背景介绍
最近各种新的大模型辅助科研工具持续出现,在之前的文章中就介绍过 NVIDIA 的结构化报告生成方案,最近 OpenAI 也推出了类似的产品,叫做 Deep Research。Deep Research 可以根据需要进行深度的调研与信息整理,但是只有 Pro 用户才能享受到,$200 的价格直接劝退。在调研后发现了开源项目 AutoSurvey,相对之前的 NVIDIA 的方案更加完整,不仅包含了完整的报告生成,还能自动生成文献列表。通过实际进行二次开发优化,最终可以生成完整的调研报告,个人实际生成的报告如下所示:

方案介绍
AutoSurvey 是一个基于大语言模型的自动综述生成工具。它的整体流程如下所示:
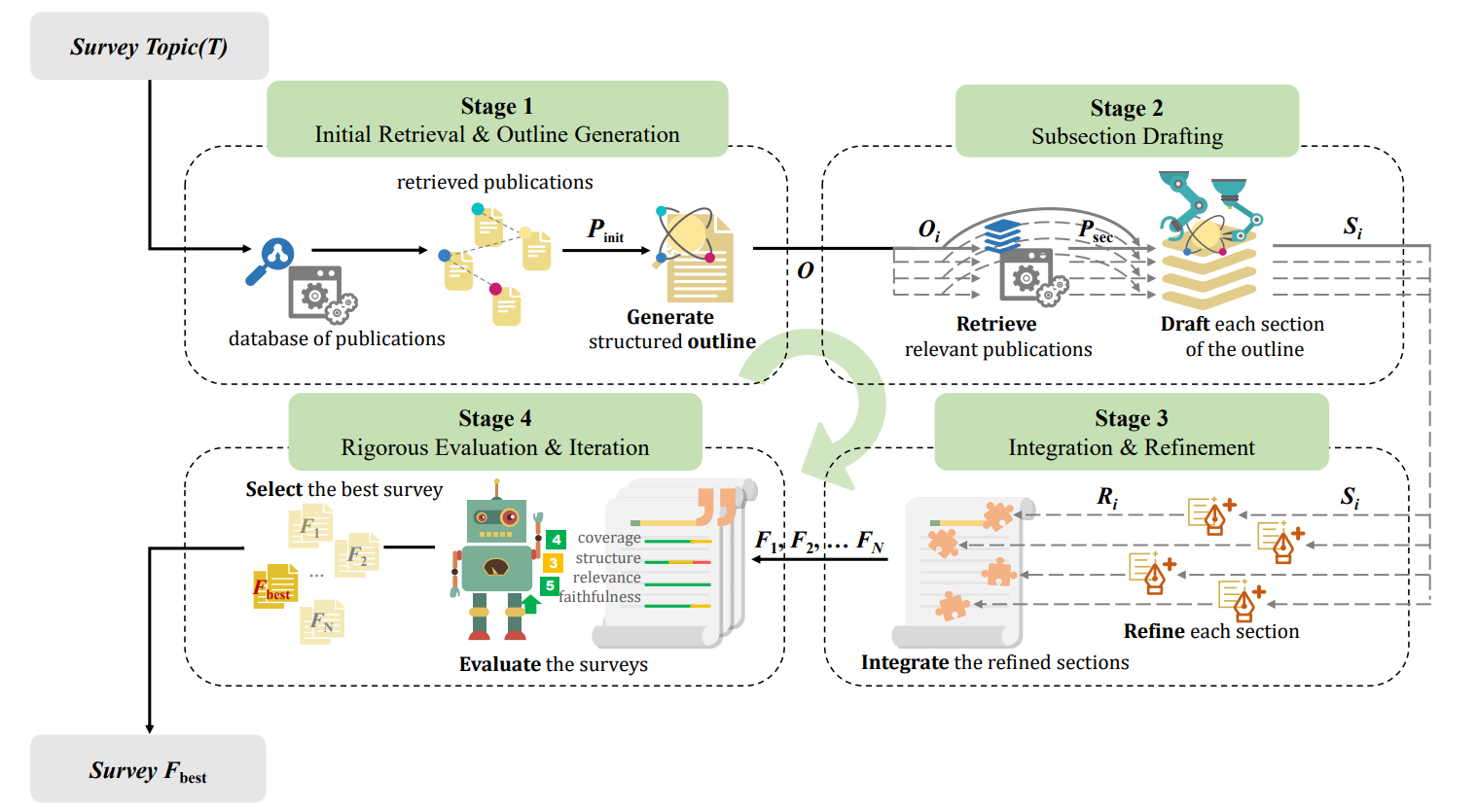
主要的撰写流程包含下面三个步骤:
- 大纲生成;
- 章节内容填充;
- 整合与调优;
整体流程与 NVIDIA 的方案大致相同,但是 AutoSurvey 的方案更加完整,可以支持更加复杂的长报告的生成,并补全了 NVIDIA 方案中没有的文献列表生成。
大纲生成
在 NVIDIA 的方案中,大纲的生成就是就是信息检索加上一次大模型调用总结,因为大模型输入上下文窗口的限制,因此只能获取有限的信息进行作为大纲生成的参考,这个在生成综述类文章时,效果就会有明显的影响。
在大纲生成阶段,AutoSurvey 采用了分层递进的方式,确保生成的大纲既有宏观把控又不失细节。具体步骤包括:
-
广泛信息检索: 默认检索约600篇相关文献,可根据需要调整检索范围
-
分块式章节大纲生成:
- 将检索文献分块处理
- 各分块独立生成粗略大纲
- 整合各分块大纲形成统一章节框架
-
精细化子章节规划:
- 基于章节大纲延伸子章节
- 针对每个章节进行定向信息检索
- 确保子章节内容的专业性和准确性
-
大纲优化与完善:
- 利用大模型进行整体审视
- 调整结构确保逻辑性
- 补充必要的过渡与连接
对应的代码实现在 src/agents/outline_writer.py 中的 draft_outline() 中,最终实现的效果类似如下所示:

章节内容填充
在生成文章的大纲后,就可以独立进行章节内容的填充。章节内容的撰写以子章节为单位,各个子章节独立进行信息检索,并调用大模型生成子章节的内容。
目前检索的文献内容包括:文献的标题与文献的摘要信息。将实际的检索内容有序拼接为一个长文本,拼接格式如下所示:
paper_texts = ''
for t, p in zip(references_titles, references_papers):
paper_texts += f'---\n\npaper_title: {t}\n\npaper_content:\n\n{p}\n'
paper_texts+='---\n'
调用大模型生成子章节内容时,AutoSurvey 做了必要的 prompt 优化,保证最终的输出中,文献的标记被插入到文本中的合适位置,并以 [文献标题] 的形式进行标记,实际使用的 prompt 相关调优类似如下所示:
'''
Here is the requirement you must follow:
1. The content you write must be more than [WORD NUM] words.
2. When writing sentences that are based on specific papers above, you cite the "paper_title" in a '[]' format to support your content. An example of citation: 'the emergence of large language models (LLMs) [Language models are few-shot learners; PaLM: Scaling language modeling with pathways]'
Note that the "paper_title" is not allowed to appear without a '[]' format. Once you mention the 'paper_title', it must be included in '[]'. Papers not existing above are not allowed to cite!!!
Remember that you can only cite the paper provided above and only cite the "paper_title"!!!
3. Only when the main part of the paper support your claims, you cite it.
'''
这边的 [文献标题] 十分重要,大模型需要保证插入的确实是对应文献的标题,而且需要保证是完整插入对应的标题,不能调整,否则后续的文献引用无法正确生成。
生成的各个子章节的内容是独立完成的,因此可能会出现子章节内容不连贯的情况,因此可以选择根据前后子章节的内容进行必要的内容调优,保证整体的连贯性。
AutoSurvey 选择将当前的章节的前一个章节,后一个章节共同提供给大模型,利用大模型进行必要的内容调优,从而提升整体的连贯性,使用到的 prompt 如下所示:
'''
You are an expert in artificial intelligence who wants to write a overall and comprehensive survey about [TOPIC].\n\
You have created a overall outline below:\n\
---
[OVERALL OUTLINE]
---
<instruction>
Now you need to help to refine one of the subsection to improve th ecoherence of your survey.
