背景介绍
最近抽空参与 CCF 的 RAG 比赛,系统性对 RAG 检索中多种多样的检索优化方案进行了测试和对比,也发现了不少之前没有注意到的优化细节。从目前的实践来看,比赛确实是一个绝佳策略测试场所,很公平地对不同的优化方案进行了客观比较。实践中不时会发现直观感觉很有效的策略不生效,有些看起来平平无奇的策略反而效果绝佳。根据结果反向分析策略,更容易理解不同策略背后的适用场景和优劣,也可以帮助认识自己技能的盲区。
最近几天刚好看到 AIOps RAG 比赛的获奖方案 EasyRAG, 此方案在 AIOps RAG 初赛获得 top1, 复赛获得 top2,相关的实现也开源在 Github, 抽空研究了相关的论文与实现,整理相关内容在这边。
整体方案
整体方案如下所示:
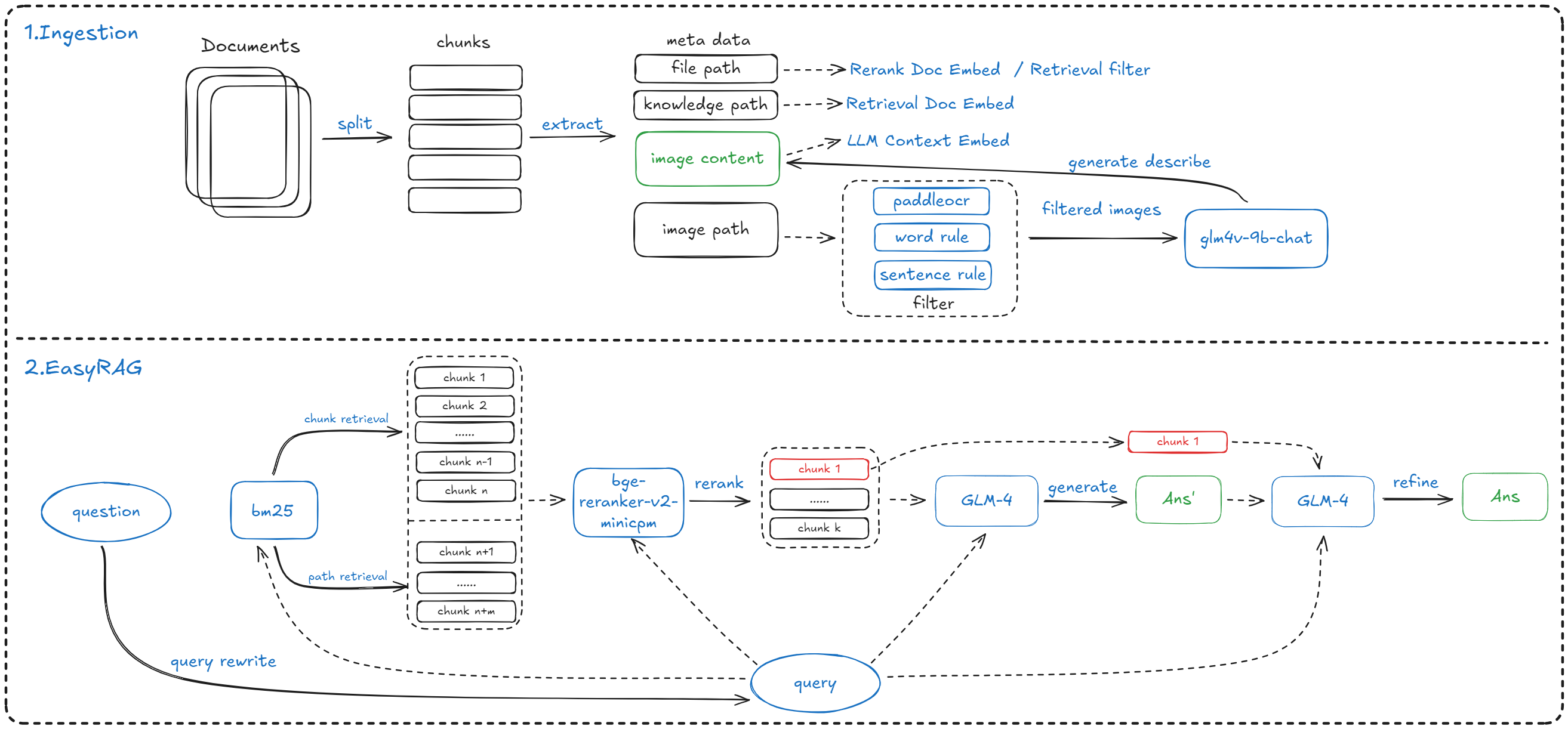
从图中可以看到,整体的方案主要包含分为两部分:
- 索引构建阶段(Ingestion): 整体流程与常规方案基本一致,额外有两个不同之处:一是包含了文档元信息的使用,二是对图片进行了 OCR 提取并过滤,使用多模态大模型 GLM-4V-9B 生成了对应的描述信息入库;
- 检索阶段(EasyRAG): 使用的是检索 + 重排序 + 答案优化的方案,重排序使用 bge-reranker-v2-minicpm-layerwise 模型。与常规 RAG 方案相比,有一个明显不同在于使用 LLM 先生成了初始答案,之后使用检索的 Top1 文档对结果进行了额外的优化;
整体的框架基于 llama-index 实现。从目前来看,llama-index 是一个比较优秀的 RAG 基础框架,可以帮助快速搭建 RAG 服务,感兴趣的同学可以深入了解下。
下面主要对 EasyRAG 中的部分技术细节进行介绍,感兴趣的还是推荐查看 原始论文 与 Github。
索引构建
文件切片与构建
