背景介绍
在 RAG 最佳实践 中,我介绍了 RAG 的各个核心模块的最佳实践方案,包括文件解析、分片、向量化、检索、重排序等。据此已经得到一个具备良好效果的 RAG 应用,但是如果想生成一个具体良好体验的 RAG 服务,还有一些问题需要优化。
从目前客户的反馈来看,多轮会话的优化是用户最关心的点之一。我们人类进行交流时,往往都是你来我往的多轮沟通,因此对大模型应用的用户而言,很自然会带入日常的交流习惯,比如:
在医疗场景下,用户向大模型提供症状描述后,大模型往往会给出诊断建议。之后用户往往会追问 那应该怎么治疗呢? 或者 那应该吃什么药呢? 等等,如果不结合多轮会话中的上下文信息,大模型很难根据当前轮次的问题给出正确的回答。
当前目前大模型调用时往往提供基于历史会话进行响应的能力,但是在目前的 RAG 应用中,存在的问题往往是检索阶段不具备基于多轮会话检索的能力。比如在上面的问题中 那应该怎么治疗呢? 和 那应该吃什么药呢? 这种类型的问题,直接进行检索很难匹配到正确的信息。本文就是尝试针对此问题的一些优化方案。
开源方案调研
针对上面提到多轮对话的问题,调研了目前主要的开源 RAG 项目,目前针对这个场景有明确优化的是 llama-index 和 haystack。
llama-index
针对多轮对话场景,llama-index 提供了 ChatEngine ,此模块主要用于会话场景,可以基于历史会话记录进行回答。llama-index 提供了包括 CondenseQuestionChatEngine, ContextChatEngine 在内的多种的会话引擎。
但是最基础的多轮会话引擎是 CondenseQuestionChatEngine,对应的实现在 llama_index/core/chat_engine/condense_question.py 中,其核心思想很简单:基于多轮的会话记录与当前问题,调用大模型生成一个新问题,基于新问题进行后续处理。对应的实现简化如下:
from llama_index.core import PromptTemplate
from llama_index.core.llms import ChatMessage, MessageRole
from llama_index.core.chat_engine import CondenseQuestionChatEngine
# 默认的重写问题的 prompt
custom_prompt = PromptTemplate(
"""\
Given a conversation (between Human and Assistant) and a follow up message from Human, \
rewrite the message to be a standalone question that captures all relevant context \
from the conversation.
<Chat History>
{chat_history}
<Follow Up Message>
{question}
<Standalone question>
"""
)
custom_chat_history = [
ChatMessage(
role=MessageRole.USER,
content="Hello assistant, we are having a insightful discussion about Paul Graham today.",
),
ChatMessage(role=MessageRole.ASSISTANT, content="Okay, sounds good."),
]
query_engine = index.as_query_engine()
chat_engine = CondenseQuestionChatEngine.from_defaults(
query_engine=query_engine,
condense_question_prompt=custom_prompt,
chat_history=custom_chat_history,
verbose=True,
)
haystack
haystack 提供的方案与 llama-index 类似,在官方示例中 Conversational RAG using Memory 针对多轮会话的问题,实现 query_rephrase_template 模板用于重写查询。对应的 prompt 如下所示:
query_rephrase_template = """
Rewrite the question for search while keeping its meaning and key terms intact.
If the conversation history is empty, DO NOT change the query.
Use conversation history only if necessary, and avoid extending the query with your own knowledge.
If no changes are needed, output the current question as is.
Conversation history:
User Query:
Rewritten Query:
"""
从已有的调研来看,基于历史记录重写查询是一个相对通用而简洁的方案,尝试基于此方案进行后续实践。
实践过程
改造方案选择
在本轮的落地实践中,我们基于 Dify 平台完成。看看如何为现有的 Dify RAG 应用提供多轮会话能力。目前存在两种方案:
- 直接修改 Dify 框架中的知识库检索模块的代码实现。在检索前从数据库中获取历史会话记录,并基于历史会话记录调用大模型重写查询,使用重写后的查询完成知识库检索;
- 利用 Dify 的工作流机制,在工作流中获取历史会话聊天记录,并使用大模型节点重写查询,之后使用重写后的查询进行知识库检索;
方案 1 需要修改 Dify 框架的代码,而且会对服务中所有的已有知识库检索流程产生影响,因此优先选择了方案 2。
方案落地
方案 2 的实现关键是如何在工作流中获取历史会话聊天记录,目前 Dify 没有提供对应的接口,因此需要自行获取。获取不到的情况下,自行保存可能是一个更好的方案。可是历史聊天记录保存在哪里呢?
