背景介绍
在前一篇文章 RAG 项目对比 之后,确定 Dify 目前最合适的 RAG 框架。本次就尝试在本地 GPU 设备上部署 Dify 服务。
Dify 是将模型的加载独立出去的,因此需要选择合适的模型加载框架。调研一番之后选择了 Xinference,理由如下:
- 支持多种类型的模型,包括 LLM,Embedding, Rerank, Audio 等多种业务场景的模型需求,一个框架全搞定;
- 方便的模型管理能力,提供可视化页面快速部署模型
- 支持直接从 ModelScope 下载模型,避免 huggingface 被墙的问题;
本文是 Dify 与 Xinference 最佳组合的 GPU 设备部署流程。为了充分利用 nvidia GPU 的能力,需要先安装显卡驱动,CUDA 和 CuDNN,这部分网上的教程比较多了,大家可以自行搜索参考安装,安装时需要注意版本需要与自己的 GPU 显卡版本匹配。
Dify 部署
参考 Dify 官方文档 进行安装。
首先需要下载 Dify 对应的代码:
git clone https://github.com/langgenius/dify.git
之后创建环境变量文件 .env, 根据需要进行修改,之后就可以基于 docker compose 启动:
cd dify/docker
cp .env.example .env
docker compose up -d
默认访问 http://
docker 镜像问题
实际执行镜像拉取时发现,Docker hub 因为监管的原因已经无法访问了。为了解决这个问题,目前相对可行的方案:
- 利用一些目前可用的镜像服务,当前(2024-7-11)可用的是 public-image-mirror,通过修改本地的镜像下载地址进行加速;
- 利用 Github Action 将镜像拉取至个人阿里云的的私有镜像仓库,可以参考 教程;
实际为了简单直接采用方案 1,在本地文件 /etc/docker/daemon.json 中添加:
{
"registry-mirrors": [
"https://docker.m.daocloud.io"
]
}
如果上面的地址不可用,可以尝试另一个测试可用的地址:
{
"registry-mirrors": [
"https://docker.anyhub.us.kg"
]
}
修改之后执行下面命令重启 docker 服务:
sudo systemctl daemon-reload
sudo systemctl restart docker
接下来就可以正常拉取镜像了。
Xinference 部署
XInference 的部署也选择基于 docker 部署,可以参考 XInference 部署,实际使用的部署命令为:
docker run -e XINFERENCE_MODEL_SRC=modelscope -v <local model path>:/models -e XINFERENCE_HOME=/models -p 9998:9997 --gpus all registry.cn-hangzhou.aliyuncs.com/xprobe_xinference/xinference:latest xinference-local -H 0.0.0.0
各位使用时将上面命令行中的 <local model path> 替换为期望服务器上模型存储的路径即可
上面的命令利用 XINFERENCE_MODEL_SRC=modelscope 指定了模型最终是从 modelscope 下载的,这样国内下载模型镜像的速度比较快。
上面的命令会将 docker 中的 9997 端口映射至本地的 9998 端口,部署完成后访问 http://<server ip>:9998/ui 就可以看到 XInference 可视化页面,有需要可以调整服务器上实际占用的端口。
docker GPU 不可用
上面的命令实际执行时会报错 docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]]., docker 目前是不能直接使用 GPU 设备的。
此时需要参考 Nvidia 文档 安装 nvidia-container-toolkit
首先需要先补全 apt-get 下载源:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
接下来更新源,安装对应的包:
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
安装完成之后修改 docker 配置文件 /etc/docker/daemon.json :
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}
之后执行 sudo systemctl restart docker 重启 docker。
此时再执行上面的 docker run 命令去使用 GPU 设备就没问题了。
Dify 模型配置
上述服务配置好之后,就可以在 Xinference 下载所需的模型,XInference 启动后实际会占用服务器上的 9998。因此访问 http://<server ip>:9998/ui 就可以进入可视化页面下载所需的模型;
在 Xinference 上下载和运行所需的模型后可以返回 Dify 可视化页面,在 Dify 的设置页中配置对应的模型,对应的页面如下所示:
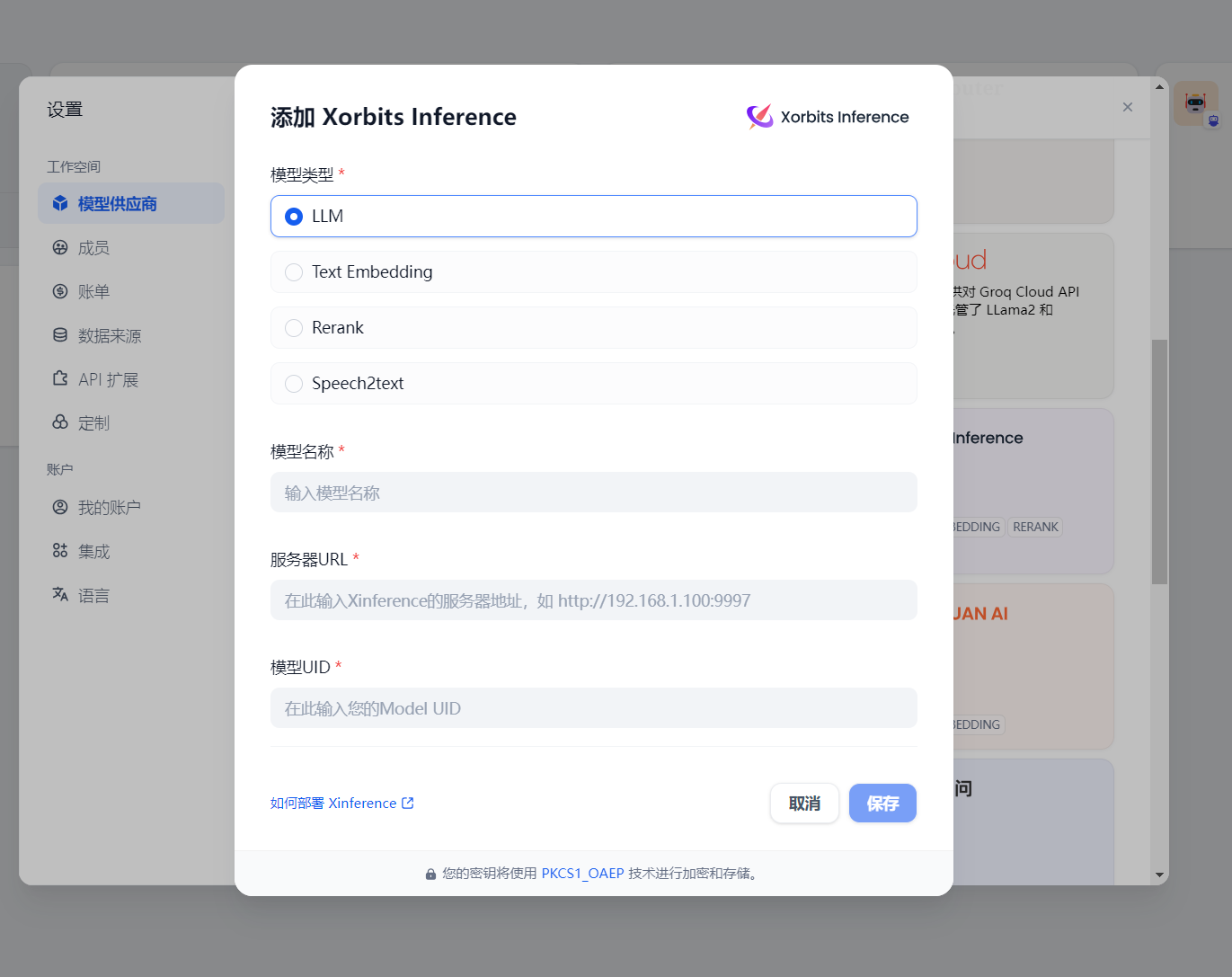
RAG 一般情况下需要配置上 LLM, Text Embedding 和 Rerank 模型。配置完成后就可以自由玩耍了。
总结
本文是实际部署 Dify + Xinference 组合的完整流程,实际上如果 docker 可用的话,整体的流程还是比较丝滑的。期望给后面折腾 Dify 部署的一些帮助,减少重复的踩坑。