本项目使用的是 SentenceSplitter 进行文档切分,首先使用中文标点符号切分成句子,然后根据设置的文本块大小进行合并。使用的块大小(chunk-size)为1024,块重叠大小(chunk-overlap)为 200。为什么会选择这个长度,是根据数据集实际测试出来的。不同的数据集可能适合不同的方案,大家可以根据自己的数据集测试选择合适的值。
在构建的分片中,EasyRAG 将元信息加入分片中,提升检索的召回率。目前使用的元信息为知识库路径,文件路径等信息。从实际测试的情况来看,补充元信息带来了 2% 的准确性提升。
在实践中发现加入元信息后 llama-index 计算块大小和重叠大小存在一定的问题,因此手工实现了 SentenceSplitter 修复了相关问题,具体的实现可以查看 Easyrag splitter。
检索阶段
查询 Rewrite
对原始的查询进行重写是一个常规做法,解决的主要是原始查询难以检索的问题。主要尝试了下面两种方案:
-
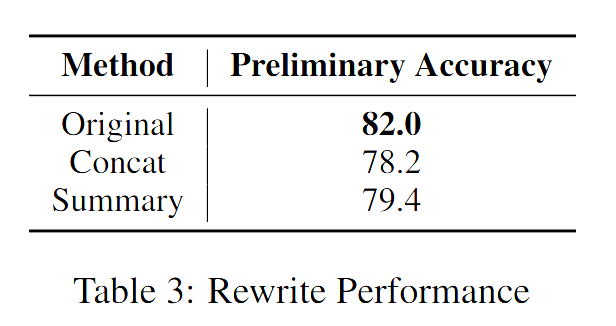
考虑到查询中关键词比较重要,使用 LLM 提取问题中的关键词,之后进行关键词的扩展,然后使用 LLM 重写原始查询,实际效果反而准确性下降,具体对比如下所示:
-
设计了一个优化版本的 HyDE, 这个从描述来看还是比较有意思的。具体流程如下所示:
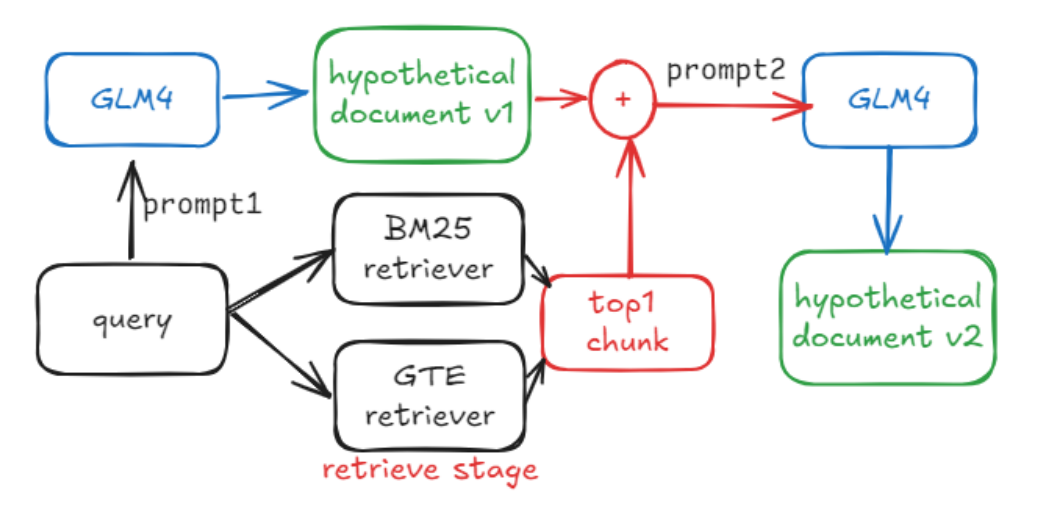
HyDE 希望解决的问题与文档中的答案相似性较低的问题,但是常规问题使用 HyDE 生成时很容易生成大量不相关的冗余信息,从而会导致检索效果很差。因此在上面的流程中,HyDE 的文档与检索获得的 Top1 的文档结合起来,生成更符合实际知识库的假设文档,从直觉上应该可以缓解原始 HyDE 的问题。实际测试依旧效果不佳:
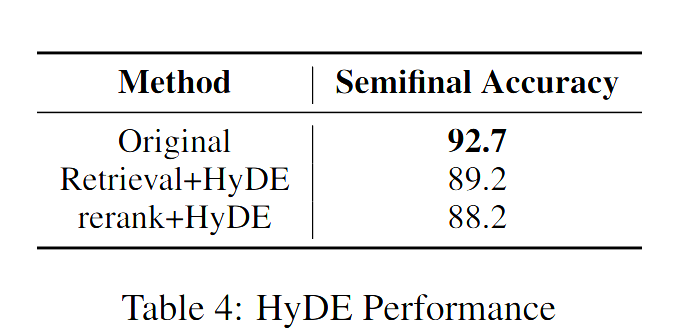
