背景介绍
之前深入源码对 Dify 的 完整流程 进行了解读,基本上梳理了 Dify 的实现流程与主要组件。
但是在实际部署之后,发现 Dify 现有的 RAG 检索效果没有那么理想。因此个人结合前端页面,配置信息与实现流程,深入查看了私有化部署的 Dify 的技术细节。
将核心内容整理在这边,方便大家根据实际的业务场景调整 Dify 知识库的配置,或者根据需要进行二次开发调优。
技术细节
本次重点介绍的是 Dify docker 私有化部署 默认情况的技术方案,个人本地部署使用的 Dify + Xinference,感兴趣可以查看 Dify 与 Xinference 最佳组合 GPU 环境部署全流程。
RAG 涉及的核心流程如下所示:
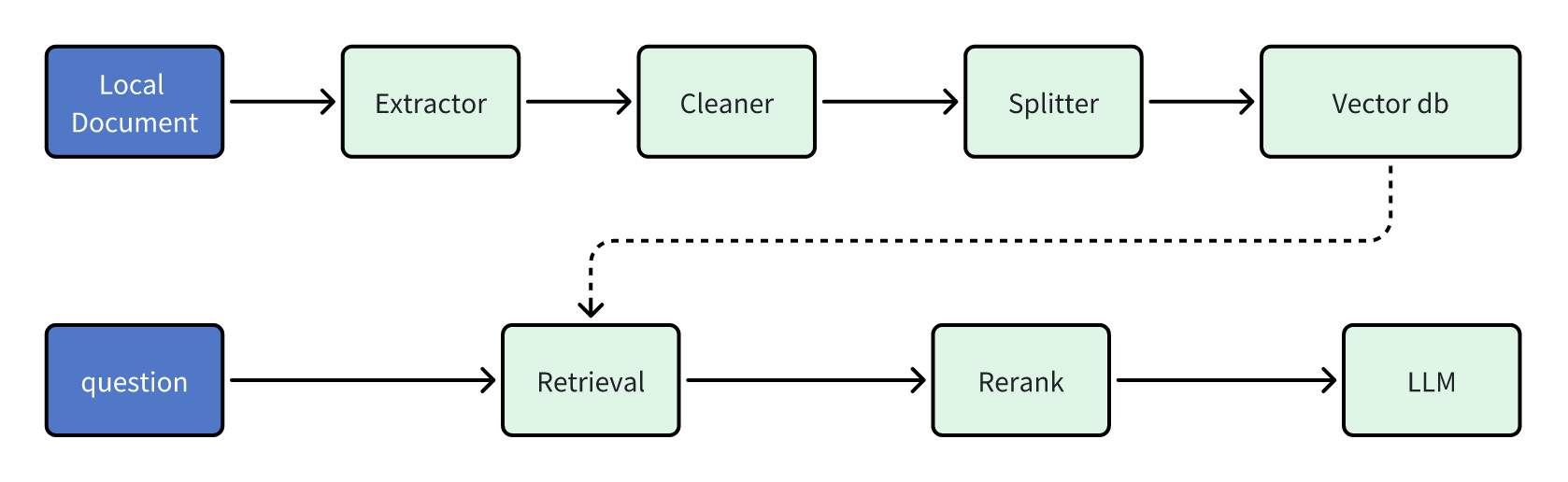
下面对各个模块的机制与优化方案进行深入介绍。
Extractor
Extractor 对应的 Dify 中的文件解析模块,用于从原始文件中提取文字内容。核心的文件解析流程在 api/core/rag/extractor/extract_processor.py 中实现。
从用户视角来看,目前存在两类解析方案:
- 基于 Unstructured 的文件解析方案,支持接入付费的 Unstructured 服务,部分的格式解析只有付费版本才支持,比如
.ppt; - 常规的 Dify 文件解析方案,基于开源库进行文件解析;
目前私有化部署时默认使用的是 Dify 文件解析方案,可以通过修改 .env 配置调整为 Unstructured 解析,但是使用 Unstructured 解析时需要配置对应的 Unstructured API 和 API Key,对应的配置如下所示:
// 文件解析类型,可以设置为 dify 或 Unstructured
ETL_TYPE=dify
UNSTRUCTURED_API_URL=
UNSTRUCTURED_API_KEY=
如果希望调整为 Unstructured 解析,可以修改 ETL_TYPE 字段。考虑到 Unstructured 解析可能需要付费,一般情况下可能直接使用 Dify 解析方案就好。可以看看默认 Dify 解析方案下的具体解析实现:
- pdf 目前的解析是基于 pypdfium2 直接提取内容;
- html 目前的解析是基于 BeautifulSoup 简单提取内容;
都属于极其常规的开源方案,如果希望具备更好的效果,可以考虑针对特定类型实现自定义的解析方案。
Cleaner
Cleaner 对应的解析内容的清洗模块,可以去除无关的字符,减少后续 token 的消耗。最核心的清洗流程在 api/core/rag/cleaner/clean_processor.py 中,目前主要是基于特定规则进行过滤:
def clean(cls, text: str, process_rule: dict) -> str:
# 默认清洗,必然会执行
text = re.sub(r'<\|', '<', text)
text = re.sub(r'\|>', '>', text)
text = re.sub(r'[\x00-\x08\x0B\x0C\x0E-\x1F\x7F\xEF\xBF\xBE]', '', text)
