背景介绍
最近刚刚结束 CCF 的基于运营商文本数据的知识库检索,截止目前成绩还算不错,A榜和B榜排名都比较靠前。因为在比赛中实际是从 0 迭代最终的策略,因此耗时较长。最近在考虑 RAG 是否存在一些最佳实践,在不同的数据集或通用场景下都能取得不错的效果,这样就可以避免从头开始构建策略。
刚好注意到近期有一些相对靠谱的行业进展,AutoRAG 就尝试基于数据集构造 QA 问答对,之后利用定义的指标,寻找最佳的 RAG 策略组合。从 AutoRAG 的视角来看,不同的数据集与问答对可能会存在不同的匹配策略,利用自动化手段可以相对低成本找到合适的策略,想法确实不错。
另外复旦大学的 Searching for Best Practices in Retrieval-Augmented Generation 也是一个很有启发的方案,在论文中作者尝试将 RAG 的各个核心模块拆分开来,尝试去找到各个模块的最佳实践,组合起来就可以得到整体的最佳实践了。之前人大的 FlashRAG 其实也做了类似的模块化 RAG 组合的尝试。
本文就是结合个人实践经验与上述项目的内容,整理目前阶段的 RAG 最佳实践方案,主要分拆为知识库构建与检索阶段进行介绍。
知识库构建
离线构建知识库最核心的功能模块是文件解析和分片,从目前的最新实践来看,还会包含内容的清洗与质量评估。但是影响最大的模块依旧是文件解析与分片机制。
文件解析
文件解析是 RAG 的基础,解析的质量直接决定了后续检索的质量。早期介绍过的 RagFlow 就一直强调文件解析的重要性,“Quality in, quality out” 也很直观体现文件解析的重要性。
