背景介绍
在 前一篇文章 中介绍过智谱组织的一个金融大模型 RAG 比赛 FinGLM 以及 ChatGLM反卷总局 团队的项目,这篇文章继续介绍下获得冠军的馒头科技的技术方案。
建议不了解比赛背景信息的可以先查看 来自工业界的知识库 RAG 服务(三),FinGLM 竞赛获奖项目详解,方便更好地理解技术方案的设计。
项目方案详解
方案设计
项目设计的整体流程如下所示:
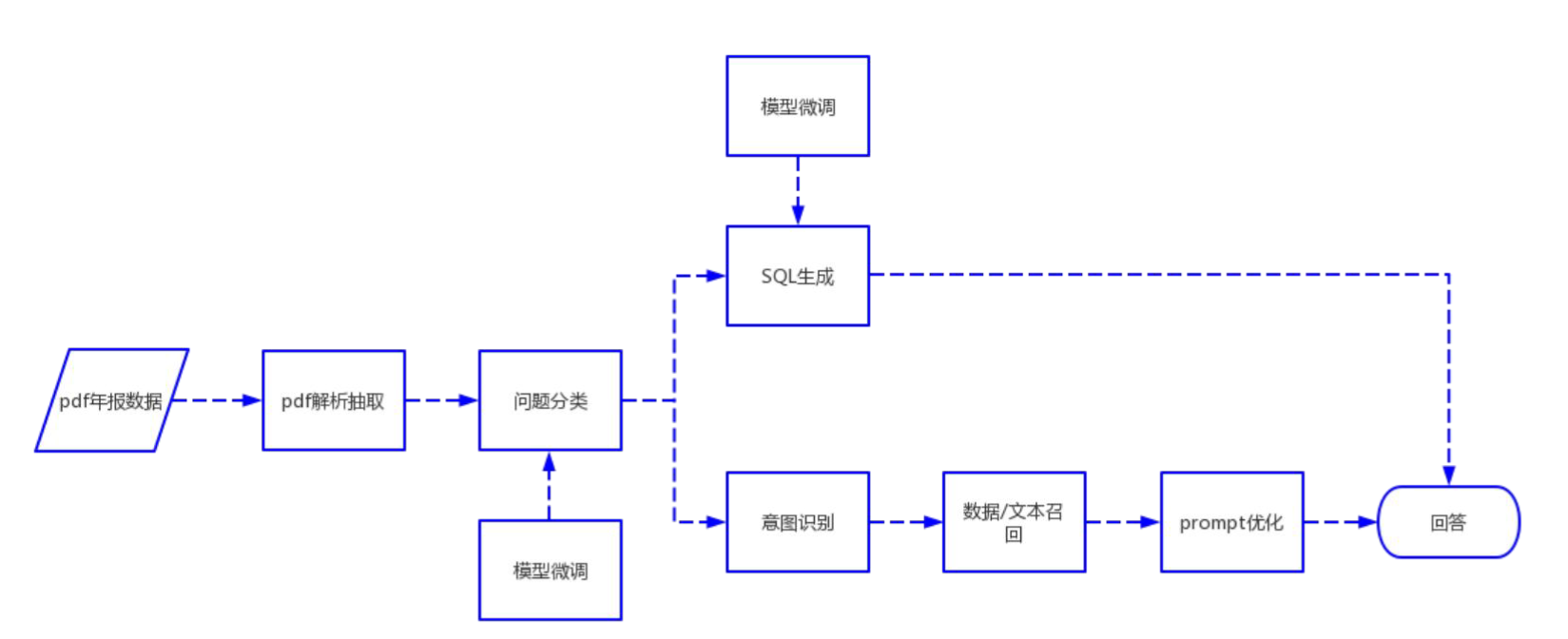
从当前的流程来看,项目的几个核心预处理模块包含:
- 问题分类,不同类型的问题需要采取的方案完全不同,在选择处理方案时需要先确定是什么类型的问题,方便进行有针对性的处理;
- SQL 生成,部分问题需要依赖 SQL 从数据库中的数据处理得到结果,因此需要具备根据问题生成 SQL 语句的能力;
- 关键词抽取,就是流程图中的意图识别模块,项目依赖关键词进行内容召回,因此需要具备准确提取关键词的能力;
上面的几个核心功能都是基于微调 ChatGLM-6B 模型来实现的。
微调模型预处理
上面提到的几个预处理的功能都是通过微调大模型实现的。实际问题回答流程基本就是调用微调后的大模型进行回答,差异不是很大。下面以问题分类为例查看其中的预处理流程,实际的调用如下所示:
def _get_classify_prompt(self, question) -> str:
classify_prompt = '''
请问“{}”是属于下面哪个类别的问题?
