背景介绍
Manus 是最近一个现象级的大模型 Agent 工具,自从发布以来,被传出各种神乎其神的故事,自媒体又开始炒作人类大量失业的鬼故事,Manus 体验码也被炒作为 10w 的高价。
之后又出现反转,被爆出实际体验效果不佳,存在造假的问题,Manus在X平台的账号被冻结。沟通之后,3月8日,Manus官方X账号又被解冻。
Manus 的故事一波三折,开源社区也没有闲着,MetaGPT 团队在 Manus 发布后 3 小时就开源了 OpenManus,短短两天 Star 数量一路飙升,截止目前已经 15k+ 的 Star。本文就从开源方案来深入了解 Manus,祛魅自主 Agent 工具。
Agent 介绍
通用型AI Agent(智能体)产品的起源可以追溯到人工智能领域对”自主执行任务”能力的探索。这类产品不仅需要理解用户需求,还需具备规划、调用工具、执行复杂任务的能力。
这类产品最早的探索可以追溯到2023年,AutoGPT(2023年4月)是这个领域的开创性项目。它首次将大语言模型(LLM)与自主任务执行能力结合,开创了 AI Agent 的新范式。用户只需通过自然语言设定目标,模型就能自动分解任务、调用网络搜索和代码执行等工具,尝试完成复杂目标(如市场调研、代码生成等)。虽然受限于当时大模型的能力没能完全实现自主Agent的设想,但AutoGPT为后续Agent工具的发展奠定了基础。目前AutoGPT在Github上的Star数量依旧遥遥领先,已达173k+。
Agent 方案的设想目前来看很合理,大模型拥有类似人类大脑的思考能力,但是人类在解决实际问题时,不仅需要大脑思考,还需要双手来完成任务。而 Agent 方案的设想,就是让大模型来思考和规划,然后调用大量外部工具来完成任务。对应的架构如下所示:

在单一 Agent 之后又发展出 Multi-Agent 的方案,Multi-Agent 的方案可以理解为单 Agent 的升级版,单 Agent 是让大模型来思考和规划,然后调用大量外部工具来完成任务。而 Multi-Agent 是让多个大模型来分工合作,共同完成任务。本文介绍的 OpenManus 属于单 Agent 的方案,后续有机会再介绍 Multi-Agent 的方案。
实现方案
目前单一 Agent 的实现方案主要有以下两种:
- ReAct (Reasoning + Acting) 框架
-
实现逻辑:将任务分解为思考(Reasoning)和行动(Acting)两个交替进行的阶段。通过少样本Prompt引导大模型生成思考链(Thought Chain),确定下一步行动,执行工具调用(Action),观察结果并迭代优化。
- 优势:
- 决策过程透明可解释
- 工具调用灵活,可动态调整策略
- 适合需要复杂推理的任务
- 劣势:
- 每个步骤都需要LLM参与,token消耗大
- 容易在复杂任务中陷入循环
- 执行效率相对较低
- Plan-and-Execute 框架
-
实现逻辑:将任务分为规划(Planning)和执行(Execution)两个明确的阶段。首先生成完整的任务执行计划(通常是DAG图),然后按计划批量执行子任务。
- 优势:
- 显著减少LLM调用次数,降低成本
- 任务执行更加高效
- 适合步骤明确的复杂任务
- 劣势:
- 对初始规划的准确性要求高
- 难以处理高度动态的任务
- 子任务间的依赖关系复杂时容易失败
在 OpenManus 中,简单版本实现的是 ReAct 框架,复杂版本实现的是 Plan-and-Execute 框架。分别对应于 Github 提到的 main.py 和 run_flow.py 入口。截止目前 ReAct 版本完成度较高, Plan-and-Execute 版本还比较原始。本文主要介绍 ReAct 部分的流程。
核心实现细节
ReAct框架的实现遵循”思考-行动-观察”的循环模式:
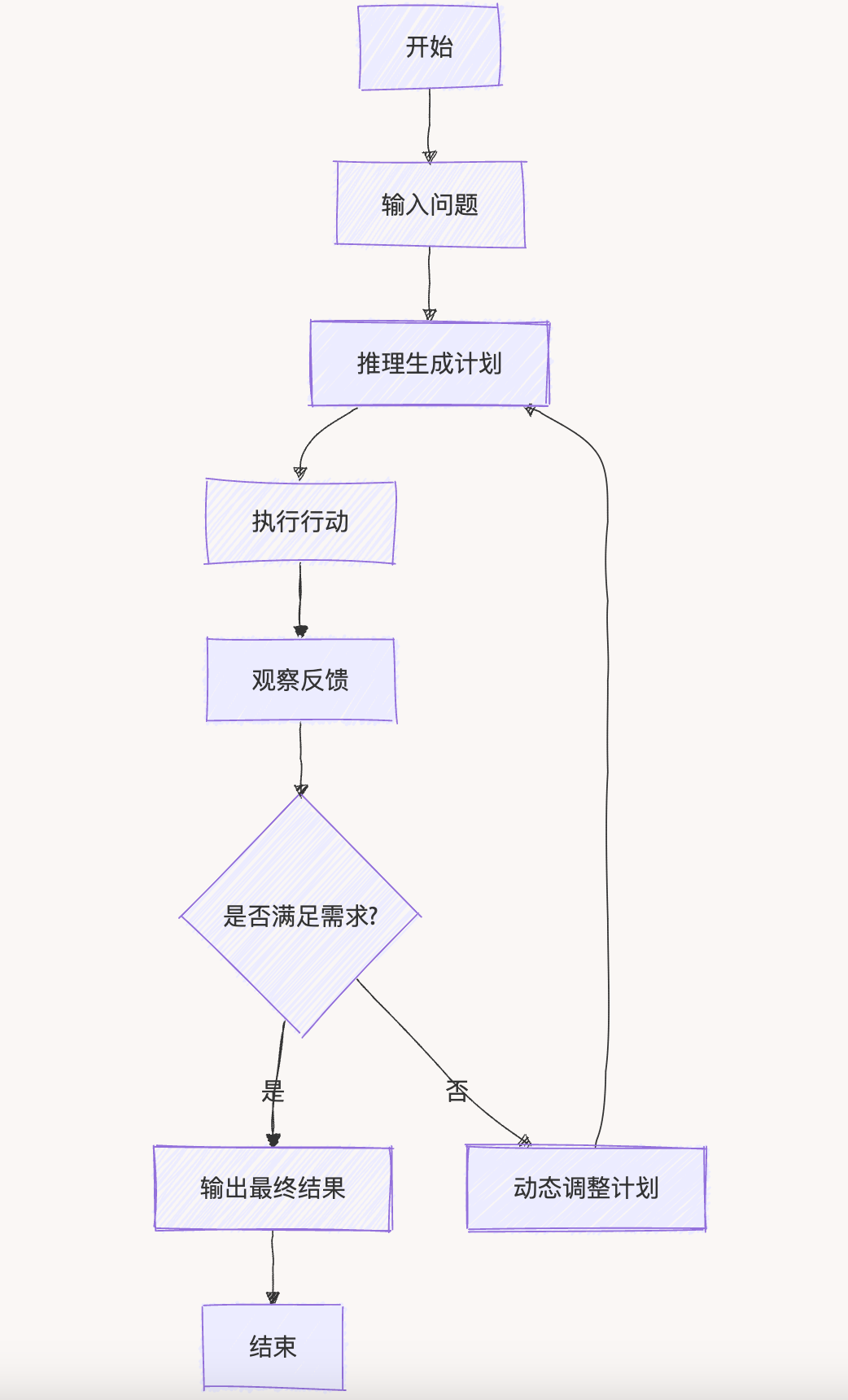
核心流程包括:
- 思考(Reasoning):分析当前状态,确定下一步行动
- 行动(Acting):执行选定的工具调用
- 观察(Observation):收集执行结果,更新状态
- 重复以上步骤直至任务完成
执行流程
核心执行流程的实现在 app/agent/base.py 中可以看到,就是一个简单的循环,在执行过程中重复执行 step() 方法,直到任务完成。
async def run(self, request: Optional[str] = None) -> str:
if request:
self.update_memory("user", request)
results: List[str] = []
async with self.state_context(AgentState.RUNNING):
while (