从之前的实践来看,结构化解析的效果是明显强于常规的文件内容提取的。相对于常规的文件内容提取,结构化解析保留了文件的层级结构以及各个层级的标题信息,可以有效提升文档内容的召回率。
常规 RAG 文件解析方案为了尽可能提升结构化解析能力,常规情况下会选择实现基础文件类型的结构化解析,其他文件尽可能转换为基础文件类型。而目前最常见适用于结构化解析的基础类型为 html 和 markdown。比如目前最常见的 pdf 格式,热门开源项目 marker 和 MinerU 都在尝试将其转换为 markdown 格式。
针对基础文件类型的结构化解析,在之前的文章 RAG 项目结构化文件解析方案比较 中进行过详细比较。后面又对其中的 SOTA 方案 python-readability + html_text 的技术原理进行了深入梳理。
但是在实践中发现此方案依旧发现不少问题,因此在 SOTA 方案的基础上进行了二次开发,进行了较多的问题修复与功能增强,因此有了开源项目 dify-rag,这个目前是我个人首选的结构化解析方案。
分片
文档的分片策略对最终效果的影响也十分明显,可以选择的分片策略被分为 5 个层级 。从目前来看,语义分片(Semantic Splitting,Level 4)与 Agent 分片(Level 5)效果可能更好,但是需要大模型处理原始文本,耗时过久,成本过高。而常规的字符长度分片(Level 1)可能会导致句子被切断,严重影响检索效果。