A: 公司基本信息,包含股票简称, 公司名称, 外文名称, 法定代表人, 注册地址, 办公地址, 公司网址网站, 电子信箱等.
B: 公司员工信息,包含员工人数, 员工专业, 员工类别, 员工教育程度等.
C: 财务报表相关内容, 包含资产负债表, 现金流量表, 利润表 中存在的字段, 包括费用, 资产,金额,收入等.
D: 计算题,无法从年报中直接获得,需要根据计算公式获得, 包括增长率, 率, 比率, 比重,占比等.
E: 统计题,需要从题目获取检索条件,在数据集/数据库中进行检索、过滤、排序后获得结果.
F: 开放性问题,包括介绍情况,介绍方法,分析情况,分析影响,什么是XXX.
你只需要回答字母编号, 不要回答字母编号及选项文本外的其他内容.
'''.format(question)
return classify_prompt
# 加载Classify训练权重后,来强化问题的分类能力,返回问题的类型字母编号
def classify(self, question: str):
classify_prompt = self._get_classify_prompt(question)
response, _ = self.model.chat(
self.tokenizer,
classify_prompt,
history=[],
max_length=cfg.CLASSIFY_PTUNING_PRE_SEQ_LEN,
top_p=1, do_sample=False,
temperature=0.001)
return response
可以看到基于微调模型的方案进行问题分类,实现过程相对简单,只需要构造对应的 prompt 即可。
关键词抽取和 SQL 生成的流程也是类似的,在 SQL 生成中额外在 prompt 使用 Few Shot 机制优化了效果,有兴趣可以查看其中的细节内容。
文本召回与回答
在经过前面的预处理环节后,接下来就可以基于根据问题分类的类型召回对应的数据源,并根据召回的信息使用大模型生成最终的结果。
表格数据召回与回答
表格数据的召回与回答的流程如下所示:
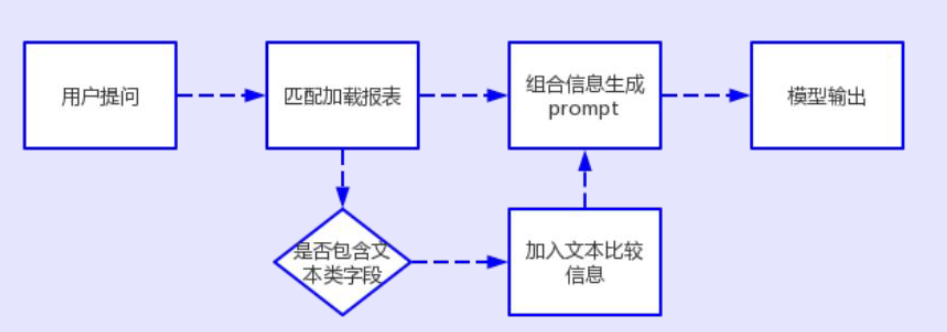
这种情况下就是基于提取的关键词与数据表进行逐行比较,选择最接近的数据进行返回,最后构造出数据提供给大模型进行回答。
公式类问题数据召回与回答
公式类问题数据召回和回答的流程如下所示:
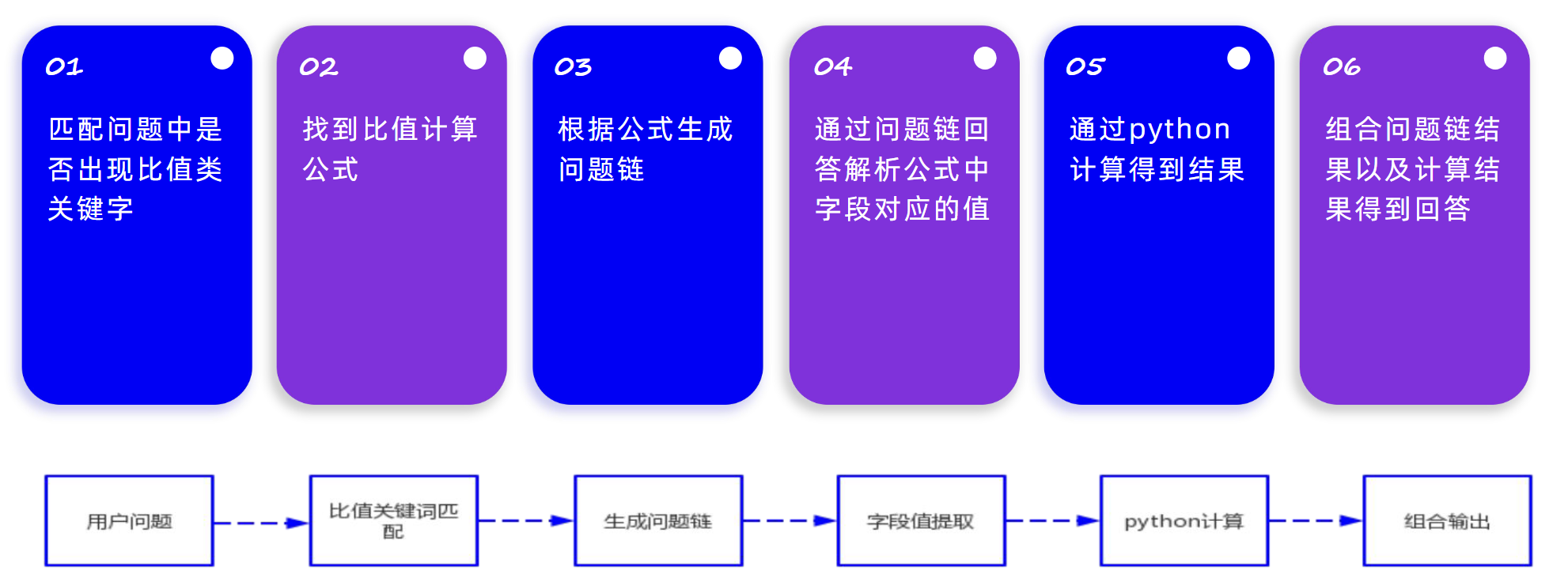
因为 ChatGLM-6B 实际进行数学计算时表现不佳,因此需要进行外部计算,根据匹配的关键词确定实际需要采取的计算公式,根据公式确定需要获取原始数据。使用原始的数据进行 Python 计算,之后将得到的结果提供给大模型输出最终的结果。
实际公式链的构造实现如下所示:
def get_step_questions(question, keywords, real_comp, year):
new_question = question
step_questions = []
question_keywords = []
variable_names = []
step_years = []
formula = None
question_formula = None
# 增长率问题链构造
if '增长率' in question:
if keywords == '增长率':
keywords = new_question
question_keywords = [keywords.replace('增长率', '')] * 2 + [keywords]
variable_names = ['A', 'B', 'C']
formula = '(A-B)/B'
question_formula = '根据公式,=(-上年)/上年'
for formula_key, formula_value in growth_formula():
if formula_key in new_question.replace('的', ''):
question_formula = '根据公式,{}={},'.format(formula_key, formula_value)
step_years = [year, str(int(year)-1), year]
step_questions.append(new_question.replace('增长率', ''))
