背景介绍
在2024年,我曾撰写过 RagFlow 源码全流程深度解析,对 RagFlow 的完整 RAG 流程进行了深入剖析。自那时起,RagFlow 经历了多轮迭代演进,不仅增强了 Agent 能力,更是在知识图谱支持方面取得了显著进展。
最近,RagFlow 公众号发布了 RAGFlow 0.16.0 特性总览,详细介绍了 RagFlow 对知识图谱机制的优化。本文将对 RagFlow 的知识图谱实现流程与机制进行深入分析,帮助读者更好地理解其实现细节,从而更有效地利用 RagFlow 的相关功能。
RagFlow 产品页面
首先,让我们了解当前产品页面的配置选项,以便更好地理解实现细节。
截至2025年4月,RagFlow 的 Web 页面中,知识图谱配置页面提供以下维度的配置:
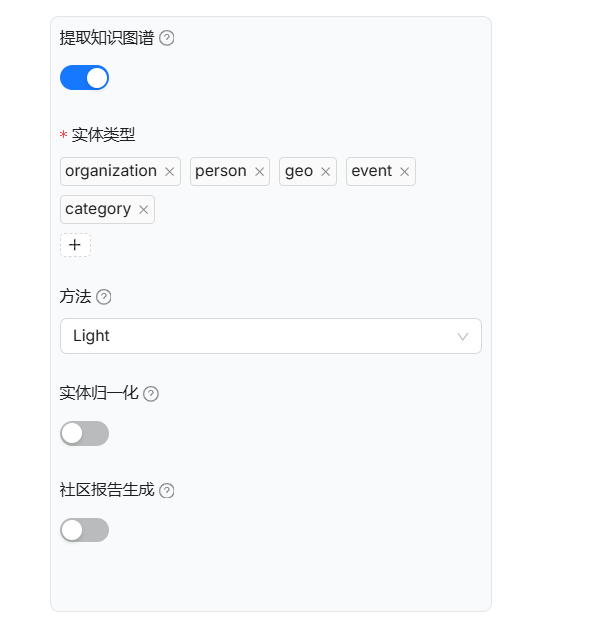
- 实体类型:知识图谱的核心在于实体与关系的提取,选择具有实际业务价值的实体类型至关重要,这直接影响知识图谱的准确性;
- 方法:支持 Light 和 General 两种模式。Light 模式采用 LightRAG 的实体抽取 prompt,而 General 模式则采用微软 GraphRAG 的 prompt,后者更全面但消耗更多 token;
- 实体归一化:用于合并相同实体,提升知识图谱的准确性。该功能自 RagFlow 0.9 版本引入,在 RagFlow 0.16 中支持手动关闭,因为实体重复判断基于大模型,会消耗大量 token;
- 社区报告生成:基于 GraphRAG 引入的功能,通过生成社区实体和关系的摘要来提升社区召回准确性。社区摘要的生成同样依赖大模型,会消耗大量 token,在 RagFlow 0.16 中支持可选关闭;
从产品设计可以看出,RagFlow 在 GraphRAG 的基础上进行了多项优化,特别是在减少大模型 token 消耗方面做了重要权衡。下面将详细介绍具体的实现方案。
GraphRAG 方案
RagFlow 的知识图谱实现基于 GraphRAG 方案,并在此基础上进行了优化。要理解 RagFlow 的实现,首先需要了解 GraphRAG 的基本原理,详细内容可参考微软的论文 From Local to Global: A GraphRAG Approach to Query-Focused Summarization。该方案的核心流程如下图所示:
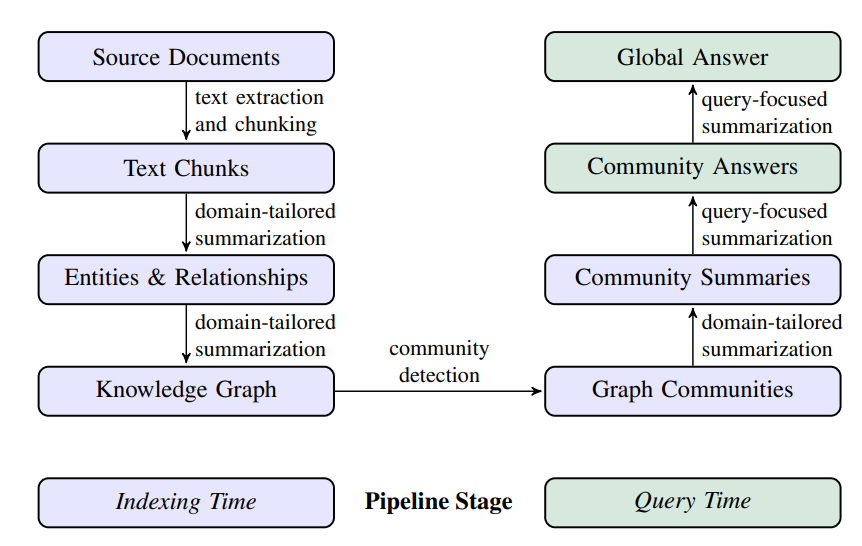
左侧部分是从原始文档到知识图谱的构建流程,右侧是基于知识图谱的社区构建与摘要生成。核心环节包括:
- 实体和关系抽取(Text Chunks -> Entities and Relations):此环节是从原始的文档中提取实体和关系,目前是利用大模型直接抽取完成的,上面提到的 Light 和 General 的区别影响的就是这部分抽取的 prompt;
- 知识图谱构建(Entities and Relations -> Knowledge Graph):此环节是直接将实际和关系构建为知识图谱,属于标准操作;
- 社区构建(Knowledge Graph -> Graph Communities):此环节是使用社区检测算法将图划分为强连接节点的社区,GraphRAG 使用的是 Leiden 社区检测算法;
