背景介绍
在之前的文章 来自工业界的开源知识库 RAG 项目最全细节对比 中介绍过,现有 RAG 开源项目中,Dify 的生态良好,但是一个明显的短板就是 RAG 检索能力偏弱。因此一直期望能补全这个短板,从而让 Dify 能真正好用起来。
在 基于开源项目二次开发建议方案 探索了 Dify 的增强策略。实际选择了文章中提到的中策,基于模块化增强 Dify。做出这个选择的主要原因如下:
- Dify 的 RAG 已经支持了大量的 RAG 基础能力与可视化页面,如果通过额外的插件拓展支持,那么现有的 RAG 基础流程无法复用,开发的工作量太大。
- 通过插件机制需要整体完成后上线,无法渐进式增强;
最终选择牺牲了部分可维护性,大幅减少开发成本。
方案设计
整体的方案是通过模块化组件替换 Dify 原有的基础模块,逐步替换为更强的 Dify-RAG 模块,从而提升 Dify 的 RAG 能力。简单的 Dify RAG 模块化结构如下所示:
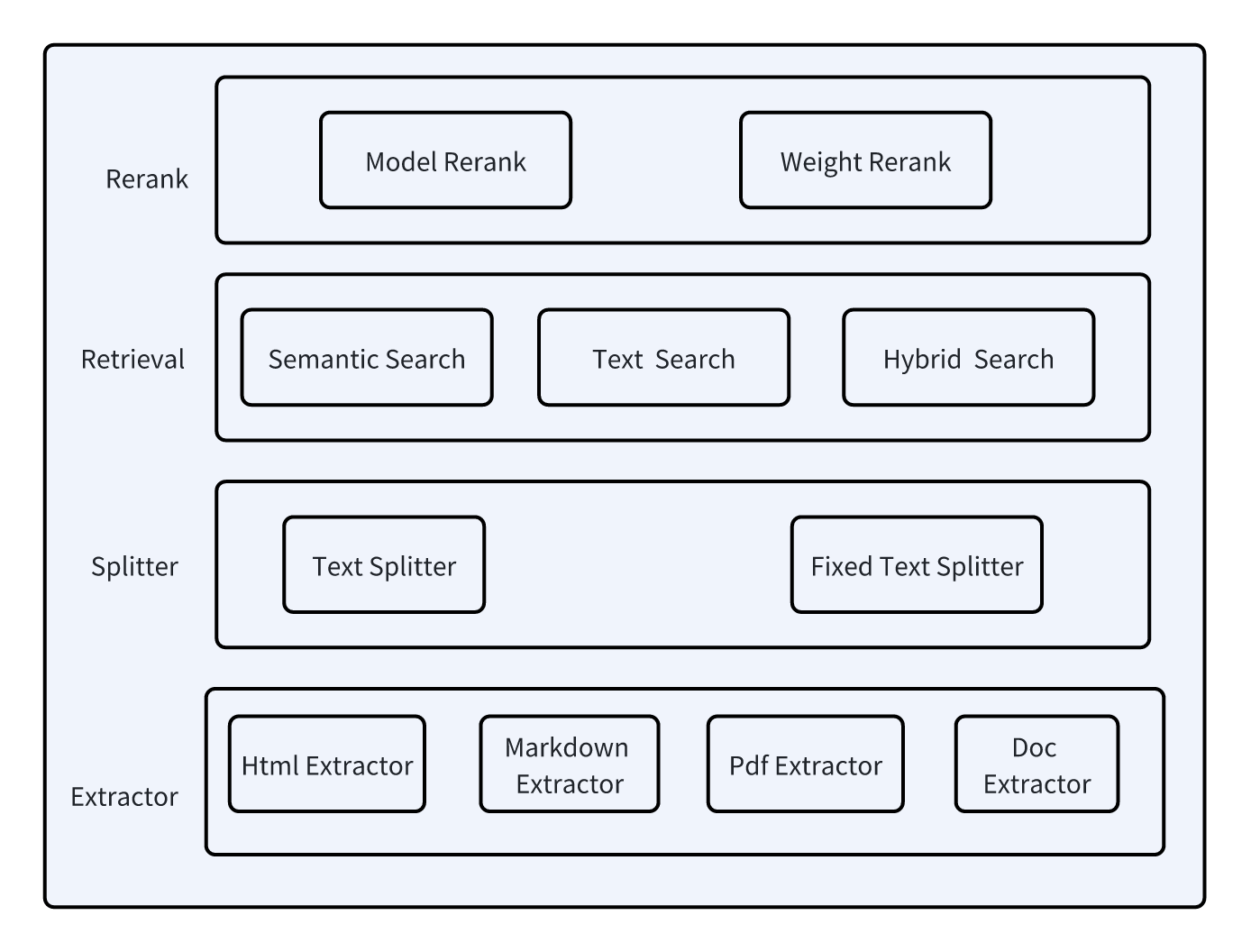
根据之前的 RAG 项目结构化文件解析方案比较 调研,Dify 的文件解析能力偏弱,结构化文件解析时也没有保留好结构信息,从而导致文件的分片效果不佳,最终导致 RAG 的检索效果不理想。
因此从解析模块开始,先对结构化文件的解析方案进行了改造。所有的改造遵循 Dify 现有的框架进行设计,首先支持了 html, markdown, pdf 文件的解析优化,可以将增强的解析模块插入 Dify 框架中,改造后的结构如下所示:
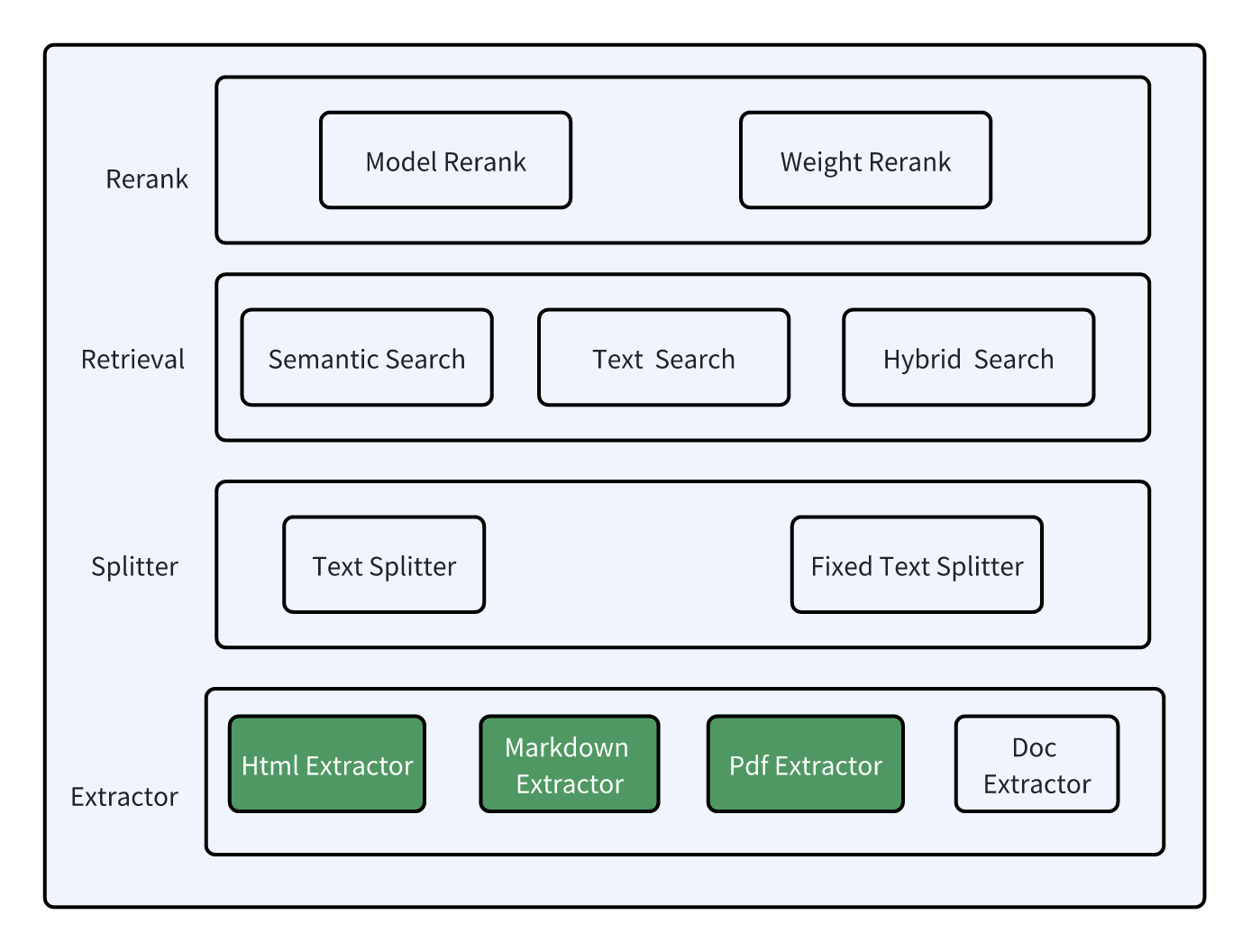
目前所有的代码目前已经开源在 Github 上,欢迎大家关注。
方案实现
模块化增强
方案实施是按照模块进行逐步升级替换的,下面以 html 解析模块为例进行介绍增强方案:
在之前的 RAG 项目结构化文件解析方案比较 中已经大致介绍了不同的开源项目的 html 解析方案,目前 Dify 的解析是基于 BeautifulSoup 实现,解析后的文档没有保留任何的结构信息,最终分片效果必然不佳。
根据实际测试情况来看,基于 html_text + readability 的解析方案更好,可以将与可视化效果更接近的内容分配在同一行中,从而尽可能避免文件内容被切断的问题。基于 html_text 实现的一个 html 解析方案简化后如下所示:
import html_text
import readability
html_doc = readability.Document(text)
