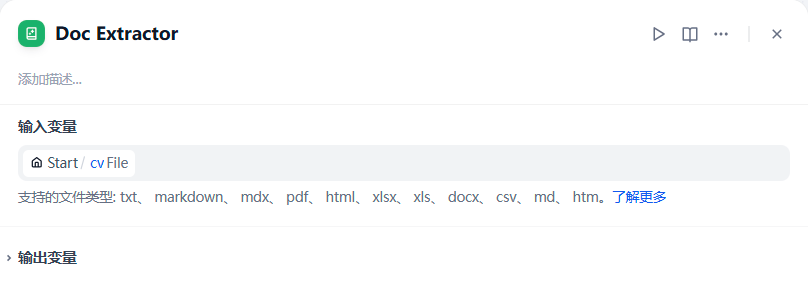
简历解析
简历解析只需要将上传的简历文件提供给 文档提取器 组件即可,文档提取器组件组件会从文档中提取文本内容,组件完全是开箱即用的:
简历匹配
简历匹配主要借助大模型节点来完成,因此 prompt 的设计是关键,实际中需要根据实际的岗位需求调整对应的筛选标准,当前设计的一个前端岗位的 prompt 简化后如下所示:
## 系统指令 ##
你是一位专业的技术简历评估专家,请按以下框架分析候选人与岗位的匹配度。输出必须严格遵守格式要求:
## 匹配度分析 ##
### 硬性要求核查(必须全部满足) ###
1. [√/×] 计算机专业本科(大专不符合要求)+3年React经验 | 简历证据:...
2. [√/×] React生态精通度 | 涉及技术:...
3. [√/×] UI框架能力 | 使用组件库:...
...
### 加分项评估(每符合1项+2分,上限6分) ###
[√/×] AI产品开发经验
[√/×] 精通TypeScript在全栈项目中的深度应用
...
(累计加分:X/6)
## 结论 ##
**结论:通过/不通过**(硬性要求达标:是/否,加分项 X%)
## 评审建议 ##
1. 核心优势:...
2. 风险缺口:...
3. 待确认项:...
关于 prompt 的设计,根据实际碰到的情况有一些优化建议:
- 筛选条件强调:需要根据实际的岗位需求进行定义,但是要注意大模型偶尔会出现一些幻觉,需要根据实际的情况进行优化。比如我实际使用发现本地的模型偶尔会弄错
专科和本科,可以在筛选条件中对应强调,就像上面的例子中,我在本科后面加上了(大专不符合要求)。 - 输出结论后置:最初为了 HR 阅读方便,我将结论放在最前面。实际发现大模型很容易误判,考虑到大模型会根据前面的输出的内容作为上下文辅助推理,存在 COT 的机制,因此将结论后置,准确性明显更高。
总结
通过上面的尝试,快速为 HR 搭建了一套简历筛选服务,实现了辅助简历筛选的功能。虽然没有使用过于复杂的大模型技术,但是实际的带来的改善还是比较明显的,大模型的落地不需要追求最好的技术,只要能够满足业务场景的需求即可。
当然考虑到实际的场景,还是有不少的优化空间,比如通过精细化的文本解析,可以获取更加结构化的简历信息,比如工作年限,工作年限,毕业院校等,可以帮助实现更加准确的简历匹配,这个就留给大家进一步探索了。