- 社区摘要生成(Graph Communities -> Community Summaries):此环节是基于社区的实体和关系生成对应的摘要,这样才能更精准地召回对应的社区,上面提到的社区报告生成的可选开关就是关闭这部分摘要的生成;
RagFlow 知识图谱构建实现方案
RagFlow 在 GraphRAG 方案的基础上进行了优化和扩展,下面详细介绍具体实现细节。
构建整体流程
RagFlow 的知识图谱构建完整流程在 graphrag/general/index.py 的 run_graphrag() 方法中实现,包含以下环节:
- 基于文档分片构建知识图谱,包括实体和关系的抽取,以及知识图谱的生成;
- 知识图谱合并,将新生成的知识图谱与原有知识图谱进行合并;
- 知识图谱的实体合并,减少实体重复,提升准确性;
- 基于知识图谱构建社区,包括社区构建与摘要生成;
实现代码如下:
async def run_graphrag(
row: dict,
language,
with_resolution: bool,
with_community: bool,
chat_model,
embedding_model,
callback,
):
# 获取文档分片
tenant_id, kb_id, doc_id = row["tenant_id"], str(row["kb_id"]), row["doc_id"]
chunks = []
for d in settings.retrievaler.chunk_list(
doc_id, tenant_id, [kb_id], fields=["content_with_weight", "doc_id"]
):
chunks.append(d["content_with_weight"])
# 构建知识图谱
subgraph = await generate_subgraph(
LightKGExt
if row["parser_config"]["graphrag"]["method"] != "general"
else GeneralKGExt,
tenant_id,
kb_id,
doc_id,
chunks,
language,
row["parser_config"]["graphrag"]["entity_types"],
chat_model,
embedding_model,
callback,
)
if not subgraph:
return
# 合并知识图谱
subgraph_nodes = set(subgraph.nodes())
new_graph = await merge_subgraph(
tenant_id,
kb_id,
doc_id,
subgraph,
embedding_model,
callback,
)
assert new_graph is not None
if not with_resolution or not with_community:
return
# 可关闭的实体合并机制
if with_resolution:
await resolve_entities(
new_graph,
subgraph_nodes,
tenant_id,
kb_id,
doc_id,
chat_model,
embedding_model,
callback,
)
# 可关闭的社区发现机制
if with_community:
await extract_community(
new_graph,
tenant_id,
kb_id,
doc_id,
