背景介绍
在之前的软件应用中,我们总会在应用中保留大量的用户历史操作记录,方便用户下次使用时可以快速查看和复用,甚至基于这些用户记录可以为用户提供个性化的服务。而这些记录往往都保存在传统的结构化或非结构化数据库中。
在大模型的应用,特别是助手类的大模型应用中,我们往往需要处理大量语义化的文本或多模态的信息,方便后续快速匹配,从而提供个性化的服务。为了支持这种语义检索的需求,往往会将数据保存至向量数据库中。
向量数据库执行语义检索相对方便,但是包含语义内容的文本管理比较困难,特别是涉及到相关内容的更新和替换。在这种背景下,Mem0 应运而生。Mem0 可以给大模型应用提供智能记忆层,可以记住用户偏好,适应个人需求,并随着时间的推移不断改进,从而方便应用提供更加个性化的体验和服务。

从开源依赖,Github 上的 star 数量一路飙升,截止目前已经 20.6k 的 star 了。
上手体验
Mem0 提供了两种接入方案,一种是使用官方的托管平台,另一种是使用官方提供的 python 依赖包 mem0ai执行。下面以本地依赖包形式了解下 Mem0 的使用。
依赖配置
首先需要通过 pip 安装所需的依赖包:
pip install mem0ai
Mem0 需要依赖大模型才能执行,默认使用的 gpt-4o, 因此需要配置对应的 ChatGPT API 秘钥,需要将秘钥配置至环境变量中:
import os
os.environ["OPENAI_API_KEY"] = "sk-xxx"
动手实践
Mem0 实际使用在大模型应用中,我们主要关注下面的能力:
- 针对特定用户添加非结构化的文本信息;
- 特定用户根据查询问题进行文本检索;
针对上面的关注的能力,使用 Mem0 可以简单满足需求:
from mem0 import Memory
# 初始化记忆对象
m = Memory()
# 1. 针对特定用户添加非结构化的文本信息
result = m.add("I am working on improving my tennis skills. Suggest some online courses.", user_id="alice", metadata={"category": "hobbies"})
# 2. 特定用户根据查询问题进行文本检索
related_memories = m.search(query="What are Alice's hobbies?", user_id="alice")
可以看到常规的功能使用比较简单,看起来几行代码就可以快速为大模型应用加上“记忆”。
实现方案
官方方案概述
首先可以从官方描述中大致了解 Mem0 的实现方案,从官方文档了解到下面的信息:
Mem0 利用混合数据库方法来管理和检索人工智能代理和助手的长期记忆。每个内存都与一个唯一的标识符相关联,例如用户 ID 或代理 ID,允许 Mem0 组织和访问特定于个人或上下文的内存。
当使用 add() 方法将消息添加到 Mem0 时,系统会提取相关事实和偏好并将其存储在数据存储中:矢量数据库、键值数据库和图形数据库。这种混合方法可确保以最有效的方式存储不同类型的信息,从而使后续搜索快速有效。
当人工智能代理或LLM需要回忆记忆时,它会使用 search() 方法。然后 Mem0 在这些数据存储中执行搜索,从每个源检索相关信息。然后,该信息通过评分层,根据相关性、重要性和新近度评估其重要性。这确保了只显示最个性化和最有用的上下文。
可以大致了解到 Mem0 是基于混合数据库来管理,同时支持向量、键值和图形数据库,但是具体的实现细节依旧不清楚,这种情况下 Talk is cheap, show me the code.,下面我们通过源码来了解 Mem0 的实现方案。
方案深入解析
文本检索
Mem0 中的文本检索是通过调用 Memory.search() 方法实现,文本检索的主要流程如下所示:
- 检索文本向量化,构造过滤条件,方便基于用户 id 等进行过滤;
- 基于向量数据库进行检索和过滤,默认使用的向量数据库为 Qdrant;
- 可选基于知识图谱的检索(从 v1.1 开始支持);
从上面的流程来看,主流程就是简单的向量检索,同时利用向量数据库提供的元信息过滤的能力进行用户区分的封装,实现如下所示:
filters = filters or {}
if user_id:
filters["user_id"] = user_id
if agent_id:
filters["agent_id"] = agent_id
if run_id:
filters["run_id"] = run_id
# 查询向量化
embeddings = self.embedding_model.embed(query)
# 向量检索
memories = self.vector_store.search(
query=embeddings, limit=limit, filters=filters
)
# 可选的知识图谱检索
if self.version == "v1.1":
if self.enable_graph:
graph_entities = self.graph.search(query)