从目前实践来看,按照递归字符切换(Recursive Character Text Splitting,Level 2)通用性最好,而且效果还不错。特定类型的文件可以实现对应格式的文件切分方法(Document Specific Splitting,Level 3),比如结构化解析的文档可以根据标题层级进行切分,保证信息的完整性,以 html 类型为例,实践中一般会按照 h1 ~ h3 进行切分。
分片长度的效果比较在论文中使用 lyft_2021 进行了验证,具体的结果如下所示:
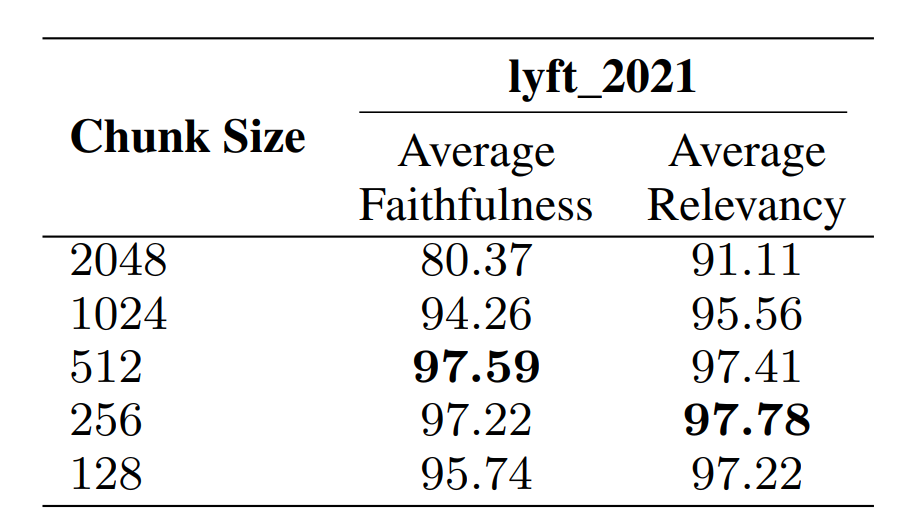
一般情况下建议的分片长度为 256 ~ 512,这个长度与我实践使用的感受相对一致,一般情况下建议在这个长度范围内进行尝试。论文中使用的重叠长度为 20,从个人经验来看,为了提升召回率和准确性,可以适当增加重叠区域,虽然这样会带来额外的存储的开销。
向量模型
向量模型直接决定文档是否能被正确召回,因此选择合适的向量模型对最终的效果影响十分明显。在论文中比较了常见的向量模型,具体的结果如下所示:
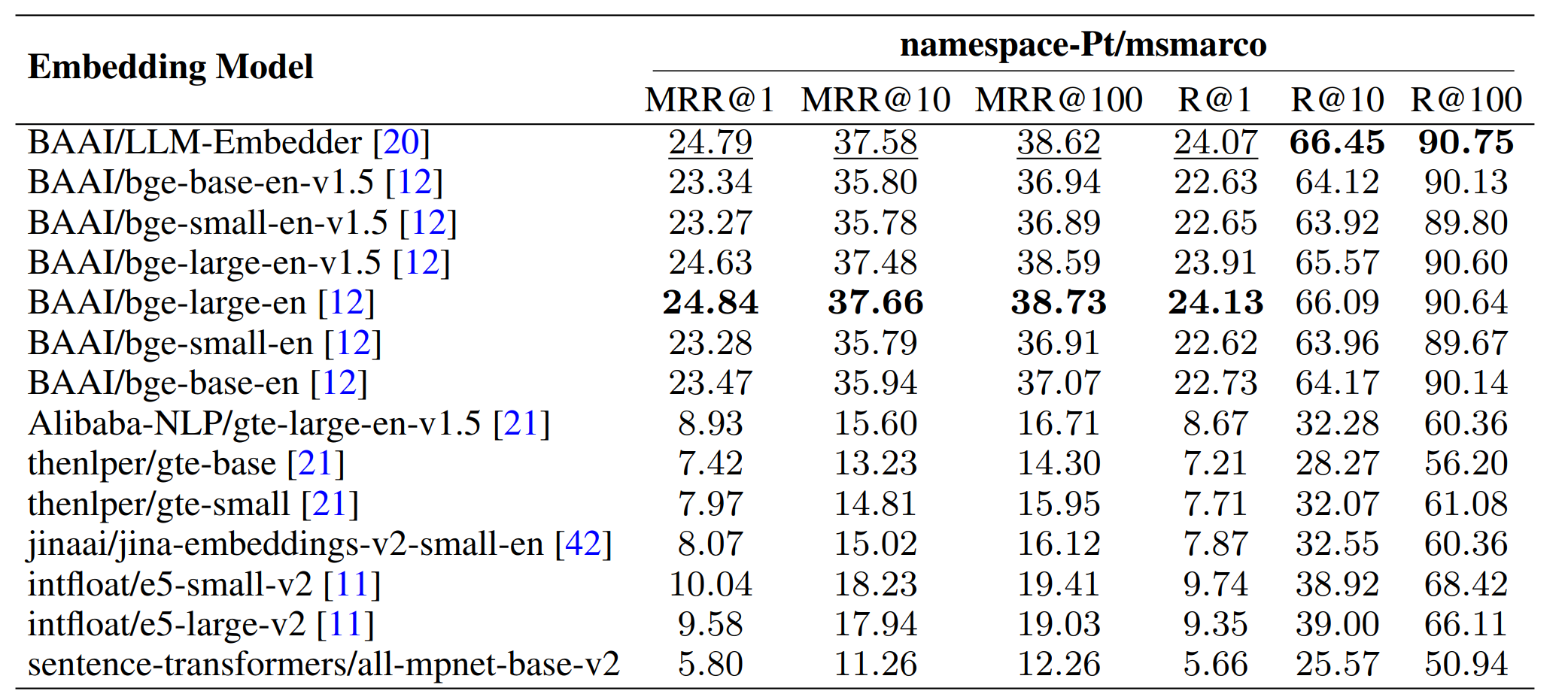
最终论文中选择了 LLM-Embedder, 因为效果相对好,而且成本相对低。从个人实践来看以及目前开源社区的反馈来看,bge-m3 是一个针对生产环境更友好的选择,效果良好,支持中英双语,而且支持 32K 的上下文。
如果追求更极致的效果,可以尝试 gte-Qwen2-7B-instruct,这个模型是基于大模型微调而来,效果预期更好,但是大小约为 28G,成本较高。
