背景介绍
之前在 GPU 服务器上部署了 Dify 服务 ,使用的是 Dify 与 Xinference 组合,Xinference 部署的大模型是 THUDM/glm-4-9b-chat。
基于本地部署的服务构建了知识库,并利用首页提供的任务流模板创建了一个 RAG 工作流
实际运行此应用聊天时发现,知识库检索节点执行时会报错 GPT3.5 模型不存在,除了错误信息以外没有其他额外信息可供进一步定位问题,这个情况存在两个诡异之处:
- 知识库检索环节预期不需要调用大模型,实际却调用了大模型;
- 本地没有配置 GPT3.5, 为什么会选择 GPT3.5 模型;
这篇文章就从问题出发,借助源码与对应的服务 API 请求信息,定位问题的根本原因。
问题定位
为了定位这个问题,结合之前梳理的 Dify 源码解析 中的调用链路,我们可以快速找到相关实现。
知识库检索
单个知识库检索的实现在 api/core/rag/datasource/retrieval_service.py 中,知识库检索目前支持四种检索模式,其中混合检索就是向量检索 + 全文检索结果的结合,因此主要关注三种基础检索方式:
- 关键词检索
- 向量检索
- 全文检索
看看是否有任何特殊设计,从而导致需要调用大模型进行处理。
关键词检索
关键词检索目前只支持了 Jieba 的关键词检索,核心的实现是在 api/core/rag/datasource/keyword/jieba/jieba.py 中,具体如下所示:
def search(
self, query: str,
**kwargs: Any
) -> list[Document]:
# 获取关键词表
keyword_table = self._get_dataset_keyword_table()
k = kwargs.get('top_k', 4)
# 利用 query 生成的关键词匹配关键词表中数据块并进行排序
sorted_chunk_indices = self._retrieve_ids_by_query(keyword_table, query, k)
# 根据检索到的数据块查询数据库获取信息构造 Document 列表
documents = []
for chunk_index in sorted_chunk_indices:
segment = db.session.query(DocumentSegment).filter(
DocumentSegment.dataset_id == self.dataset.id,
DocumentSegment.index_node_id == chunk_index
).first()
if segment:
documents.append(Document(
page_content=segment.content,
metadata={
"doc_id": chunk_index,
"doc_hash": segment.index_node_hash,
"document_id": segment.document_id,
"dataset_id": segment.dataset_id,
}
))
return documents
看到关键词检索就是从分块后的文本中提取关键词,构造关键词表。之后从查询语句中提取关键词,与关键词表进行匹配,从而确定匹配的数据块。
向量检索
向量检索目前的实现也比较容易理解,在 api/core/rag/datasource/vdb 下实现了不同的向量库,在实际执行向量检索时,就是调用对应向量库的 search_by_vector() 方法,以 Milvus 为例,对应的实现如下所示:
def search_by_vector(self, query_vector: list[float], **kwargs: Any) -> list[Document]:
# 调用 Milvus 客户端的 search 方法进行检索
results = self._client.search(collection_name=self._collection_name,
data=[query_vector],
limit=kwargs.get('top_k', 4),
output_fields=[Field.CONTENT_KEY.value, Field.METADATA_KEY.value],
)
# 构造结果为 Document 列表
docs = []
for result in results[0]:
metadata = result['entity'].get(Field.METADATA_KEY.value)
metadata['score'] = result['distance']
score_threshold = kwargs.get('score_threshold') if kwargs.get('score_threshold') else 0.0
if result['distance'] > score_threshold:
doc = Document(page_content=result['entity'].get(Field.CONTENT_KEY.value),
metadata=metadata)
docs.append(doc)
return docs
可以看到就一个客户端的检索调用,看起来没有任何使用任何大模型。
全文检索
Dify 定义的全文检索事实上实现的就是 BM25 检索,主要利用向量库现有的能力实现,目前大部分向量库都不支持全文检索,这种情况下会直接返回空列表。
我们选择一个支持全文检索的向量库 qdrant 为例查看对应的实现,全文检索调用的方法为 search_by_full_text, qdrant 对应的实现如下所示:
def search_by_full_text(self, query: str, **kwargs: Any) -> list[Document]:
"""Return docs most similar by bm25.
Returns:
List of documents most similar to the query text and distance for each.
