背景介绍
在过去使用大模型的过程中,感受到大模型能力的持续提升。但是作为程序员,在基于不熟悉的框架开发新功能时,依旧需要持续查询官方文档。而大模型对特定框架的使用细节所知甚少,因此可能给出的回答不够准确。
比如之前在 快速搭建量化交易平台 时因为不熟悉相关框架就需要反复查看 Dash 和 backtrader 的官方文档寻找解决方案,这部分工作需要花费不少时间。
事实上单个项目的技术框架选型完成后就会稳定下来,因此是否可以直接基于框架的官方文档进行知识库问答。这样就可以避免重复的查询文档,节省时间。
这个问题初步评估应该是比较容易解决的,至少 RAG 看起来应该就是现成的解决方案。
本周周末,花费了 10 个番茄钟,快速搭建了一个官方文档查询的大模型应用,本篇文档记录下完整的实践过程,希望对大家有所帮助。
需求分析
简单梳理了一下需求,这个需求主要是利用采集的官方文档作为外部信息源,弥补大模型知识不足的问题。期望可以实现一个可视化的服务,接收到用户的查询时,结合官方文档给出更准确的答案。
简单分解下需求的实现流程:
- 实现文档爬取功能,基于提供的官方文档入口地址,爬取框架下所有官方技术文档;
- 支持根据官方文档搭建知识库;
- 接入大模型,执行完整的问答;
实践流程
因为期望能用最小的成本验证这个需求,所以期望尽可能基于现有的基础服务实现。
Dify 尝试