chat_model,
embedding_model,
callback,
)
return
实体与关系抽取
知识图谱构建的基础是实体与关系的抽取。在 GraphRAG 方案中,通过精心设计的 prompt 和 Few-Shot 机制,利用大模型完成实体和关系的抽取。
这部分对应的实现在 graphrag/general/graph_extractor.py 中的 _process_single_content() 方法中完成,GraphRAG 为实体与关系提取设计了一个精巧的 prompt, 并通过 Few Shot 的机制进行了必要的优化,从 Few Shot 可以大致了解提取的实体与关系的格式:
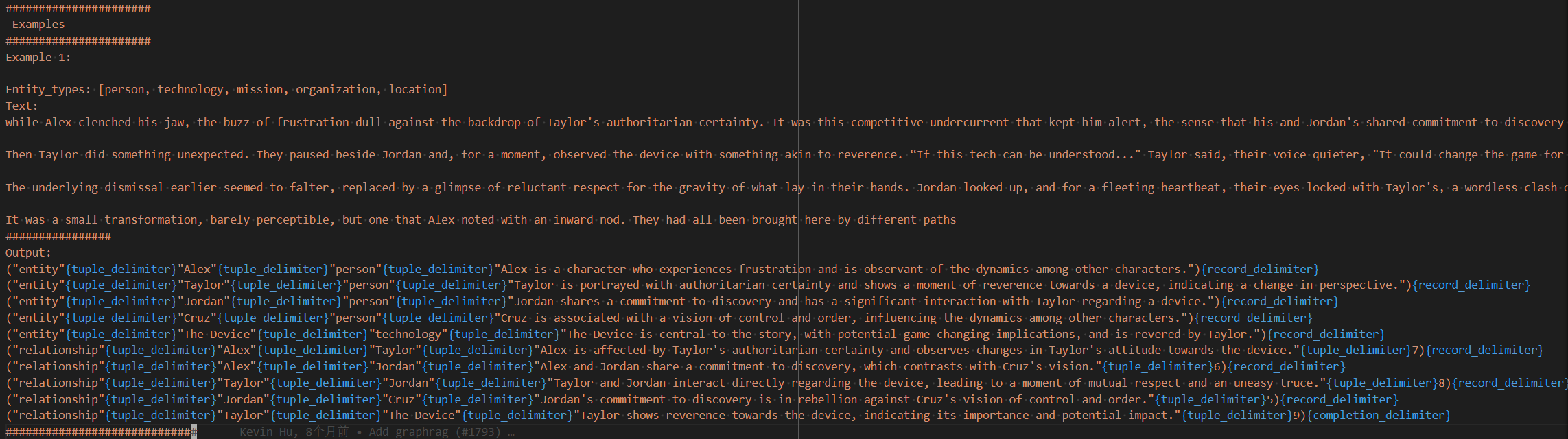
根据上面看到的 example,大模型的结果是文本对应的实体和关系,并使用分隔符进行连接,之后在 _entities_and_relations() 方法中使用基于分隔符进行切分,即可得到对应的实体和关系。
知识图谱生成与合并
实体和关系抽取完成后,RagFlow 基于 networkx 生成知识图谱,并与知识库中原有知识图谱进行合并。
知识图谱生成通过调用 networkx 的 add_node() 和 add_edge() 方法实现,具体实现可参考 graphrag/general/index.py 中的 generate_subgraph() 方法。
知识图谱合并在 graph_merge() 中完成,处理逻辑如下:
- 节点存在时,将新节点的描述信息叠加至原有节点;
- 关系存在时,将新关系的描述信息、权重和关键词叠加至原有关系;
知识图谱的实体合并
实体合并是知识图谱构建的重要环节,重复实体会降低检索准确性。RagFlow 在 graphrag/entity_resolution.py 中实现实体合并,采用两步策略:
- 初步相似度判断:使用编辑距离等工程手段筛选相似实体,基于 editdistance 实现;
- 大模型相似度判断:确定最终的实体合并结果;
初步相似度判断主要用于减少候选实体对的数量。虽然基于大模型的相似度判断准确性更高,但会带来较大的计算开销,这也是 RagFlow 提供手动关闭选项的主要原因。
社区构建
RagFlow 的社区构建基于 Leiden 算法实现,该算法通过模块度优化生成高质量的社区划分。具体实现原理可参考论文 From Local to Global: A GraphRAG Approach to Query-Focused Summarization。实现位于 graphrag/general/leiden.py。
社区构建基于 graspologic 的 hierarchical_leiden 实现:
def _compute_leiden_communities(
graph: nx.Graph | nx.DiGraph,
max_cluster_size: int,
use_lcc: bool,
seed=0xDEADBEEF,
) -> dict[int, dict[str, int]]:
results: dict[int, dict[str, int]] = {}
if is_empty(graph):
return results
if use_lcc:
graph = stable_largest_connected_component(graph)