"""
from qdrant_client.http import models
scroll_filter = models.Filter(
must=[
models.FieldCondition(
key="group_id",
match=models.MatchValue(value=self._group_id),
),
models.FieldCondition(
key="page_content",
match=models.MatchText(text=query),
)
]
)
# 调用 qdrant 客户端执行 BM25 检索
response = self._client.scroll(
collection_name=self._collection_name,
scroll_filter=scroll_filter,
limit=kwargs.get('top_k', 2),
with_payload=True,
with_vectors=True
)
results = response[0]
documents = []
for result in results:
if result:
documents.append(self._document_from_scored_point(
result, Field.CONTENT_KEY.value, Field.METADATA_KEY.value
))
return documents
可以看到全文检索也只是客户端的简单封装,没有大模型的调用。
多知识库召回
从上面可以看到,单知识库的检索不涉及大模型调用,那么只能继续跟踪调用链路反向追踪。实际发现知识库检索节点的调用在 api/core/workflow/nodes/knowledge_retrieval/knowledge_retrieval_node.py 中,在调用单个知识库检索前,会包含一个多知识库库召回判断,其中涉及两种召回模式:
N 选 1 召回:先根据用户输入的意图选择合适的知识库,然后从知识库检索所需的文档,适用于知识库彼此隔离,不需要互相联合查询的场景;多路召回:此时会同时从多个知识库检索,然后进行重新排序,适用于知识库需要联合查询的场景。
此时就发现了问题,N 选 1 召回 模式是根据知识库的描述构造 prompt,然后调用大模型判断选择合适的知识库,猜测问题可能就出现在这个环节了。实际去查看网页端,发现默认使用的确实是这个模式:
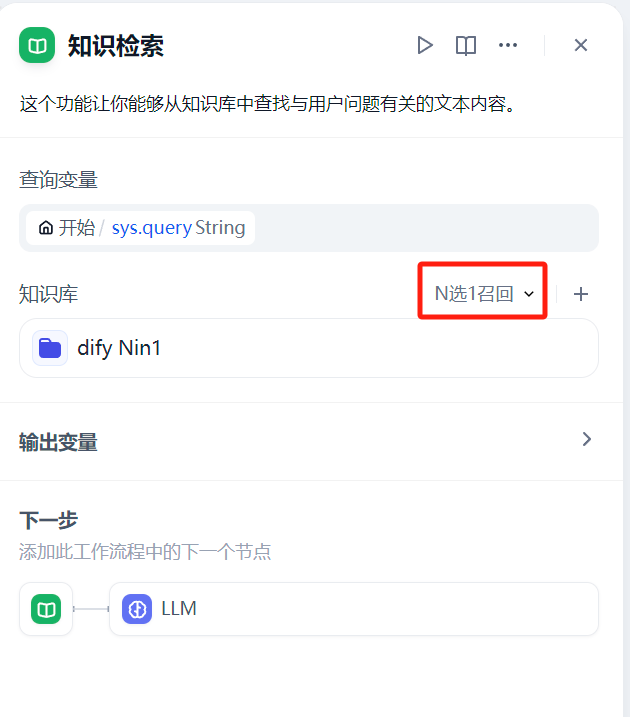
看起来问题就出现在这个环节了,接下来就需要了解为什么本地会使用一个不存在的 GPT3.5 大模型。
深入查看 N 选 1 召回 调用的大模型的初始化环节,可以看到对应的实现在 api/core/workflow/nodes/knowledge_retrieval/knowledge_retrieval_node.py 中:
def _fetch_model_config(self, node_data: KnowledgeRetrievalNodeData):
# 从 config 中获取模型名和对应的提供商
model_name = node_data.single_retrieval_config.model.name
provider_name = node_data.single_retrieval_config.model.provider
# 构造大模型对象,后续可以直接调用
model_manager = ModelManager()
model_instance = model_manager.get_model_instance(
tenant_id=self.tenant_id,
model_type=ModelType.LLM,
provider=provider_name,
model=model_name
)
可以看到使用的大模型是基于知识库检索节点的配置 config 初始化的。通过前端 HTTP 返回值看节点对应的配置,可以看到 config 中确实设置的是 GPT 3.5:
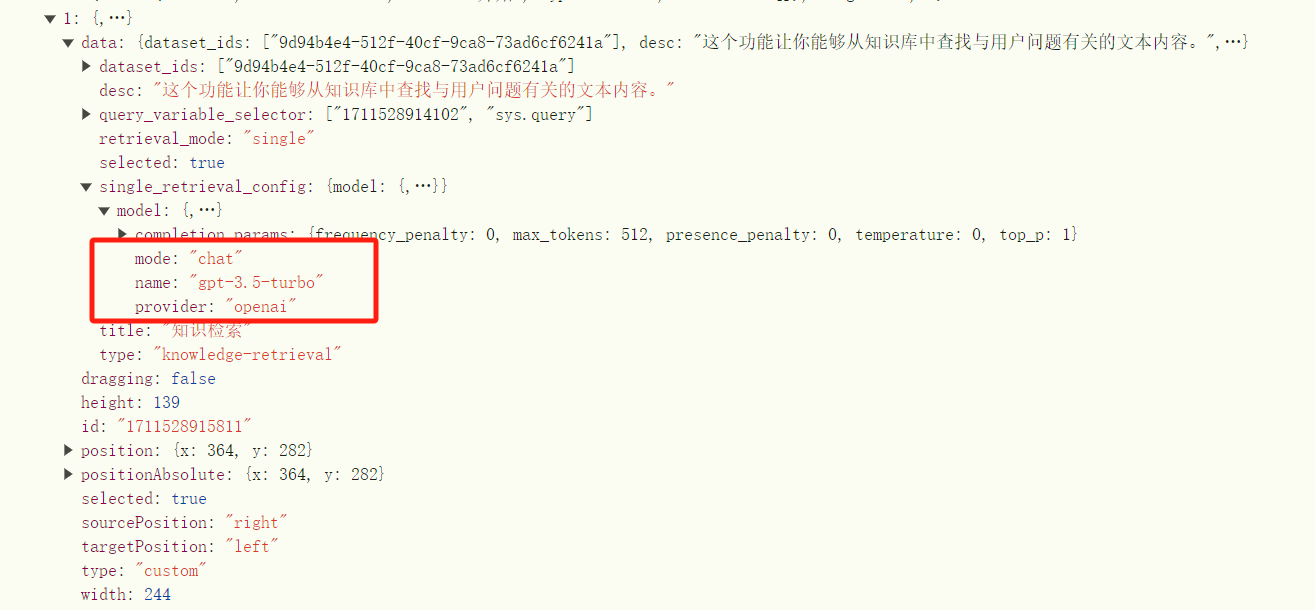
那么看起来问题就出现在初始化配置了,难道知识库检索节点总是默认 GPT3.5,而不是默认选择可用的模型?