向量数据库
向量数据库用于存储转换生成的向量,支持高效的向量检索。论文从是否支持多种索引类型、十亿级向量支持、是否支持混合搜索和云原生支持维度比较了常见的向量数据库,具体的结果如下所示:
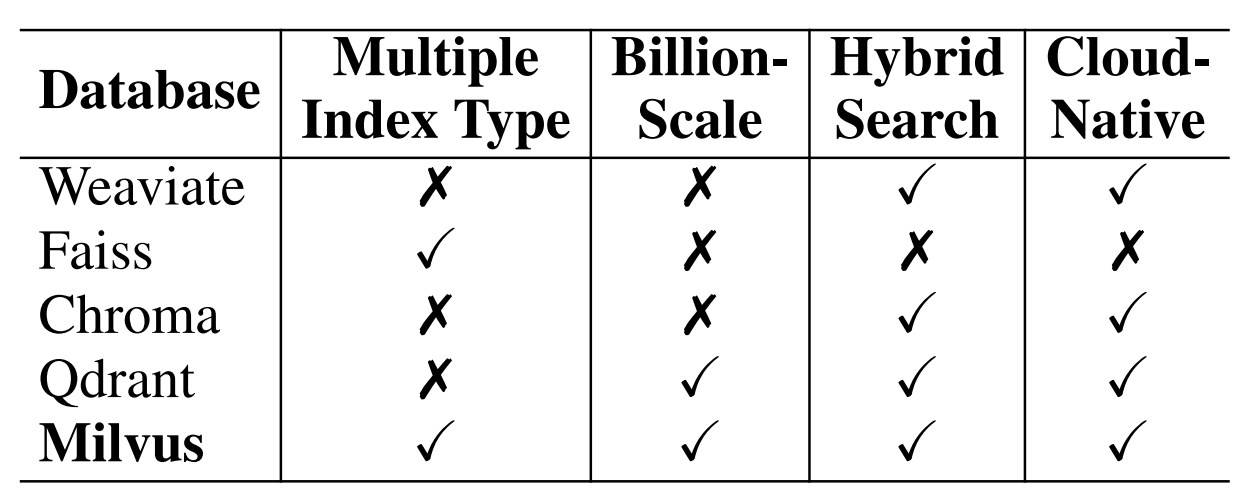
从结果来看,Milvus 在多个维度都表现不错,一般情况下是一个相对不错的选择。
检索阶段
在实际的检索阶段,按照 AutoRAG 中梳理的详细的检索流程如下所示:
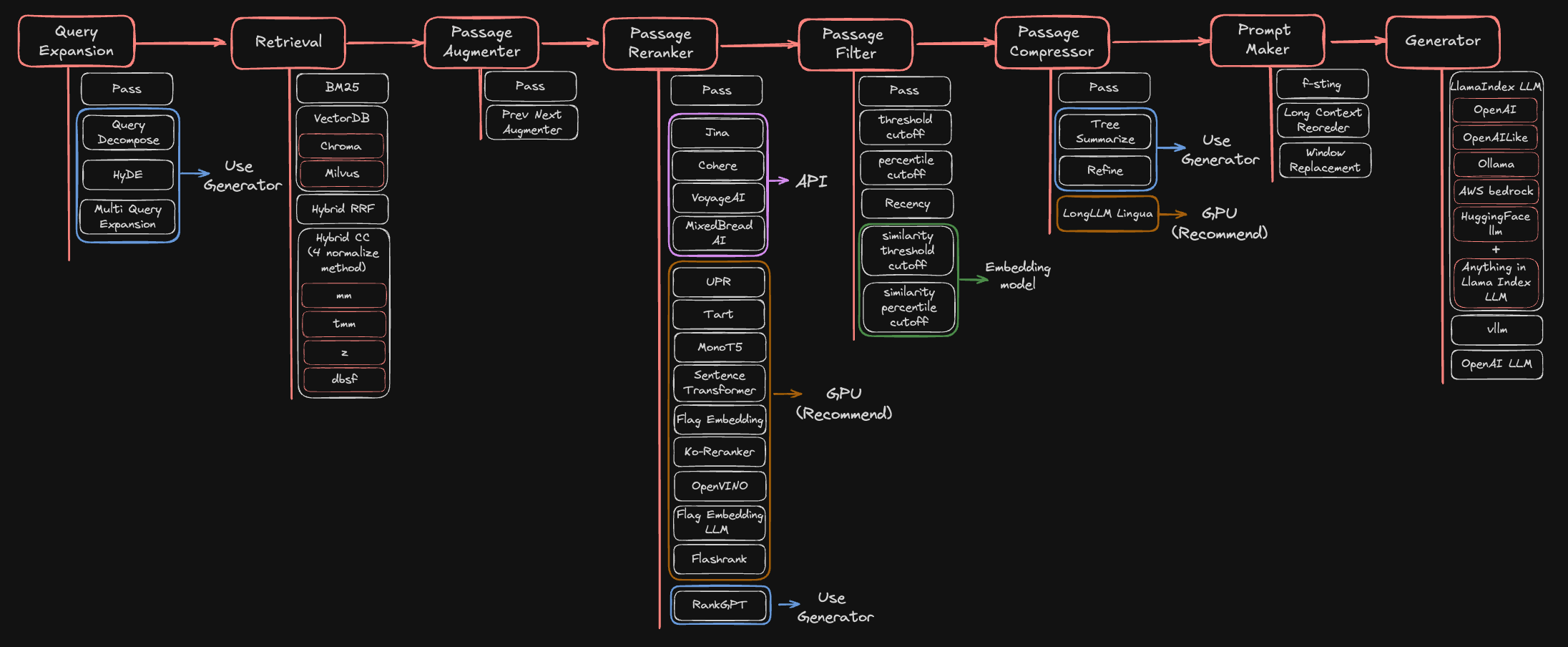
下面按照模型化的形式介绍其中核心模块的最佳实践,注意其中最核心的检索和生成是 RAG 中必不可少的环节,其他模块可以根据实际的需求进行自由选择。
查询扩展(query expansion)
在实践过程中经常会发现,原始的查询可能不适合用于检索,具体的原因多种多样:
- 原始查询可能意图不明确;
- 原始查询语句过于复杂,包含多个子问题,整体难以检索或只能得到召回部分信息;
- 原始问题与知识库中的文档存在语义差异,导致召回的文档不匹配;
而不同的问题可能需要采取不同的策略进行处理。在论文中基于 TREC DL19/20 数据集针对通用场景比较了常见的几种检索扩展策略,对应的结果如下所示:
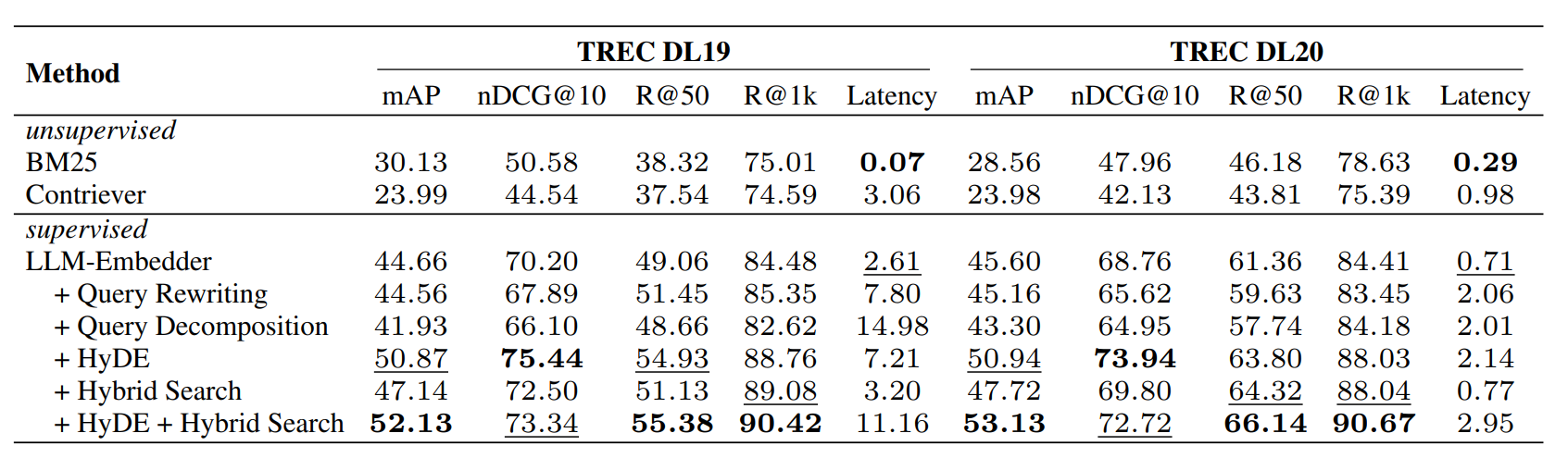
从当前测试的数据来看,HyDE 相对 Query Rewriting 和 Query Decomposition 而言表现更好。但是从我实践的情况来看,大部分情况下并不能无脑选择 HyDE 策略,比如之前整理的 AIOps RAG 比赛 中,HyDE 的表现反而不如原始问题查询,具体效果差异根据自己的实际场景选择。
