背景介绍
最近测试时发现 Dify 的 RAG 分片效果一般,不管是使用之前 深入 Dify 源码,洞察 Dify RAG 核心机制 中有调研过的默认解析还是 Unstructured 解析。因此调研比较了 大量的开源框架 实现了特定格式的结构化解析方案,并与 Dify 现有解析流程进行了适配。
为了保证文件的解析能真正发挥出效果,需要保证预处理中其他环节也遵循前面的结构化方案进行处理,其中重要的一块就是文本的分片机制。深入了解 Dify 的实现细节后整理相关内容在这边,方便对 Dify RAG 实现机制感兴趣的同学。
Dify 切片简介
在前面的 深入 Dify 源码,洞察 Dify RAG 核心机制 已经大致了解到,Dify 的切片主要涉及的页面如下所示:
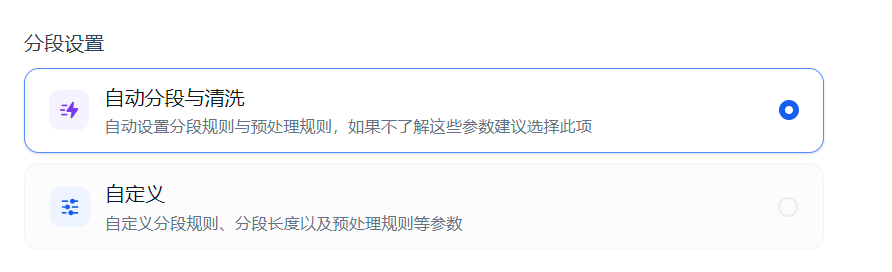
自动分段与清洗对应的就是 EnhanceRecursiveCharacterTextSplitter, 自定义对应的就是 FixedRecursiveCharacterTextSplitter,其实这两者实现机制的机制基本相同,主要差异是自定义机制将切片默认的参数提供给用户自由选择,并提供了一个额外的分段标识符。
Dify 切片机制
自动分段与清洗
Dify 的切片方案基本上是参考 langchain 实现,就是按照指定标识符列表进行递归切分,默认的切分的字符列表为 ["\n\n", "。", ". ", " ", ""],切分过程举例如下所示:
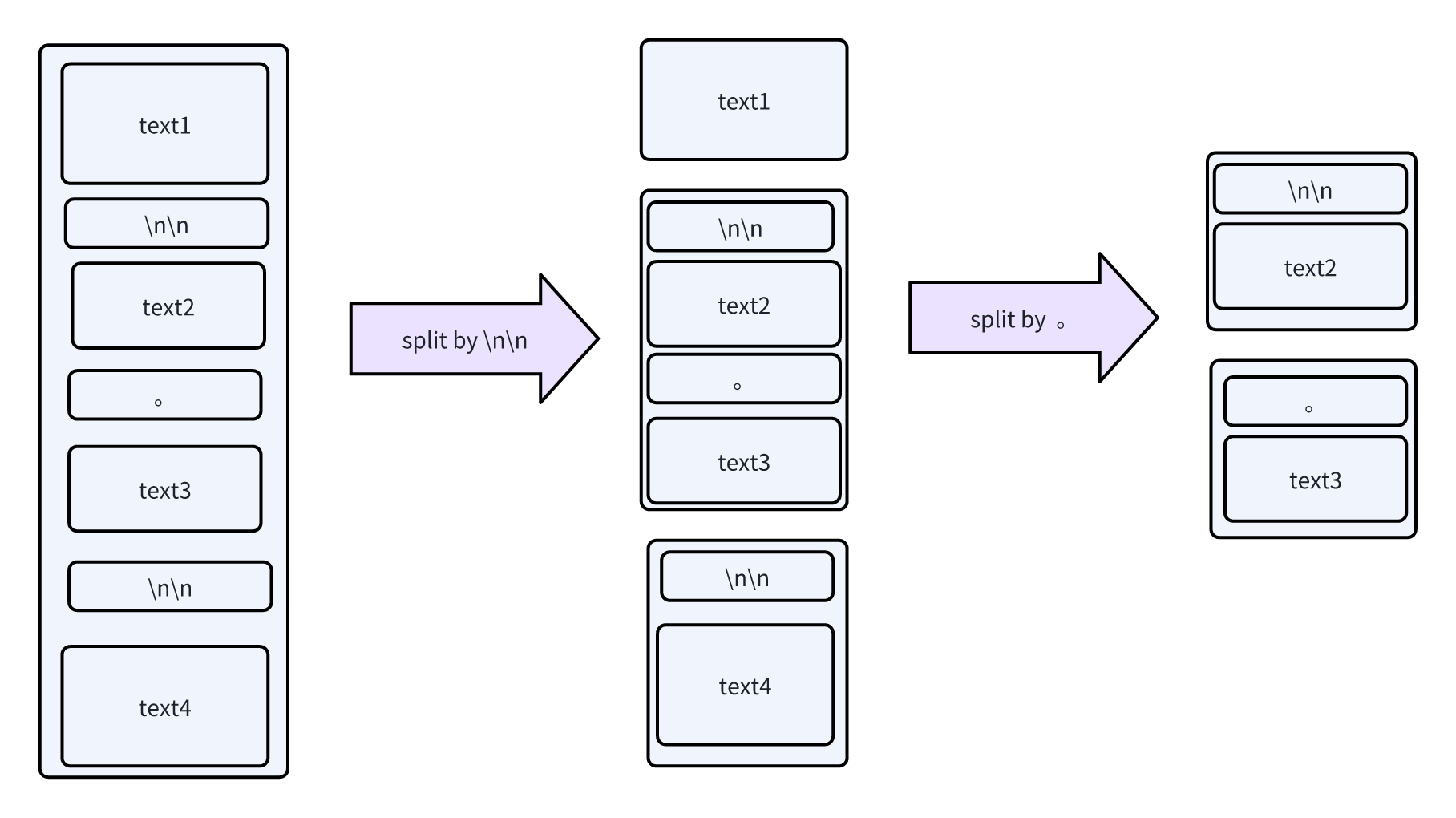
- 第一步按照第一个标识符
\n\n进行切分; - 如果切分后分片的大小依旧超过指定的分片阈值,此时按照下一个标识符
。进行切分; - 长度依旧超过阈值,接下来按照下一个字符
.切分,递归处理直到切分到的分片长度不超过阈值;
对应的代码在 api/core/rag/splitter/text_splitter.py 中:
def _split_text(self, text: str, separators: list[str]) -> list[str]:
final_chunks = []
separator = separators[-1]
new_separators = []