text = re.sub('\uFFFE', '', text)
rules = process_rule['rules'] if process_rule else None
# 基于预定义的规则选择是否执行
if 'pre_processing_rules' in rules:
pre_processing_rules = rules["pre_processing_rules"]
for pre_processing_rule in pre_processing_rules:
# 是否清理无关的空格和换行符
if pre_processing_rule["id"] == "remove_extra_spaces" and pre_processing_rule["enabled"] is True:
pattern = r'\n{3,}'
text = re.sub(pattern, '\n\n', text)
pattern = r'[\t\f\r\x20\u00a0\u1680\u180e\u2000-\u200a\u202f\u205f\u3000]{2,}'
text = re.sub(pattern, ' ', text)
# 是否清理 emails 和 urls
elif pre_processing_rule["id"] == "remove_urls_emails" and pre_processing_rule["enabled"] is True:
# 清理 email
pattern = r'([a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+)'
text = re.sub(pattern, '', text)
# 清理 URL
pattern = r'https?://[^\s]+'
text = re.sub(pattern, '', text)
return text
目前支持的内容清洗主要是清理空格换行符以及清理 Email 和 Url,默认情况下会清理空格换行符,但是不会开启清理 Email 和 Url。用户可以在前端页面进行调整:
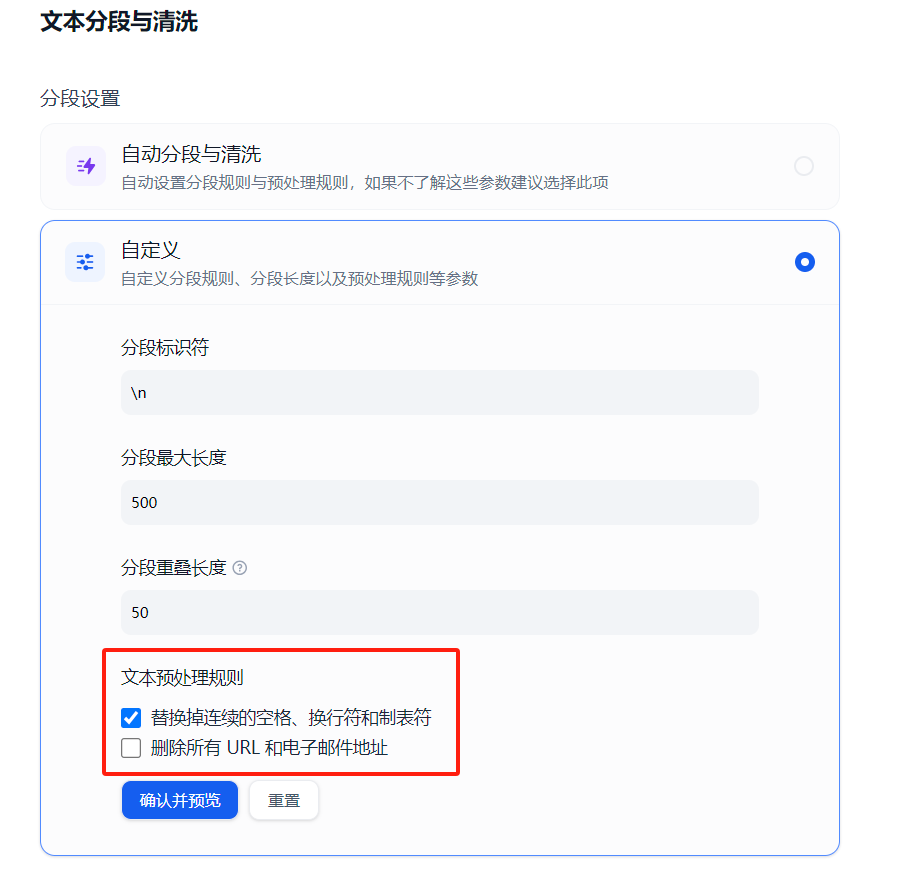
Splitter
Splitter 对应的是文件的分片机制,合适的分片可以避免文件块信息的不完整。目前 Dify 中实现的 Splitter 策略都在 api/core/rag/splitter 中。
实际 Dify 服务中主要使用下面两种策略分片:
EnhanceRecursiveCharacterTextSplitter, 递归查看字符来分割文本,支持基于特定的分隔符进行分割,类似 langchain 中的方案;FixedRecursiveCharacterTextSplitter, 同样是递归查看字符分割文本,但是可以支持用户指定分段标识符和分段最大长度等信息
两种分片机制其实差异不大,下面的这种灵活性更强一些。用户在前端分段设置中的两种分段选择对应的就是上面的不同机制:
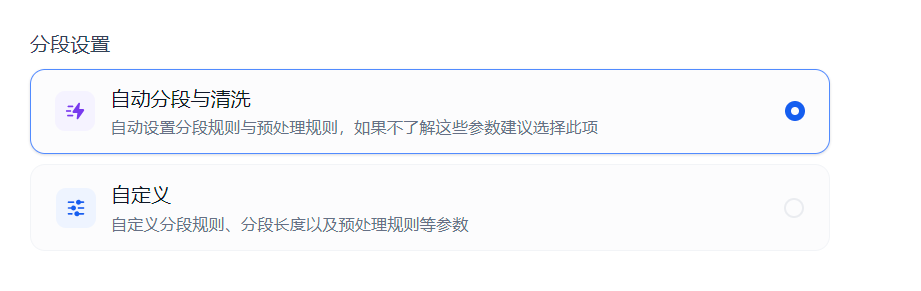
自动分段与清洗对应的就是 EnhanceRecursiveCharacterTextSplitter, 自定义对应的就是 FixedRecursiveCharacterTextSplitter。