检索
从之前实践的情况来看,单纯的向量检索往往是不够的,而单纯的 BM25 一般也无法满足要求。因此目前 RAG 的检索方案一般都是使用混合检索。而且目前的生产环境使用的向量数据库基本都内置了混合检索的能力,导致混合检索实现的门槛也大幅降低,因此当前阶段混合检索基本成为标配方案了。
混合检索下需要确定如何进行多路结果的融合,可以选择基于多路相似分的加权和,也可以选择基于 RRF 的多路融合策略。从实现简单与通用性的角度来看,一般建议选择 RRF 方案。
检索增强(Passage augmenter)
为了提升检索的召回率,检索的分片长度一般建议在 256 ~ 512 之间。但是实践中经常会发现,原始的分片长度经常无法完整包含问题所需的信息,因此最终的答案往往不完整。为了避免这个问题,可以考虑对检索召回的文档进行扩充。
目前文档扩充方案最常规的方案是父子检索(small-to-big),即使用长度较短子片进行检索,之后实际使用的子片对应的父片。除了父子检索之外,llama-index 也实现了 Forward/Backward Augmentation ,实际是通过在检索节点之前之后扩张现有文本内容,避免信息不完整,整体思想大同小异。
从目前来看,父子检索应用相对广泛,可以缓解信息不完整问题,但是父片依旧可能无法完全包含完整的信息,而且过大的父片可能存在信息冗余,暂时还没有完美解决这个问题的方案。