文本添加
Mem0 中非结构化文本添加是通过调用 Memory.add() 方法实现,文本添加的主要流程如下所示:
- 将添加的文本进行向量化,从向量数据库中检索相关内容;
- 将检索的相关内容与新增的文本提供给大模型,大模型判断所需采取的动作列表,可选动作包含
新增文本,更新原有的文本,删除原有文本; - 根据大模型给出的动作列表依次执行;
可以看到上面的流程中主要基于大模型提供的能力处理历史信息的更新问题,对应的实现如下所示:
# 从向量库中检索已有的文本内容
embeddings = self.embedding_model.embed(data)
existing_memories = self.vector_store.search(
query=embeddings,
limit=5,
filters=filters,
)
# 转换检索到的文本内容,构造成特定格式,方便调用大模型
existing_memories = [
MemoryItem(
id=mem.id,
score=mem.score,
metadata=mem.payload,
memory=mem.payload["data"],
)
for mem in existing_memories
]
serialized_existing_memories = [
item.model_dump(include={"id", "memory", "score"})
for item in existing_memories
]
messages = get_update_memory_messages(
serialized_existing_memories, extracted_memories
)
# 调用大模型,确定需要采取的动作列表
tools = [ADD_MEMORY_TOOL, UPDATE_MEMORY_TOOL, DELETE_MEMORY_TOOL]
response = self.llm.generate_response(messages=messages, tools=tools)
tool_calls = response["tool_calls"]
response = []
if tool_calls:
available_functions = {
"add_memory": self._create_memory_tool,
"update_memory": self._update_memory_tool,
"delete_memory": self._delete_memory_tool,
}
# 依次执行动作列表,可选动作为 `新增文本`, `更新原有的文本`, `删除原有文本`
for tool_call in tool_calls:
function_name = tool_call["name"]
function_to_call = available_functions[function_name]
function_args = tool_call["arguments"]
if function_name in ["add_memory", "update_memory"]:
function_args["metadata"] = metadata
function_result = function_to_call(**function_args)
response.append(
{
"id": function_result,
"event": function_name.replace("_memory", ""),
"data": function_args.get("data"),
}
)
可以看到此流程主要依赖大模型的判断能力,利用常规向量库的 CRUD 作为基础操作,实现一个有语义的文本向量更新。
为什么需要做这么复杂,而不是直接插入向量数据库呢?可以参考官网提供的一个简单的例子:
用户 Alice 先插入了两条记录 I like going to hikes 和 I love to play badminton,此时的关系如下所示:
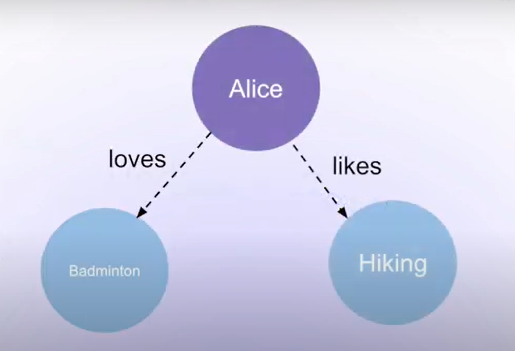
当 Alice 隔一段时间不再喜欢羽毛球,新增了 I do not like badminton any more, 此时预期的关系应该更新为如下所示:
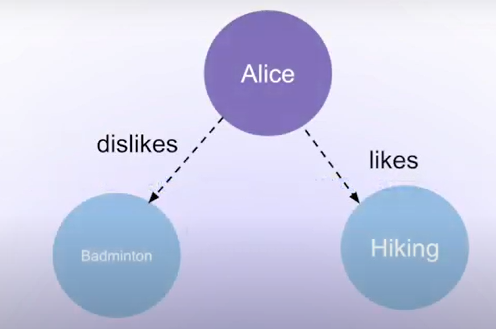
此时更符合语义的新增方案是更新原有的文本,如果直接插入,则 Alice 可能会关联到两条互相冲突的记录,最终导致可能出现判断问题。
总结
本文是对 Mem0 的实现方案的探索,可以看到 Mem0 提供了一套比较友好的记忆管理接口,可以方便地检索和更新相关的信息,比较适配于大模型应用的场景。
从实现原理上来看,Mem0 主要基于向量数据库实现了相关内容的检索,在文本的更新上,基于大模型进行历史信息的判断,通过组合向量数据库的基础 CRUD 能力,实现了一个有语义的文本更新能力流程。
当然新版本的 Mem0 开始引入了知识图谱进行文本的管理,有兴趣也可以详细了解下。