而且将 HyDE 生成的文档用于检索和重排序效果都不如直接使用原始问题。感觉这个方案有点类似 RAG + R 的方案,特定场景下相对原始的 HyDE 可能会有一些提升,后续可以进行一些尝试。
文档检索
文档检索使用的是双路的 BM25 检索 + 向量检索的方案。其中双路 BM25 检索包含文档块检索和路径检索。下面是实际使用的一些优化策略:
- BM25 检索前过滤掉了常见中文停用词,通过过滤掉不相关的单词和特殊符号,提高有效关键词的命中率,从而提高正确文档的召回率。过滤使用的是哈尔滨工业大学搜集的停用词;
- 向量化使用的是 gte-Qwen2-7B-instruct, 这是基于大模型微调生成的向量化模型,在各个榜单上表现都不错;
- BM25 检索召回 192 个,向量检索召回文档数量为 288 个,通过过度召回 (OverFetch) 保证信息的完整性,后续可以利用重排序模型保证信息的准确性,牺牲时间换取准确性;
- 使用文档路径比较元信息,过滤不相关的文档块。一个典型的利用元信息进行过滤的优化;
重排序
实际测试了多种重排序模型,最终发现基于 LLM 构建的模型 bge-reranker-v2-minicpm-layerwise 效果最好,这个和我们实际测试的发现是相符的。实际测试的结果如下所示:
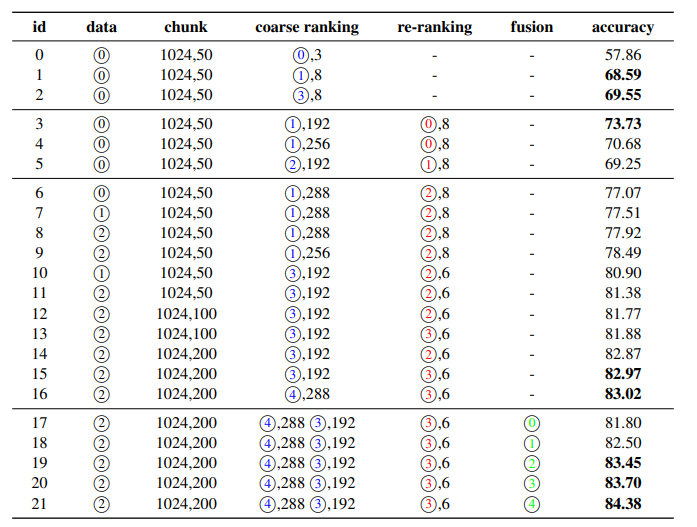
可以关注 re-ranking 列,其中使用的模型编号如下所示:
- 0 表示的是 bge-reranker-v2-m3
- 1 表示的是 bce-reranker-base_v1
- 2 表示的是 40 层的 bge-reranker-v2-minicpm-layerwise
- 3 表示的是 28 层的 bge-reranker-v2-minicpm-layerwise。
从实际的数据来看:
28 层 bge-reranker-v2-minicpm-layerwise > 40 层 bge-reranker-v2-minicpm-layerwise > bge-reranker-v2-m3 > bce-reranker-base_v1,这个结果和我们在其他数据集上的测试结果是相符的。
多路结果融合
由于采取了多种方式的混合检索,因此需要多路结果进行融合,实际尝试的方案如下所示:
- 基于 RRF 将重排序的结果进行融合;
- 将各路线的文本块输入到LLM中,得到各自的答案,选择较长的答案作为最终答案;
- 将每条路线的文本块输入到LLM中,得到各自的答案,并将所有路线的答案直接串联起来。
上面的方法对应于下面融合策略中 2,3,4 号策略,可以看到对结果的影响很有限,从可靠性和通用性来说,一般情况下还是推荐使用 RRF。
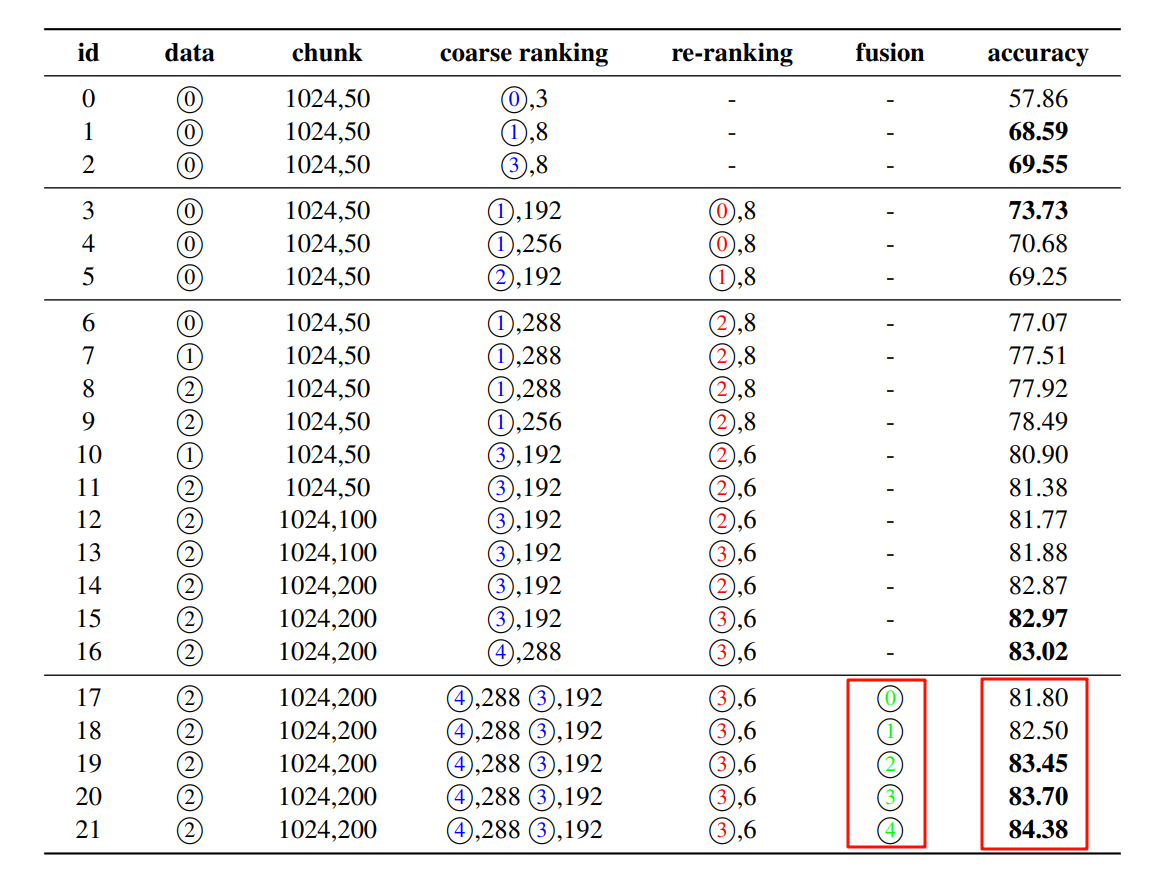
答案优化
由于 RAG 检索生成答案时一般会提供多个文本块,此时大模型会根据多个文本块的内容生成答案。
实际测试发现很多情况下对 Top1 的答案的重视层度不够,因此 EasyRAG 将大模型基于 Top6 的文本块生成初始答案,之后将初始答案与 Top1 的文本块进行合并,再通过大模型进行总结,得到最终的答案。实际测试发现这个方案准确性上提升了 2% 。
这个方案应该与比赛预期可能会有一些效果,因为比赛很多时候答案都在特定块内。如果 Rerank 比较优秀,往往 Top1 就是预期答案,但是对于常规情况下是否有改善,还需要进一步验证。
上下文压缩优化
常规情况下检索获得的上下文长度过长,为了提升推理速度可以对上下文进行压缩。
EasyRAG 采取的是基于 BM25 的压缩方案,实现方案比较简单:将检索的内容拆分为句子,然后使用 BM25 计算查询与每个句子之间的相似度,最后按照相似度递减的顺序将句子添加到列表中,直到达到设定的压缩率。实际与 LLMLingua 进行了比较, 从结果来看还是不错的:
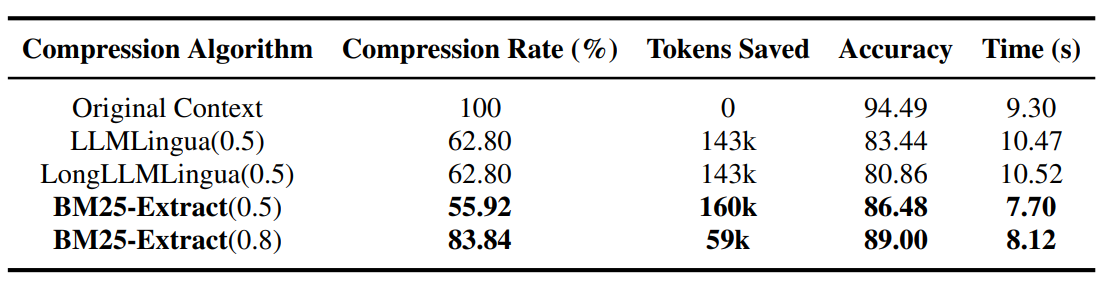
但是常规文本下是否能达到这个准确性有待进一步验证。不过实现还是比较简单的,就是一个简单的分拆,评分与组合,值得尝试下:
pre_len = len(context)
raw_sentences = cut_sent(context)
sentences = []
for raw_sentence in raw_sentences:
raw_sentence = raw_sentence.strip()
if raw_sentence != "":
sentences.append(raw_sentence)
# 获取query与每个句子的BM25分数
scores = self.bm25_retriever.get_scores(query, sentences)
# 按原句子相对顺序拼接分数高的句子,直到长度超过原长度的rate比例
sorted_idx = scores.argsort()[::-1]
i, now_len = 0, 0
for i, idx in enumerate(sorted_idx):
now_len += len(sentences[idx])
if now_len >= pre_len * self.rate:
break
sorted_idx = sorted_idx[:i + 1]
sorted_idx.sort()
new_context = ""
for idx in sorted_idx:
new_context += sentences[idx]
return new_context
总结
本文是对 EasyRAG 方案的整体介绍,此方案集成了不少 RAG 的优化策略。虽然整体策略还是偏向竞赛场景,可能会存在以效率换取准确性,导致生产环境无法直接使用。但是整体还是有不少的启发,值得在生产环境进行一些尝试。