Retrieval
在前面的 定位 Dify 知识库检索的调用异常 文章中介绍过,目前 Dify 支持四种模式:
- 关键词检索
- 向量检索
- 全文检索
- 混合检索
其中关键词检索对应的就是知识库检索页面的经济模式:

关键词检索是从原始文字中提取的关键词进行匹配,因此不需要需要模型进行处理,效率更高,但是一般情况下效果会更差,因为只能严格按照关键词进行匹配。
而其他三种检索方式对应的是页面中的高质量模式,用户可以在页面中选择一种:
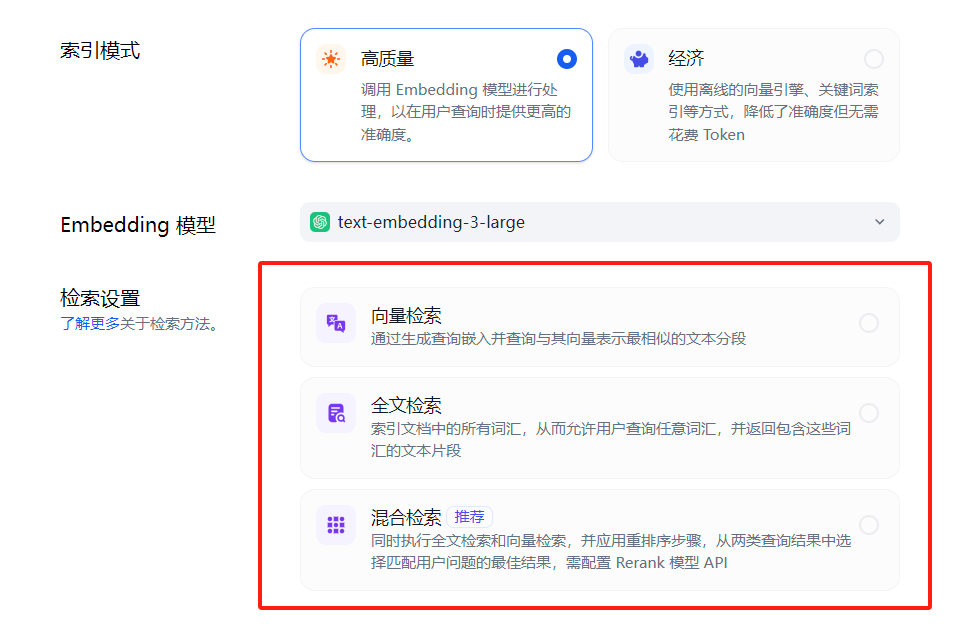
这三种检索使用的都是向量数据库自身提供的能力,这种模式下分块的文本都是直接存入向量数据库。部分向量库不支持全文检索,这种情况下调用全文检索会直接返回空列表。
Dify 目前默认使用的向量数据库为 weaviate, 如果需要可以修改 .env 配置:
# 可选 `weaviate`, `qdrant`, `milvus`, `myscale`, `relyt`, `pgvector`, `chroma`, `opensearch`, `tidb_vector`, `oracle`, `tencent`
VECTOR_STORE=weaviate
目前默认的 weaviate 向量数据库同时支持向量检索和全文检索。如果希望调整为其他向量库,建议先确认下 Dify 中的实现是否支持了全文检索,不支持的情况下可能会导致检索效果很差。
截止 2024-7-17,Dify 中现有向量库支持全文检索的情况统计如下:
| 向量库 | 是否支持全文检索 |
|---|---|
| weaviate | √ |
| qdrant | √ |
| milvus | × |
| myscale | √ |
| relyt | × |
| pgvector | × |
| chroma | × |
| opensearch | √ |
| tidb_vector | × |
| oracle | × |
| tencent | × |
Rerank
Rerank 就是对检索的结果进行重新排序,重排序的效果与 Rerank 模型和对应的配置有关,用户可以在检索设置页进行设置:
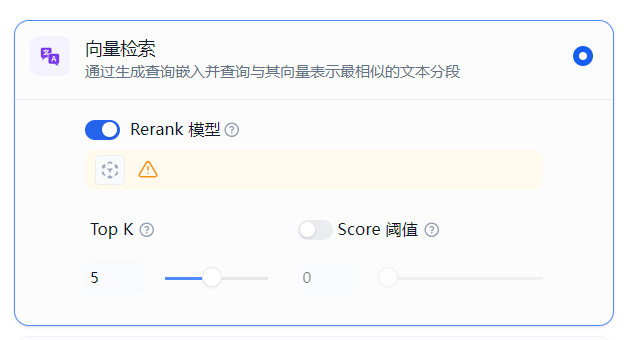
可以看到除了模型设置之外,目前需要配置 Top K 和 score 阈值两个参数。
页面上的这两个参数事实上存在一些歧义,可以是检索阶段获取 Top K 和 score 过滤,也可能是 Rerank 后选择 Top K 和 score 过滤。从源码来看是哪种情况:
def embedding_search(cls, flask_app: Flask, dataset_id: str, query: str,
top_k: int, score_threshold: Optional[float], reranking_model: Optional[dict],
all_documents: list, retrival_method: str, exceptions: list):
with flask_app.app_context():
try:
dataset = db.session.query(Dataset).filter(
Dataset.id == dataset_id
).first()
vector = Vector(
dataset=dataset
)
# 检索阶段基于 top_k 和 score_threshold 进行过滤
documents = vector.search_by_vector(
query,
search_type='similarity_score_threshold',
top_k=top_k,
score_threshold=score_threshold,
filter={
'group_id': [dataset.id]
}
)
if documents:
if reranking_model and retrival_method == RetrievalMethod.SEMANTIC_SEARCH.value:
data_post_processor = DataPostProcessor(str(dataset.tenant_id), reranking_model, False)
# 重排序阶段基于 score_threshold 进行过滤,top_n 与文档数量相等,不会用于过滤
all_documents.extend(data_post_processor.invoke(
query=query,
documents=documents,
score_threshold=score_threshold,
top_n=len(documents)
))
else:
all_documents.extend(documents)
except Exception as e:
exceptions.append(str(e))
根据上面的代码,可以确认用户设置的 top_k 是在检索阶段进行过滤,score 阈值会在检索和重排序阶段同时用于过滤。
从目前来看,我觉得这个设计是有明显问题的:
- 检索模型和重排序模型可能是不同厂商的模型,模型的分值分布差异可能会特别大,使用同样阈值过滤是不合适的。在 从《红楼梦》的视角看大模型知识库 RAG 服务的 Rerank 调优 文章中测试过,bge-reranker-large 和 bce-reranker-base_v1 模型的分值分布就差异很大,需要适配不同的阈值,强制检索和重排序使用同样阈值很有可能会导致效果不佳;
- 重排序阶段不过滤 top K,只在检索阶段过滤同样是有问题的。因为检索阶段的排序是不准确,仅基于检索阶段过滤 top K 可能也是不准确的。事实上,如果 top K 设置较小,可能会导致选择错误的文档;如果设置较大的 top K,因为重排序后不过滤,很有可能上下文中文档过多导致效果不佳。Rerank 做得比较深入的有道 建议,检索阶段获取 top 50~100, 重排序获取 top5~10,也说明需要支持独立配置。
这一块可能需要 Dify 进行有针对性的改进。
总结
文章对 Dify 中使用 RAG 的技术细节进行梳理,整体而言,Dify 提供了一个基础版本的 RAG 服务,整体的设计和实现都比较清晰,但是效果上没有做过多的优化。
如果希望能获得更好的效果,可以通过部分配置进行调整。如果对 RAG 的效果要求较高,预期可能会需要进行有针对性的二次开发优化。