# 使用 html_text 解析出文本内容,以 `\n` 分隔,单个段落中的内容会保留在同一行中
content = html_text.extract_text(html_doc.summary(html_partial=True))
title = html_doc.title()
if title != NO_TITLE:
txt = f"{title}\n{content}"
else:
txt = content
# 将原有的内容进行分拆,方便以特殊标识符进行组合
sections = txt.split("\n")
clean_sections = []
for sec in sections:
sec = sec.strip()
if sec:
clean_sections.append(sec)
# 使用 `\n\n` 进行连接,作为标识符提供给 Dify 的 Splitter 环节作为参考
docs = [Document(page_content="\n\n".join(clean_sections))]
上面的内容中需要特别注意的是,最终的内容是按照 \n\n 进行连接,原因从 洞察 Dify RAG 切片机制实现细节 中可以找到答案,Dify 会优先按照 \n\n 进行切片,因此通过同样的标记可以给 Dify 切分环节提供指导,从而尽可能按照合适的位置进行切分。
实际测试时发现,html 解析后的表格容易被切断,从而导致表格信息检索存在问题。因此选择额外处理表格,将提取的表格转换为 markdown 格式,独立进行向量化,尽可能避免表格信息无法检索的问题,实现如下所示:
# 将 html 中的表格转换为 markdown 格式
def convert_table_to_markdown(table) -> str:
md = []
rows = table.find_all("tr")
for row in rows:
cells = row.find_all(["th", "td"])
row_text = (
"| " + " | ".join(cell.get_text(strip=True) for cell in cells) + " |"
)
md.append(row_text)
if row.find("th"):
header_sep = "| " + " | ".join("---" for _ in cells) + " |"
md.append(header_sep)
return "\n".join(md)
soup = BeautifulSoup(content, "html.parser")
tables_md = []