self.current_step < self.max_steps and self.state != AgentState.FINISHED
):
self.current_step += 1
# 重复执行 step 直到任务完成
step_result = await self.step()
# 如果陷入死循环,则进行处理
if self.is_stuck():
self.handle_stuck_state()
results.append(f"Step {self.current_step}: {step_result}")
# 如果达到最大步数,则结束,避免在无法解决的问题上浪费过多 token
if self.current_step >= self.max_steps:
results.append(f"Terminated: Reached max steps ({self.max_steps})")
return "\n".join(results) if results else "No steps executed"
在单个 step() 方法中,主要就是执行推理 think() 和行动 act() 两个环节。可以看到对应的实现如下所示:
async def step(self) -> str:
# 推理环节
should_act = await self.think()
if not should_act:
return "Thinking complete - no action needed"
# 行动环节
return await self.act()
推理环节
ReAct 推理环节主要用于确定下一步执行的动作,在 OpenManus 中,下一步动作会从下面几个可选动作中进行选择:
- PythonExecute() :执行 Python 代码
- GoogleSearch() :执行 Google 搜索
- BrowserUseTool() :执行浏览器操作
- FileSaver() :保存文件
- Terminate() :终止
如何基于大模型确定具体执行的动作呢?主要基于 OpenAI 提供的 标准方案 ,通过 tools 使用标准格式传入所有可选的工具列表,之后大模型会根据当前的上下文选择一个最合适的工具。对应的实现如下所示:
async def think(self) -> bool:
if self.next_step_prompt:
user_msg = Message.user_message(self.next_step_prompt)
self.messages += [user_msg]
# 调用大模型,传入所有可选的工具列表,之后大模型会根据当前的上下文选择一个最合适的工具
response = await self.llm.ask_tool(
messages=self.messages,
system_msgs=[Message.system_message(self.system_prompt)]
if self.system_prompt
else None,
tools=self.available_tools.to_params(),
tool_choice=self.tool_choices,
)
self.tool_calls = response.tool_calls
行动环节
行动环节主要用于执行具体的动作,在 OpenManus 中,执行动作的实现如下所示:
async def act(self) -> str:
results = []
# 执行推理环节确定的所有工具调用
for command in self.tool_calls:
result = await self.execute_tool(command)
# 将工具调用的结果保存起来,对应于上面的流程中的观察反馈
tool_msg = Message.tool_message(
content=result, tool_call_id=command.id, name=command.function.name
)
self.memory.add_message(tool_msg)
results.append(result)
return "\n\n".join(results)
总结
通过深入分析OpenManus的源码实现,我们可以看到它本质上是ReAct框架的一个标准实现,与早期的 AutoGPT 的实现原理类似,希望本文帮助大家祛魅 Agent 工具。类似的 Agent 工具依旧存在一些明显的挑战:
- Token消耗优化问题
- 复杂任务的循环处理
- 长期记忆管理
随着大模型能力的提升和工具生态的完善,Agent技术必将在特定场景发挥重要作用。但是因为一个 Manus 的出现就惊呼人类要大面积失业,其实大可不必。