重排序(Passage Rerank)
从之前的 QAnything 的调研就发现,Rerank 对 RAG 检索准确性的提升十分明显,在实践中也很容易感受到这种差异,因此目前的 RAG 方案中 Rerank 基本成为标配方案了。
当前的问题就是如何选择 Rerank 模型,在论文中进行了不同类型的 Rerank 模型的比较,具体的结果如下所示:
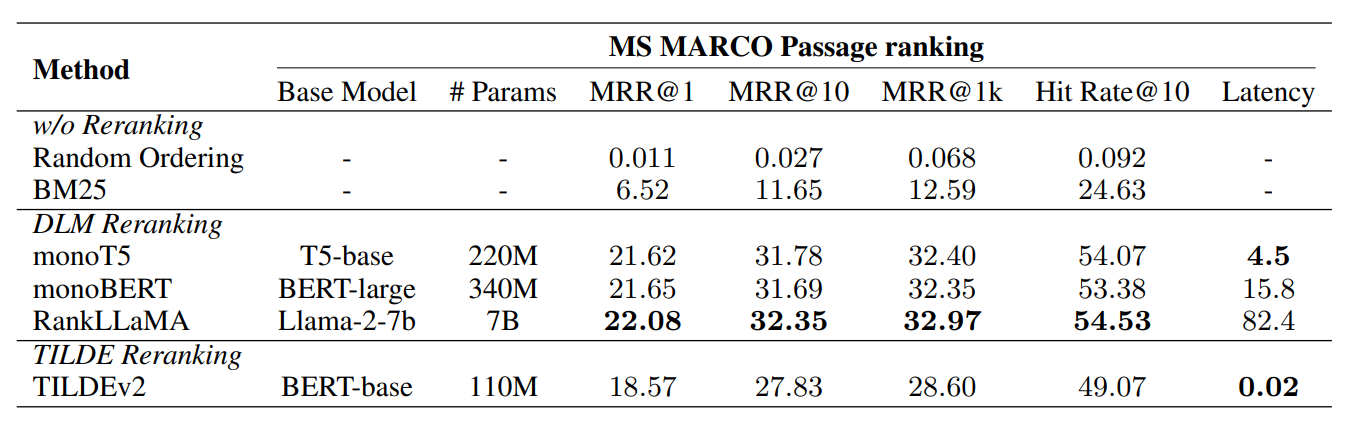
论文从平衡性能和效果的角度推荐使用 monoT5。从我实践的情况来看,bge-reranker-v2-m3 是一个在生产环境相对不错的选择,如果追求更好的效果,我实际建议的方案与之前 AIOps RAG 比赛 一致,建议使用使用基于 LLM 的 Rerank 模型 bge-reranker-v2-minicpm-layerwise。
检索过滤(Passage Filter)
检索结果的过滤主要用于去除无关的文档,目前实践中主要采用两种方案:
- 基于相似度阈值过滤,低于相似度阈值的文档被认定为不相关直接过滤掉;
- 基于文本长度限制过滤,因为最终大模型可以支持的输入上下文是有限,因此选择 topN 的相似文档;
从个人实践来看,我一般会选择结合两者,基于较小的相似度阈值过滤掉完全无关的文档,再基于 topN 避免上下文过长。这样保证完全不相关的文档会被过滤掉,同时也能避免存在较多相关文档时上下文过长。
检索压缩(Passage Compressor)