从之前调研的情况来看,Dify 应该是一个不错的选择,本身自带知识库构建的能力,也可以接入大量的外部拓展。
在 Dify 上构建知识库时发现,Dify 本身就提供了直接 Sync From Website 的能力,看起来真的可以一步到位的样子。
Dify 同步网站内容是基于 Firecrawl 实现的。但是实际测试 Dify 绑定 Firecrawl 会报错 500 异常:
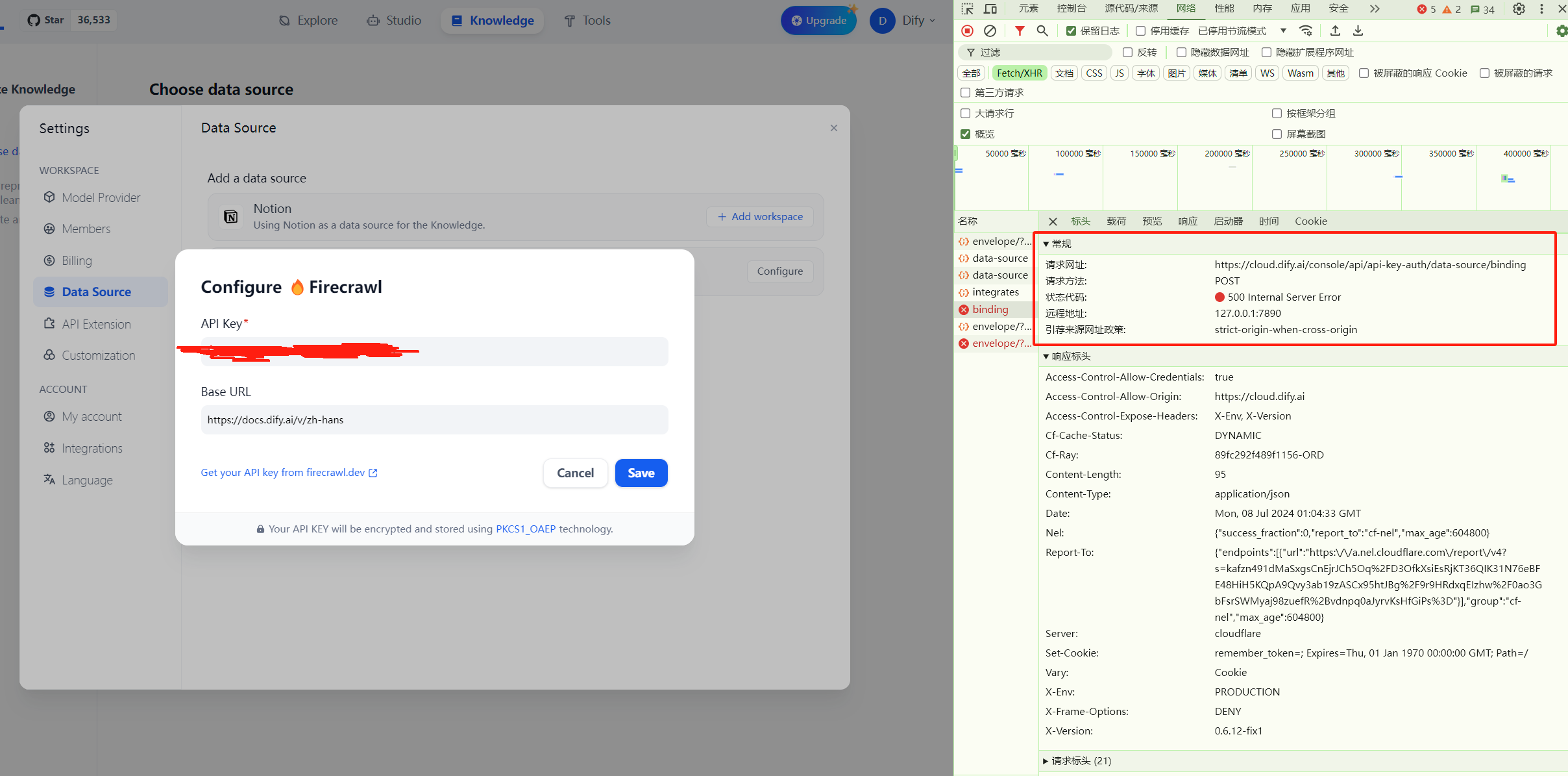
反复尝试都是够不成功,看起来 Dify 这部分功能应该还有问题。
Firecrawl 尝试
Dify 支持不了,看起来知识库构建需要自己动手。考虑先离线爬取,之后再上传至 Dify 构建知识库。
简单看了下 Firecrawl 的官方文档,实现了一个快速的版本:
from firecrawl import FirecrawlApp
# 需要注册网站获取 API_KEY
API_KEY = ""
app = FirecrawlApp(api_key=API_KEY)
# 爬取目标网站,目前爬取的就是 Dify 的官方文档
url = "https://docs.dify.ai/v/zh-hans"
crawl_result = app.crawl_url(
url,
)