一番调研后发现,Dify 提供了 会话变量 的机制,从官方的文档描述来看:
会话变量允许应用开发者在同一个 Chatflow 会话内,指定需要被临时存储的特定信息,并确保在当前工作流内的多轮对话内都能够引用该信息,如上下文、上传至对话框的文件(即将上线)、 用户在对话过程中所输入的偏好信息等。好比为 LLM 提供一个可以被随时查看的“备忘录”,避免因 LLM 记忆出错而导致的信息偏差。
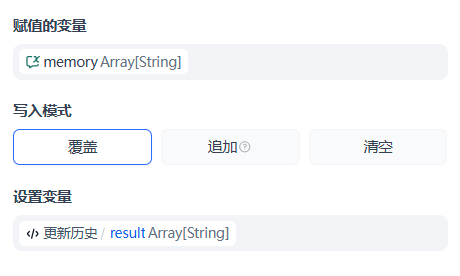
而且会话变量支持字符串数组这种复杂类型,因此相当适合用来保存历史会话记录。可以使用工作流中的变量赋值节点,将当前会话记录以覆盖或追加的方式保存到会话变量中。
实践中考虑到会话的历史记录持续追加可能会超过变量的长度限制。因此使用自定义代码节点 + 变量赋值(覆盖)节点的组合方案,实现最近 3 轮会话记录的保存。对应的代码如下所示:
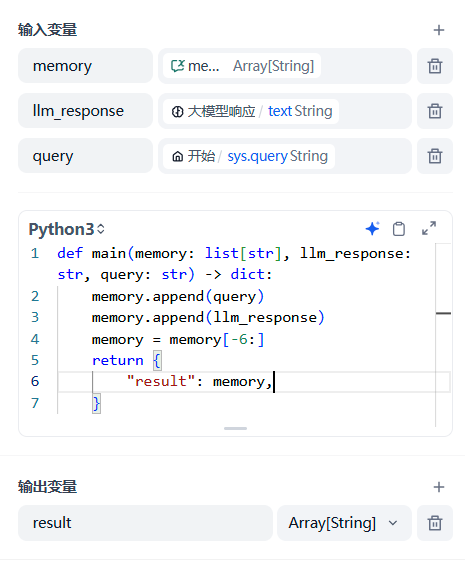
在自定义代码节点后面附加变量赋值节点,将当前会话记录覆盖保存到会话变量中。
为了执行多轮会话的问题重写,需要构造重写查询的 prompt,然后调用大模型节点进行重写。构造 prompt 可以使用自定义代码节点,原始模板直接参考 llama-index 即可,对应的代码如下所示:
def main(memory: list[str], query: str) -> dict:
DEFAULT_TEMPLATE = """\
Given a conversation (between Human and Assistant) and a follow up message from Human, \
rewrite the message to be a standalone question that captures all relevant context \
from the conversation.