检索压缩主要用于对检索匹配的上下文进行压缩,去除与问题无关的上下文,这样可以有效提升上下文信息密度,降低无关信息的干扰,同时提升大模型推理速度和质量。在论文中主要比较了 Recomp , LongLLMLingua 和 Selective Context 三种方案,具体的结果如下所示:
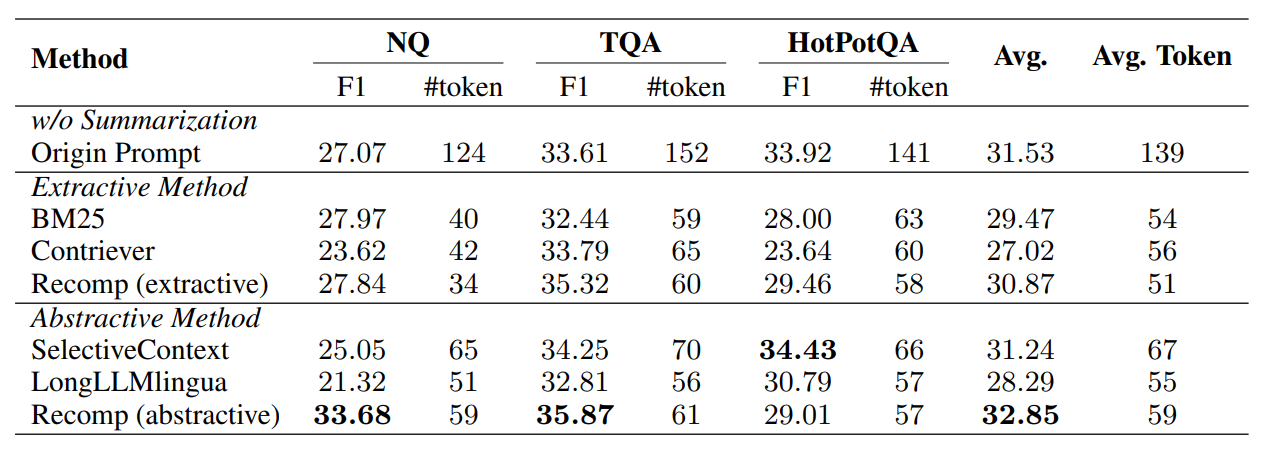
在论文中的结果来看,Recomp 的效果相对更好。在 AIOps RAG 比赛 中实现了一个基于 BM25 的检索压缩方案,我在实践中进行了测试,效果不是特别理想。实际参考 AIOps RAG 比赛中的方案,将 BM25 评分替换为 Rerank 评分,可以取得更好的效果,当然成本也会更高。
结果生成(Generator)
在最终使用大模型生成答案时,如何组织检索的多个文档对结果也存在一些影响,一般会按照相似度进行正序或逆序排列,但是考虑到 Lost in middle 效应,存在另一种方案,将检索的相关性高的文档排在两边,相关性低的文档排在中间。论文中对这三种方案进行了比较,具体的结果如下所示:

从论文的结果来看,对效果的影响相对有限,我猜测可能是因为检索实际匹配的文档数量有限,Lost in middle 效应的影响没那么明显,而且目前大模型的也越来越强,导致 Lost in middle 的效应越来越不明显了。
总结
本文是基于复旦大学的论文,AutoRAG 以及个人的实践经验模块化梳理了当前 RAG 的最佳实践方案,按照这个模块化的方案可以相对低成本组装出一个不错的 RAG 方案,当然实践中依旧需要根据具体场景进行小幅调优,但是已经是一个相对良好的基础方案了。