# 获取爬取结果,选择 markdown 格式输出
for idx, result in enumerate(crawl_result):
print(f"Crawl {idx}st page")
page_data = result["markdown"]
# 将 page_data 保存到本地, 以 idx 为文件名
with open(f"data/page_{idx}.md", "w") as f:
f.write(page_data)
实际多次测试,获取结果总是超时,参考官方文档调整参数都无法得到结果,看起来直接调用 SDK 获取结果目前容易超时。
那爬取结果是否成功了呢?去 web 端查看,发现 web 端显示已爬取到内容了,可以直接下载:
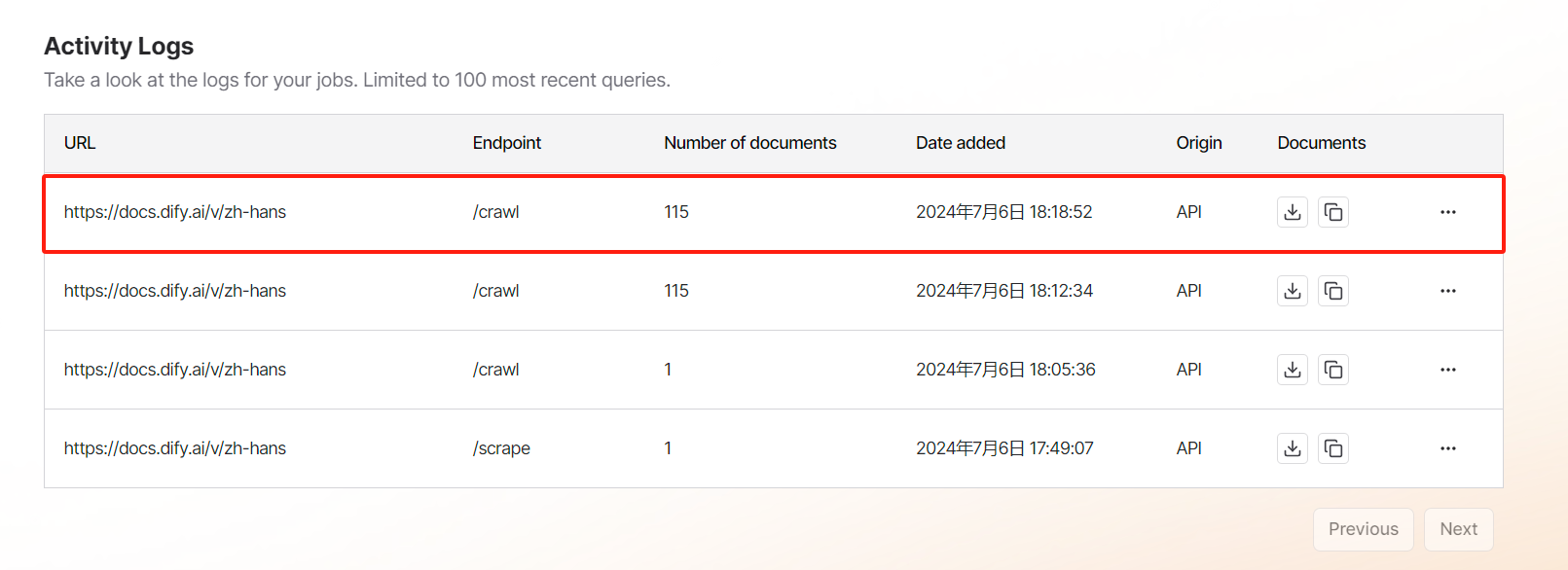
在目前情况下,只能先实现一个处理离线文件的脚本,实际下载的文件为 documets.json ,没有找到太多关于离线文件的结构的解释,只能一层一层解包,最终实现如下:
import json
# 读取离线 json 文件
def read_json_file(file_name: str):
with open(file_name, "r") as f:
json_data = json.load(f)
docs = json_data[0]["docs"]
return docs