# 依次从指定的标识符列表中寻找合适的标识符
for i, _s in enumerate(separators):
if _s == "":
separator = _s
break
if re.search(_s, text):
separator = _s
new_separators = separators[i + 1:]
break
# 按照标识符进行切分
splits = _split_text_with_regex(text, separator, self._keep_separator)
_good_splits = []
_separator = "" if self._keep_separator else separator
for s in splits:
# 长度没有超过阈值, 是一个较好的分割点
if self._length_function(s) < self._chunk_size:
_good_splits.append(s)
else:
if _good_splits:
merged_text = self._merge_splits(_good_splits, _separator)
final_chunks.extend(merged_text)
_good_splits = []
if not new_separators:
final_chunks.append(s)
else:
# 长度超过阈值,递归按照后续的标识符进行切分
other_info = self._split_text(s, new_separators)
final_chunks.extend(other_info)
# 合并文本,尽量保证文本长度接近阈值,避免过短的碎片文本
if _good_splits:
merged_text = self._merge_splits(_good_splits, _separator)
final_chunks.extend(merged_text)
return final_chunks
上面的实现也比较容易理解,就是从 separators 中依次选择标识符,递归执行切分,切分后的片段暂存在 _good_splits 中,为了避免切分后的文本长度过短,在加入最终的列表 final_chunks 之前会进行文本的合并。