知识库检索配置
接下来尝试手工创建一个知识库检索节点,在手工创建了知识库检索节点后,查看对应的 config,发现使用的模型确实是正确的 glm-4-9b-chat。
查看前端创建节点时发现会调用 /api/workspaces/current/default-model 接口获取默认模型,对应的返回值也是正确的 glm-4-9b-chat,看起来构建节点的默认选择模型机制是没有问题的。
那么为什么最初初始化时会生成一个错误的 GPT3.5 模型呢?只能猜测是默认模板的知识库选择了 GPT3.5 模型,那么这个 N 选 1 召回 的模型是如何设置的呢?尝试点击了 N选1召回 按钮,就看到了如下所示的页面:
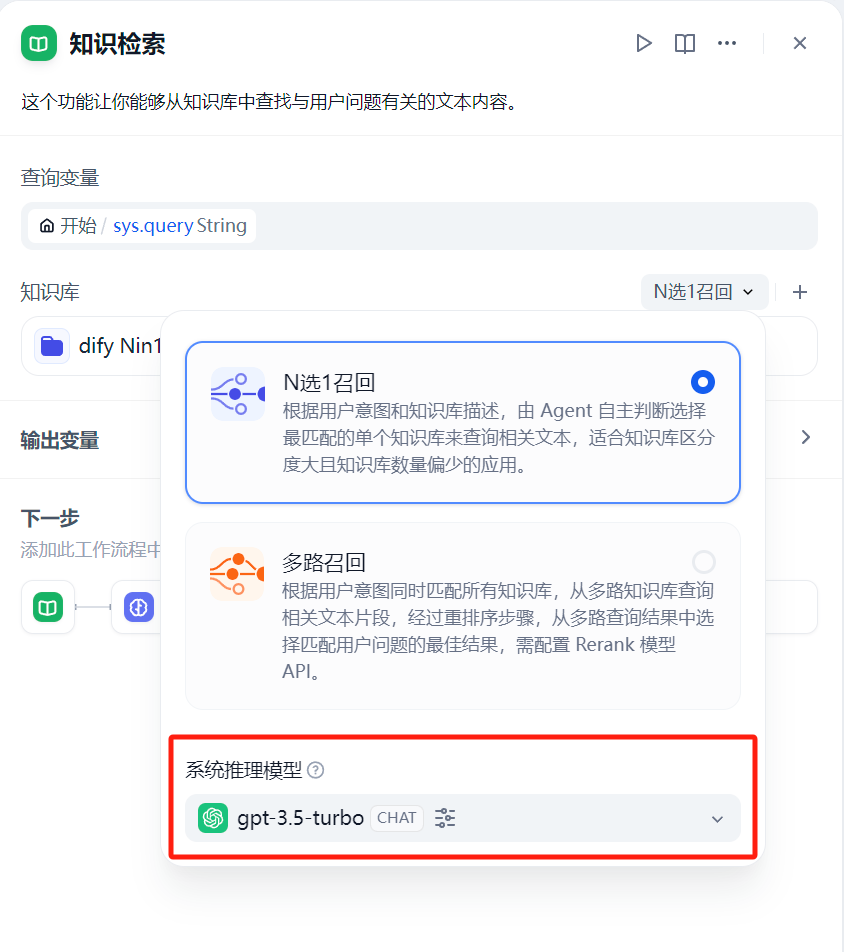
可以看到其中的系统推理模型选择的是 GPT3.5,这个页面可以修改对应的大模型,至此所有的问题都一清二楚了。
总结
从本轮的追踪来看,知识库检索选择 N选1召回 模式下,会需要额外配置一个用于选择知识库的大模型,在模板中这个模型目前默认配置的时 GPT3.5。在本地部署时,如果没有配置 GPT3.5,那么此时会在知识库检索时报错 GPT3.5 模型不存在的异常。
定位到问题后并不难解决,修改默认模型即可。但是对 Dify 的新手而言就比较头疼,默认的模板使用默认配置的情况下本地部署就会出现一个如此诡异的异常,排查还是比较麻烦的。建议官方模板的知识库检索的默认模式改为 多路召回,这样在本地部署时就不会给不熟悉 Dify 的人如此大的困扰。