# 多层级社区划分
community_mapping = hierarchical_leiden(
graph, max_cluster_size=max_cluster_size, random_seed=seed
)
for partition in community_mapping:
results[partition.level] = results.get(partition.level, {})
results[partition.level][partition.node] = partition.cluster
return results
社区摘要生成
社区摘要生成基于社区中实体和关系的描述信息,完全依赖大模型实现。通过精心设计的 prompt,生成能够代表社区核心内容的文本,提升检索和召回准确性。
相关 prompt 在 graphrag/general/community_report_prompt.py 中定义,核心内容如下:
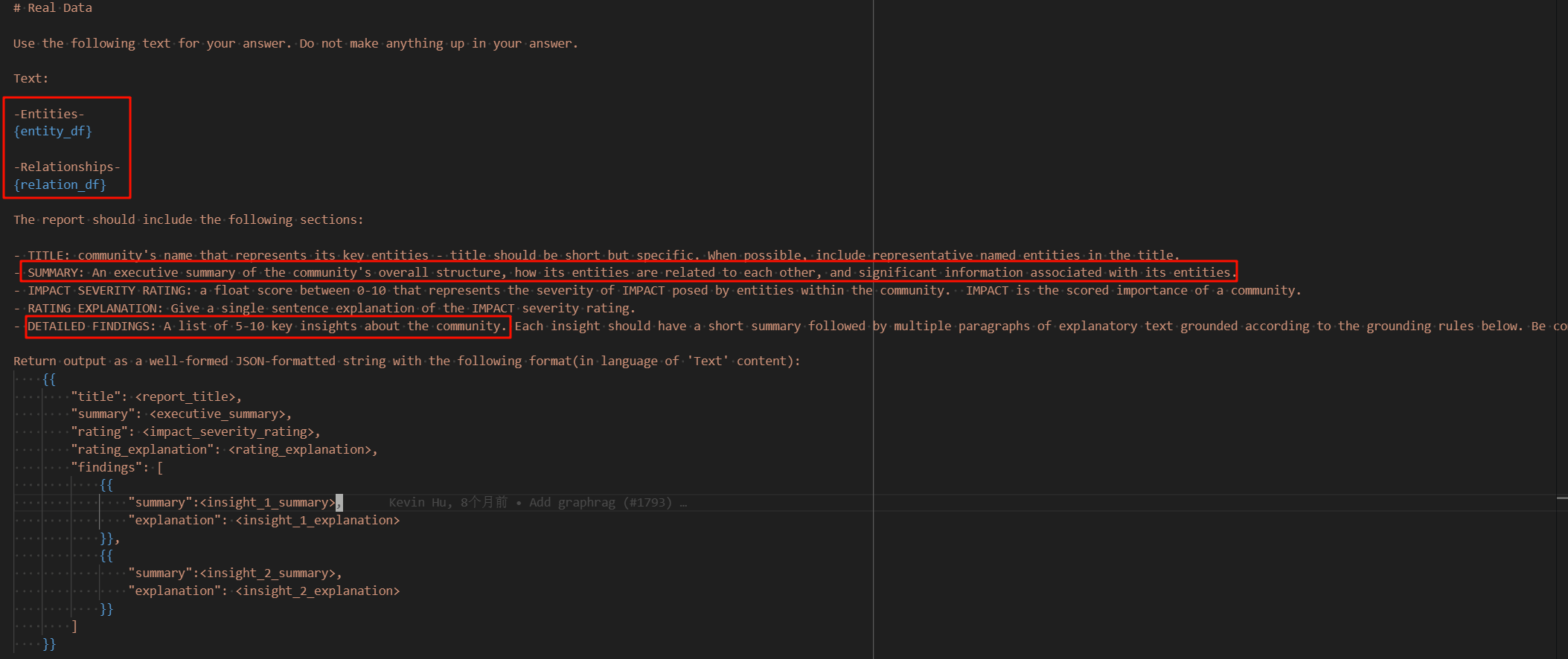
输入为实体和关系数据,大模型生成社区摘要和关键见解,提升社区召回的准确性。
知识图谱检索
知识图谱构建完成后,RagFlow 利用知识图谱增强 RAG 检索。以 /dify/retrieval 接口为例,检索实现如下:
ranks = settings.retrievaler.retrieval(
question,
embd_mdl,
kb.tenant_id,
[kb_id],
page=1,
page_size=top,
similarity_threshold=similarity_threshold,
vector_similarity_weight=0.3,
top=top,
rank_feature=label_question(question, [kb])
)
# 可选开启知识图谱检索
if use_kg:
ck = settings.kg_retrievaler.retrieval(question,
[tenant_id],
[kb_id],
embd_mdl,
LLMBundle(kb.tenant_id, LLMType.CHAT))
# 知识图谱检索的内容插入常规检索的最前面,知识图谱检索优先展示
if ck["content_with_weight"]:
ranks["chunks"].insert(0, ck)
检索流程在 graphrag/search.py 中实现,具体步骤如下:
- 查询重写:调用
query_rewrite方法,使用大模型提取问题中的实体类型关键词和实体; - 实体与关系检索:通过关键词和实体类型检索相关实体,通过原始问题检索相关关系;
- 路径分析:从关键词检索到的实体出发,获取 N 跳邻居,实现相似度衰减;
- 结果融合与评分:融合关键词检索、实体类型检索和关系检索结果,确定最终得分;
- 结果排序与截断:按相似度和 PageRank 乘积排序,截取前 N 个结果;
- 社区检索:调用
_community_retrival_()方法检索相关社区报告; - 结果组合:将实体、关系和社区报告组合为最终结果;
总结
本文详细介绍了 RagFlow 知识图谱的构建与检索流程。整体实现基于 GraphRAG 方案,并在此基础上进行了多项优化。RagFlow 提供了灵活的配置选项,如社区摘要和实体合并的可选关闭,使用户能够在效果与性能之间进行权衡。这些优化使得 RagFlow 的知识图谱功能更加实用和高效。