文本的合并常规就是依次遍历切片产生的片段,依次合并并保留必要的重合区域,感兴趣可以查看 _merge_splits() 方法的实现。
自定义
自定义分片与自动分段类似,可以支持用户指定分片长度和重叠长度,这个与常规的自动分段基本类似,只是将默认参数提供给用户进行修改。除此之外可以支持用户指定分段标识符:
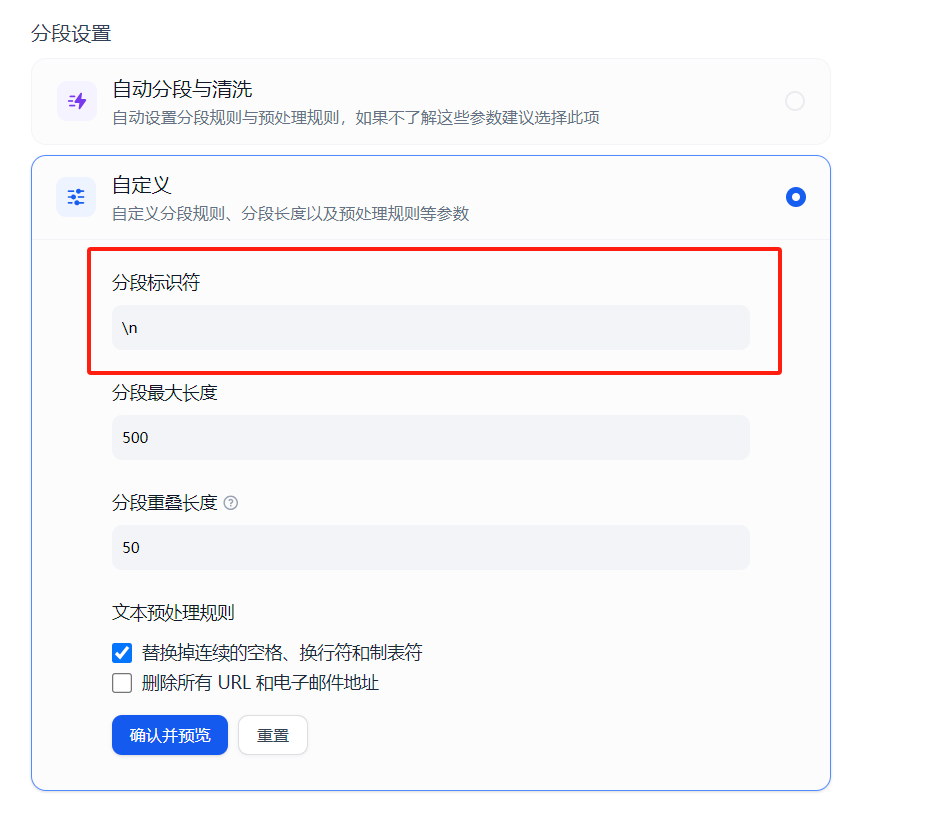
通过上面的自动分段可以看到文本切分是递归按照标识符列表进行切分的,那么这个自定义的分段标识符与默认的切分标识符列表是如何结合的呢?可以查看对应的实现:
def split_text(self, text: str) -> list[str]:
# 额外指定分段标识符的情况下,会按照用户指定的分隔标识符先切分
if self._fixed_separator:
chunks = text.split(self._fixed_separator)
else:
chunks = list(text)
final_chunks = []
for chunk in chunks:
# 按照用户执行的分段标识符切分后超过阈值,此时按照标识符列表依次递归切分
if self._length_function(chunk) > self._chunk_size:
final_chunks.extend(self.recursive_split_text(chunk))
else:
final_chunks.append(chunk)
return final_chunks
可以看到自定义切分的主要差异是会先按照用户指定的分段标识符进行额外切分,但是要特别注意这部分目前的实现比较粗糙:
- 按照用户指定的分段标识符进行切分时,分段重叠参数是不生效的,Dify 会直接按照指定的分段标识符切分;
- 按照用户指定的分段标识符切分时,不会执行分段的合并,可能会产生大量的长度较小的碎片文本;
- 用户指定的分段标识符为空的情况下,执行的
chunks = list(text)明显是有问题的,会按照单个字母切分字符串,最终完全不可用;
从目前来看,自定义的切片策略的实现坑有点多,需要慎用
总结
总结而言,Dify 的分片策略主要分为自动分段以及自定义策略,两者机制类似,依次按照字符列表进行递归的切片,但是自定义策略的实现目前坑有点多,建议谨慎选择。