You are provied with the content of the subsection "[SUBSECTION NAME]" along with the previous subsections and following subsections.
Previous Subsection:
---
[PREVIOUS]
---
Subsection to Refine:
---
[SUBSECTION]
---
Following Subsection:
---
[FOLLOWING]
---
If the content of Previous Subsection is empty, it means that the subsection to refine is the first subsection.
If the content of Following Subsection is empty, it means that the subsection to refine is the last subsection.
Now edit the middle subsection to enhance coherence, remove redundancies, and ensure that it connects more fluidly with the previous and following subsections.
Please keep the essence and core information of the subsection intact.
</instruction>
Directly return the refined subsection without any other informations:
'''
完成章节内容填充后,生成的效果如下所示:

整合与调优
将各个章节的内容进行整合,就可以得到完整的调研报告。但是需要处理文献的引用问题,需要将原始的引用标题替换为引用编号,并将所有的文献引用信息整合到一起,形成完整的文献列表。文献引用的处理流程如下所示:
- 利用正则表达式从原始文献中提取出文献的标题;
- 基于文献标题检索获得真实的文献标题,并根据真实文献标题生成引用编号与最终的引用列表,将原始文本中的引用标题进行替换,并补充完整的引用列表;
为什么要将文本中引用标题再次进行检索呢?实际测试发现,即使进行了 prompt 的调优,大模型生成的引用标题也存在与原始标题不完全一致的情况,部分情况下标题对应的文献可能不存在,因此再次进行检索并替换可以保证最终引用的准确性。
实际文献引用处理的实现如下所示:
def replace_citations_with_numbers(self, citations, markdown_text):
ids = self.db.get_titles_from_citations(citations)
citation_to_ids = {citation: idx for citation, idx in zip(citations, ids)}
paper_infos = self.db.get_paper_info_from_ids(ids)
temp_dic = {p['id']:p['title'] for p in paper_infos}
titles = [temp_dic[_] for _ in tqdm(ids)]
ids_to_titles = {idx: title for idx, title in zip(ids, titles)}
titles_to_ids = {title: idx for idx, title in ids_to_titles.items()}
title_to_number = {title: num+1 for num, title in enumerate(titles)}
title_to_number = {title: num+1 for num, title in enumerate(title_to_number.keys())}
number_to_title = {num: title for title, num in title_to_number.items()}
number_to_title_sorted = {key: number_to_title[key] for key in sorted(number_to_title)}
def replace_match(match):
citation_text = match.group(1)
individual_citations = citation_text.split(';')
numbered_citations = [str(title_to_number[ids_to_titles[citation_to_ids[citation.strip()]]]) for citation in individual_citations]
return '[' + '; '.join(numbered_citations) + ']'
# 利用正则表达式进行标题到文本编号的替换
updated_text = re.sub(r'\[(.*?)\]', replace_match, markdown_text)
# 生成完整的文献列表
references_section = "\n\n## References\n\n"
references = {num: titles_to_ids[title] for num, title in number_to_title_sorted.items()}
for idx, title in number_to_title_sorted.items():
t = title.replace('\n','')
references_section += f"[{idx}] {t}\n\n"
return updated_text + references_section, references
总结
AutoSurvey 作为一个开源的综述报告生成方案,具有以下优势:
- 完整的工作流程: 从大纲生成到内容填充,再到引用处理,形成了一个完整的闭环
- 灵活的定制空间: 代码实现简单,方便根据具体需求进行二次开发
- 智能的引用处理: 自动化的文献引用和列表生成,大大提高了工作效率
- 成本效益显著: 相比 Deep Research 的 $200 订阅费,开源方案更具性价比
对于需要进行文献综述的研究人员来说,AutoSurvey 提供了一个很好的起点。虽然可能需要一些调整和优化,但它的确为自动化学术写作提供了一个可行的解决方案。