tables = soup.find_all("table")
# 获取所有表格,转换为 markdown 格式,并从原始的 html 中移除
for table in tables:
table_md = convert_table_to_markdown(table)
tables_md.append(table_md)
table.decompose()
另外额外做了一些必要的内容提取优化,比如常规的 checkbox,radio 转换后的文本会保留所有选项的内容,这样最终大模型无法获得任何有价值的信息,因此需要根据实际选择的选项进行信息提取。
整体的实现可以在 html_extractor 中查看。
pip 依赖包封装
如果将现有的增强直接引入 Dify 项目中,那么拉取 Dify 后续的更新很容易出现代码冲突,导致长期维护困难。
因此实际将 Dify 增强能力封装为 pip 依赖包,这样只需要在 Dify 项目引入相关依赖,并根据需要选择合适的增强模块替换原有模块即可,后续的升级和迭代都比较方便。
目前对应的依赖包发布至 Pypi 上了,感兴趣可以安装体验。
Dify 应用
为了在 Dify 中使用现有的增强服务 Dify-RAG,实际是相当简单的。
由于所有的改造都是基于 Dify 官方的代码,因此需要先拉取 Dify 的代码,之后的需要两步即可:
- 将 Dify-RAG 依赖包安装至 Dify 项目中,由于 Dify 官方是基于 poetry 管理项目的,因此需要进入
api/目录下,通过poetry add dify-rag将依赖包安装至 Dify 项目中。 - 将 Dify 中表现不佳的基础模块替换为 Dify-RAG 提供的增强模块,目前支持的主要是 html, markdown, pdf 的解析,可以在
api/core/rag/extractor/extract_processor.py中直接替换,相应的修改可以参考 Github Code
替换之后重启服务,你就会发现,Dify 对特定格式的文件解析已经变强了。
为了生产环境使用更加便利,可以考虑重新打包自定义镜像,并对应修改 docker-compose 中指向的镜像,即可在生产环境中无缝使用了。
总结
本文介绍了 Dify-RAG 增强方案,通过提供 Dify 的 RAG 增强模块,通过简单的替换就可以大幅增强 Dify 现有的 RAG 能力,从而提升 RAG 检索效果。
当然 Dify-RAG 目前还处于早期阶段,主要提供了部分格式的文件解析增强,后续会逐步迭代,补充更多的 RAG 所需的能力,从而让 Dify 的 RAG 能力得到显著的增强。