<Chat History>
{chat_history}
<Follow Up Message>
{question}
<Standalone question>
"""
chat_history = ""
for idx, msg in enumerate(memory):
role = "user" if idx % 2 == 0 else "assistant"
chat_history += ("\n" if chat_history else "") + f"{role}: {msg}"
prompt = DEFAULT_TEMPLATE.format(chat_history=chat_history, question=query)
return {
"result": prompt,
}
之后将自定义代码节点与大模型节点连接,并使用大模型节点进行重写。
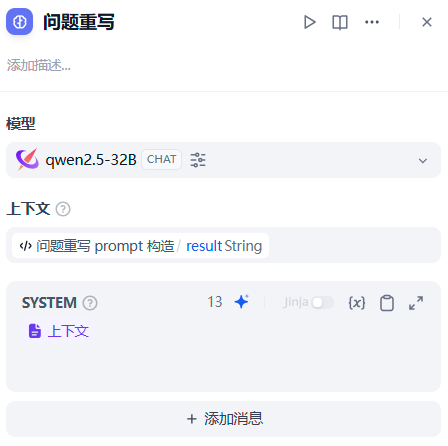
大模型输出的内容即为重写的查询,之后就可以使用重写后的查询进行后续的知识库检索。
最终效果
根据实际线上的问题,测试了应用多轮对话前后的效果差异。在应用多轮对话优化策略之前,当出现用户追问时如果存在上下文信息缺失时,此时往往无法给出正确的答案。
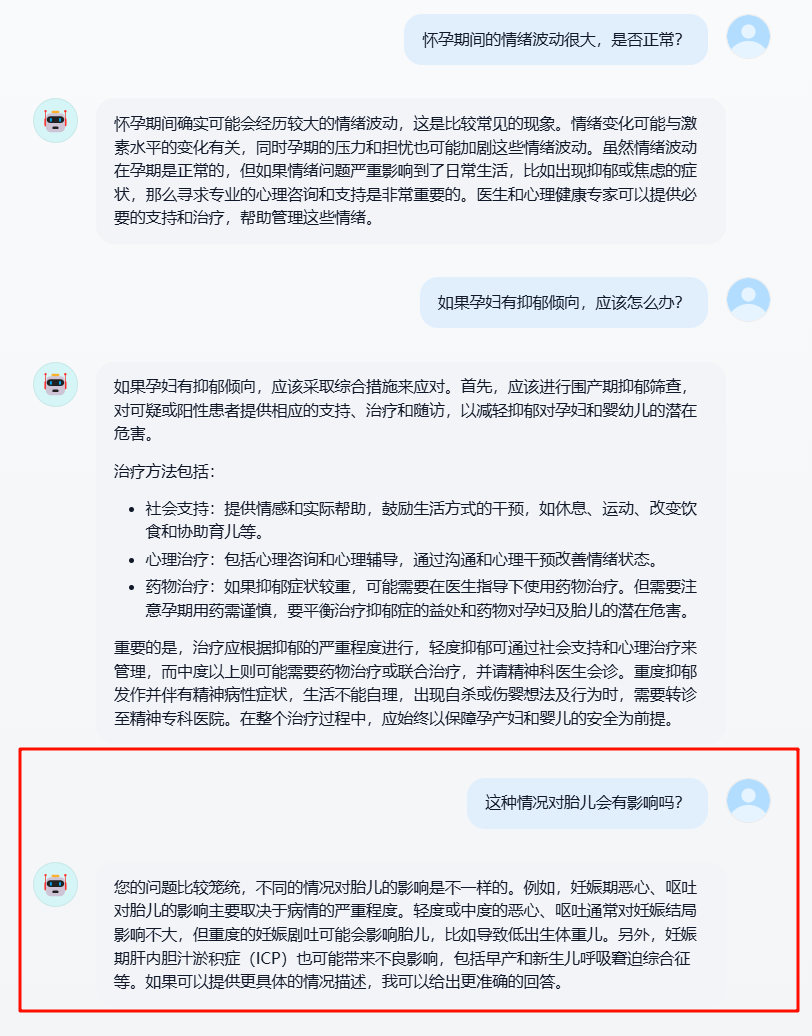
在应用多轮对话优化策略之后,发生用户追问时,基于历史会话记录重写查询,之后使用重写后的查询进行知识库检索,确实可以给出正确的答案。
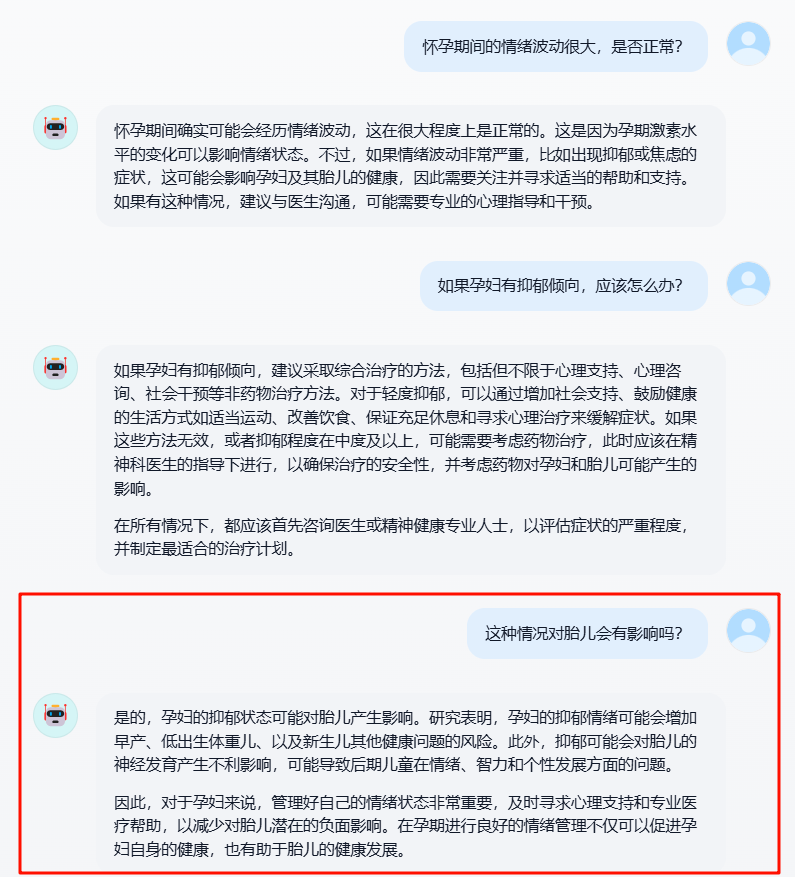
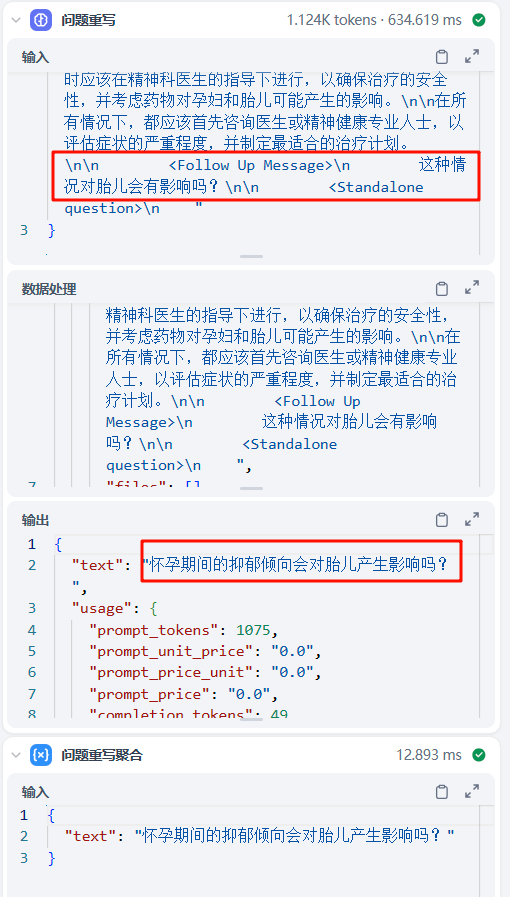
实际跟踪多轮会话的工作流,可以看到在改写阶段,原始问题 这种问题对胎儿有什么影响 被改写为了 怀孕期间的抑郁倾向会被胎儿产生影响吗?,实现了指代消解。
总结
本文介绍了在 RAG 生产实践中容易遇到的多轮对话问题,通过相对简单的基于历史会话记录的查询重写,可以大幅提升大模型 RAG 应用检索异常,从而提升追踪回答的正确性。此方案是一个相当有性价比的优化方案,值得大家尝试。