# 清理 markdown 内容,去除重复的导航内容以及页脚内容
def clean_doc(doc: dict):
markdown_doc = doc["markdown"]
line_data = markdown_doc.split("\n")
flag = False
flag_text = "由 GitBook 提供支持"
end_flag_text = "上一页"
end_flag_text2 = "下一页"
clean_data = []
for line in line_data:
if line.find(flag_text) != -1:
flag = True
continue
if line.find(end_flag_text) != -1 or line.find(end_flag_text2) != -1:
break
if flag:
clean_data.append(line)
return "\n".join(clean_data)
docs = read_json_file("documents.json")
clean_contents = []
for idx, doc in enumerate(docs):
clean_content = clean_doc(doc)
clean_contents.append(clean_content)
with open(f"data/page_full.md", "w") as f:
f.write("\n\n\n".join(clean_contents))
解析原始文档内容,清洗掉每页重复的导航栏以及最终页脚的无关内容,得到的就是真正相关的技术文档内容。
为什么将所有内容都合并放入同一个文件,而不是拆分为 100+ 文件呢?原因是 Dify 免费版本单个知识库上传的文件数量不能超过 50 个,合并可以规避这个限制。
Dify 知识库测试
基于离线清洗好的文档,可以快速搭建一个 Dify 的官方文档的支持库,之后再搭建一个 RAG 的工作流如下所示:
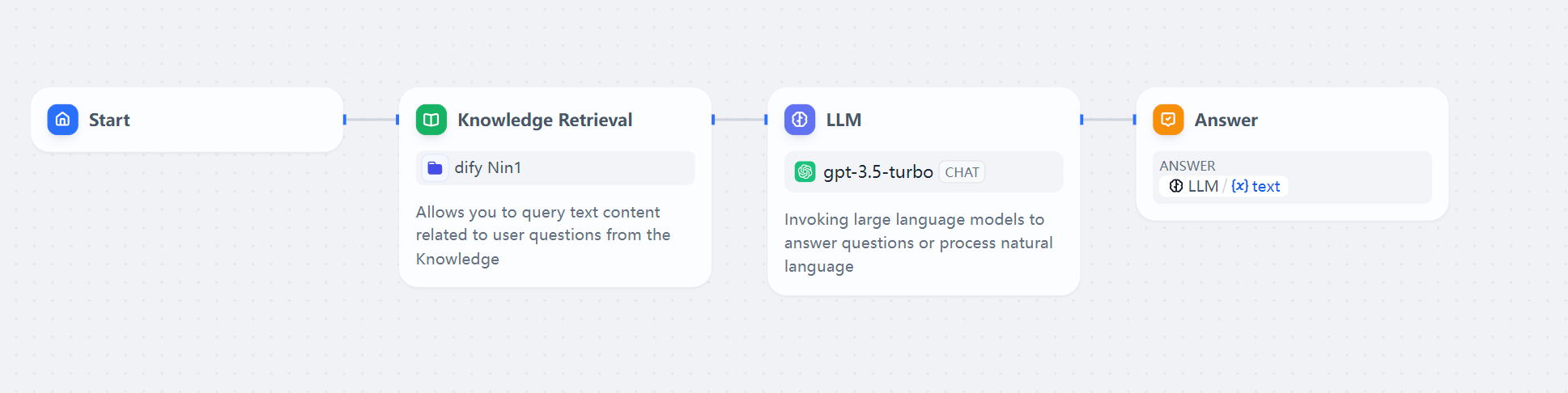
接下来就开开心心的部署应用测试了,实际发现效果如下所示:
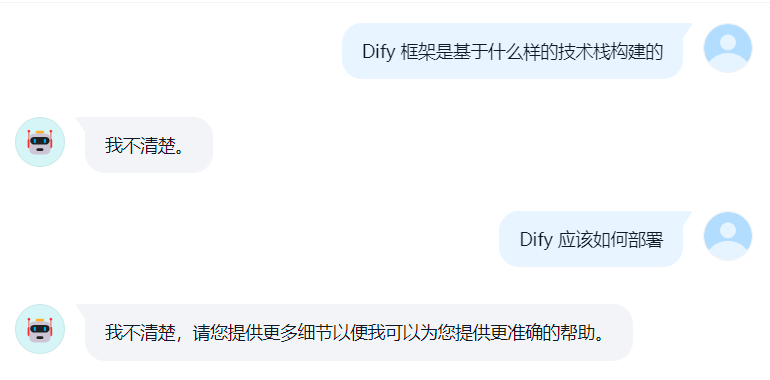
这不就尴尬了吗?
实际手工测试知识库的召回数据,看起来也不太行,看起来 Dify 的知识库召回效果很一般。当然也不排除是使用姿势的问题,这个还有待后续验证。
RAG 方案验证
既然 Dify 知识库召回效果不好,那就试试其他的 RAG 服务,之前也有调研过 QAnything 和 RagFlow 。
首先测试的 RagFlow,实际测试发现,RagFlow 解析文件很慢,多次尝试都解析失败:
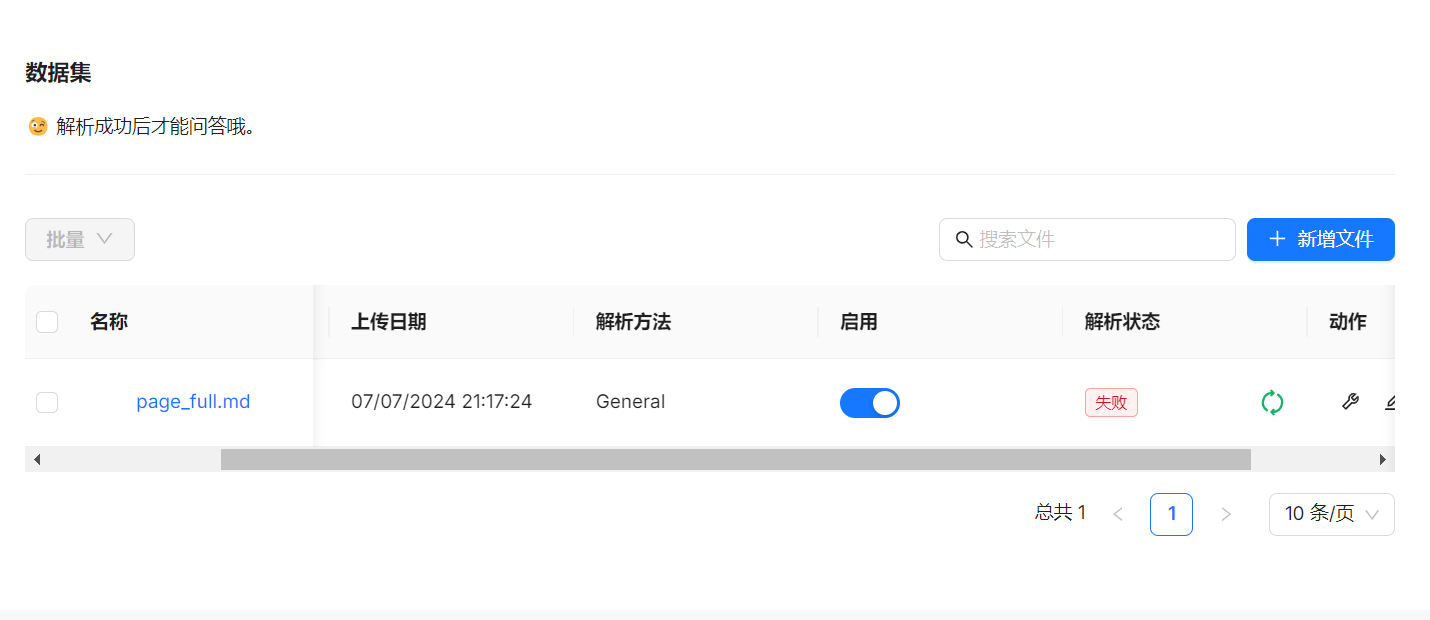
RagFlow 虽然主打文件精细化解析,但是这个可靠性是不是还得加强一下。
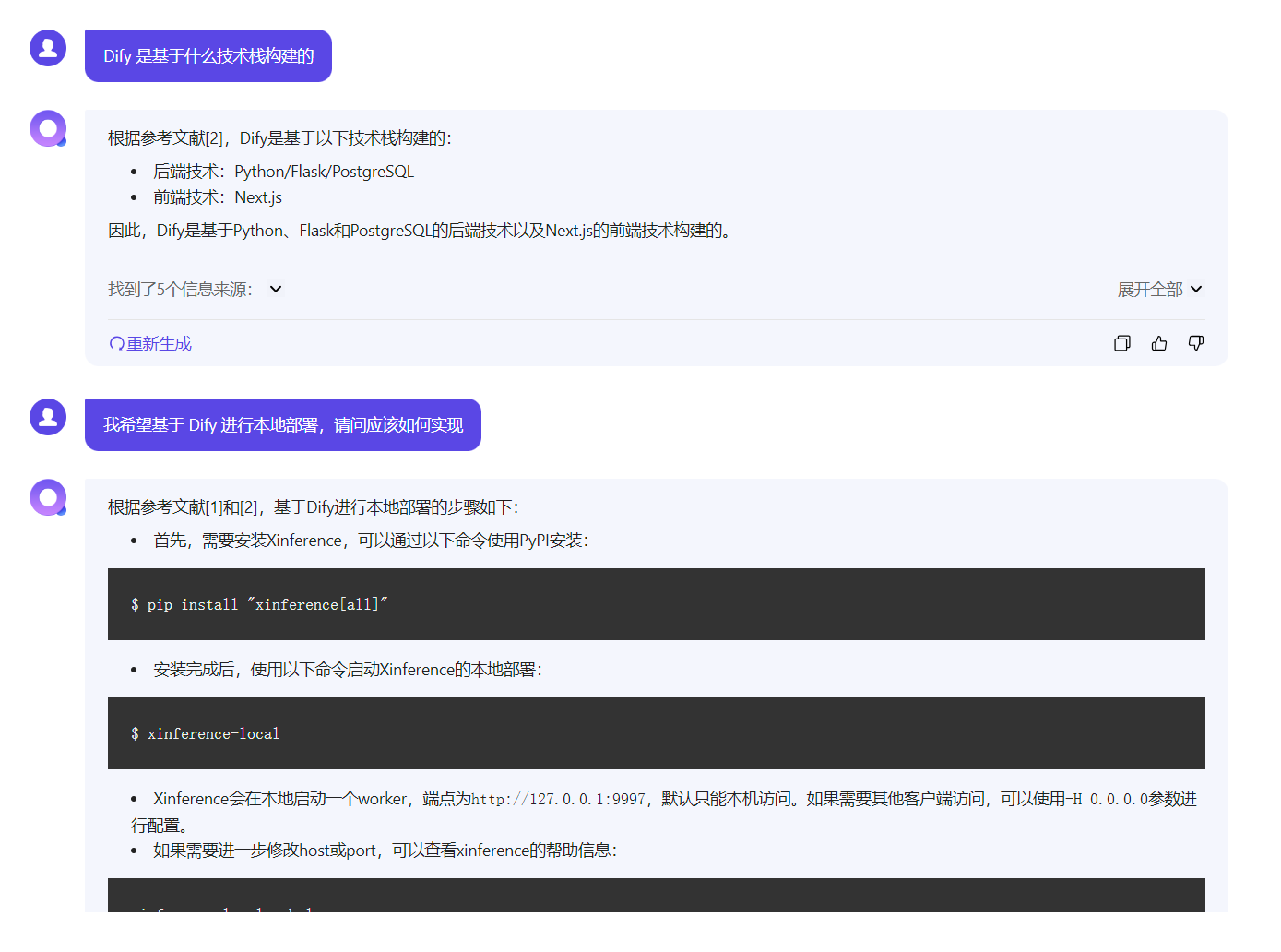
之后测试了 QAnything, 实际测试发现效果还不错,至少这些需要官方文档回答的问题都能正确回答。
Long Context 方案验证
实际 Dify 官方文档清洗后的文件仅为 4.32MB,对于常规的 Long Context 大模型都是够用的,因此基于 Kimi 尝试了 Long Context 的可行性,实际测试效果也还不错:
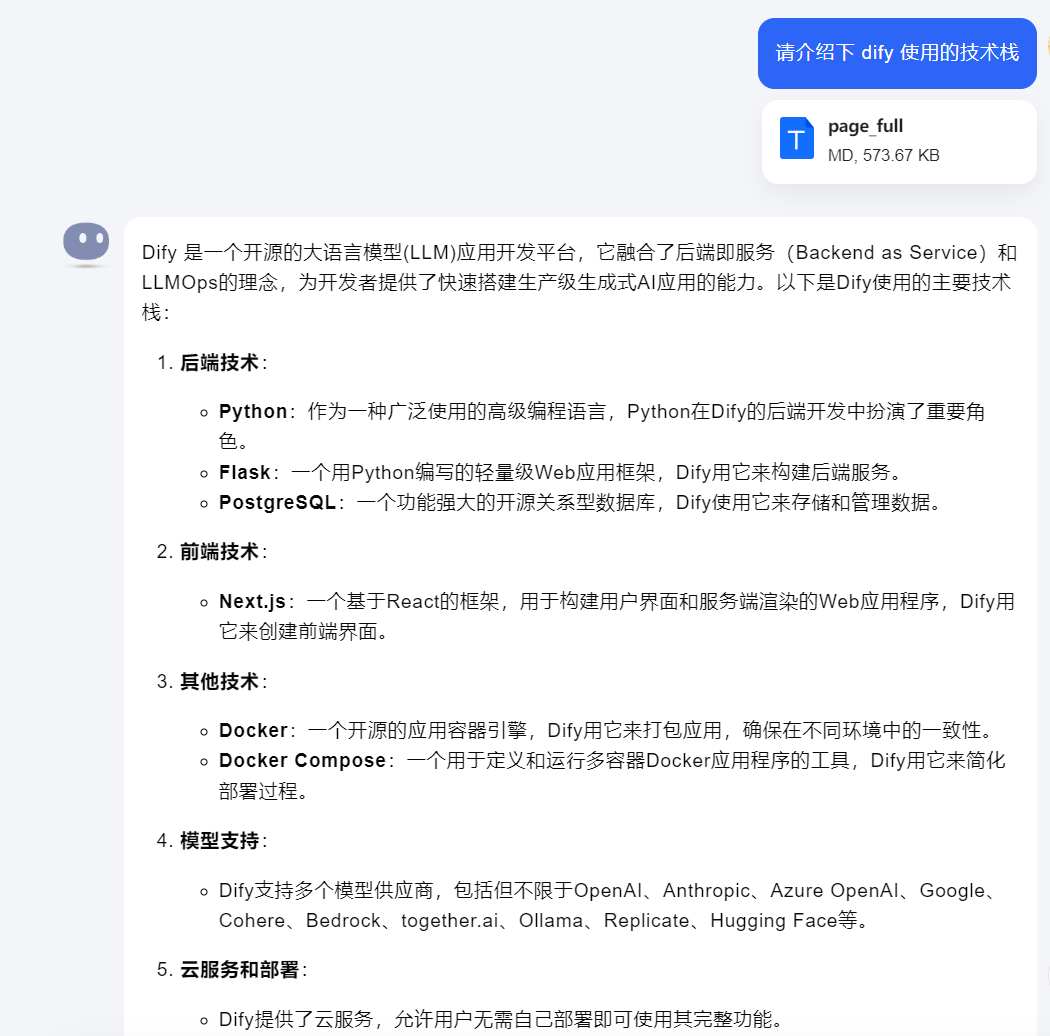
基于 Long Context 就不需要构建知识库了,但是在一段时间内反复使用会更麻烦一些,算是有得有失。
总结
在实际尝试的过程中,真实体验到世界就是一个巨大草台班子,特别是大模型服务草台班子的感觉更加明显,需要后续需要持续的完善。
从目前的实践的过程来看,基于官方文档的问答应该是可用的,可以一定程度上解决需要反复查官方文档的问题。如果有需要可以通过上面的流程可以实现快速的官方文档的采集和清洗,之后可以与 Kimi 和 QAnything 结合实现更细致的官方文档问答服务。