step_questions.append(new_question.replace('增长率', '').replace(year, str(int(year)-1)))
step_questions.append(new_question)
else:
# 常规问题的问题链构造
formulas = get_formulas()
for k, v in formulas:
if k in new_question:
variable_names = get_keywords_of_formula(v)
formula = v
for name in variable_names:
if '人数' in question or '数量' in question or '人员' in question:
step_questions.append('{}年{}{}有多少人?如果已知信息没有提供, 你应该回答为0人。'.format(year, real_comp, name))
else:
step_questions.append('{}年{}的{}是多少元?'.format(year, real_comp, name))
question_keywords.append(name)
step_years.append(year)
question_formula = '根据公式,{}={}'.format(k, v)
break
return step_questions, question_keywords, variable_names, step_years, formula, question_formula
增长率是一个特殊情况,因为增长率需要获取前一年的数据,因此需要特殊处理。除此以外,其他就是根据实际的公式确定计算所需的字段,之后就可以生成对应的问题。
实际计算的过程就是依次调用上面生成的公式链,通过先获取所需的原始数据,然后提取所需的字段的数值。处理完之后调用 Python 提供的 eval() 计算得到最终结果。实现过程如下所示:
for step_question, step_keyword, step_year in zip( step_questions, step_keywords, step_years):
background = "已知{}{}年的资料如下:\n".format(
real_comp, step_year
)
# 从表格中召回所需的原始数据
matched_table_rows = recall_pdf_tables(
step_keyword,
[step_year],
pdf_table,
min_match_number=3,
top_k=5,
)
table_text = table_to_text(
real_comp,
ori_question,
matched_table_rows,
with_year=False,
)
if table_text != "":
background += table_text
question_for_model = prompt_util.get_prompt_single_question(
ori_question, real_comp, step_year
).format(background, step_question)
# 调用大模型获取用于计算的基础数据
step_answer = model(question_for_model)
variable_value = type2.get_variable_value_from_answer(
step_answer
)
if variable_value is not None:
step_answers.append(step_answer)
variable_values.append(variable_value)
# 将公式中的原始内容替换为计算得到的数据,执行数学计算
if len(step_questions) == len(variable_values):
for name, value in zip(variable_names, variable_values):
formula = formula.replace(name, value)
result = eval(formula)
文本类问题数据召回与回答
文本类问题需要召回文本内容,并将召回的文本内容提供给大模型得到最终的结果,主要流程如下所示:
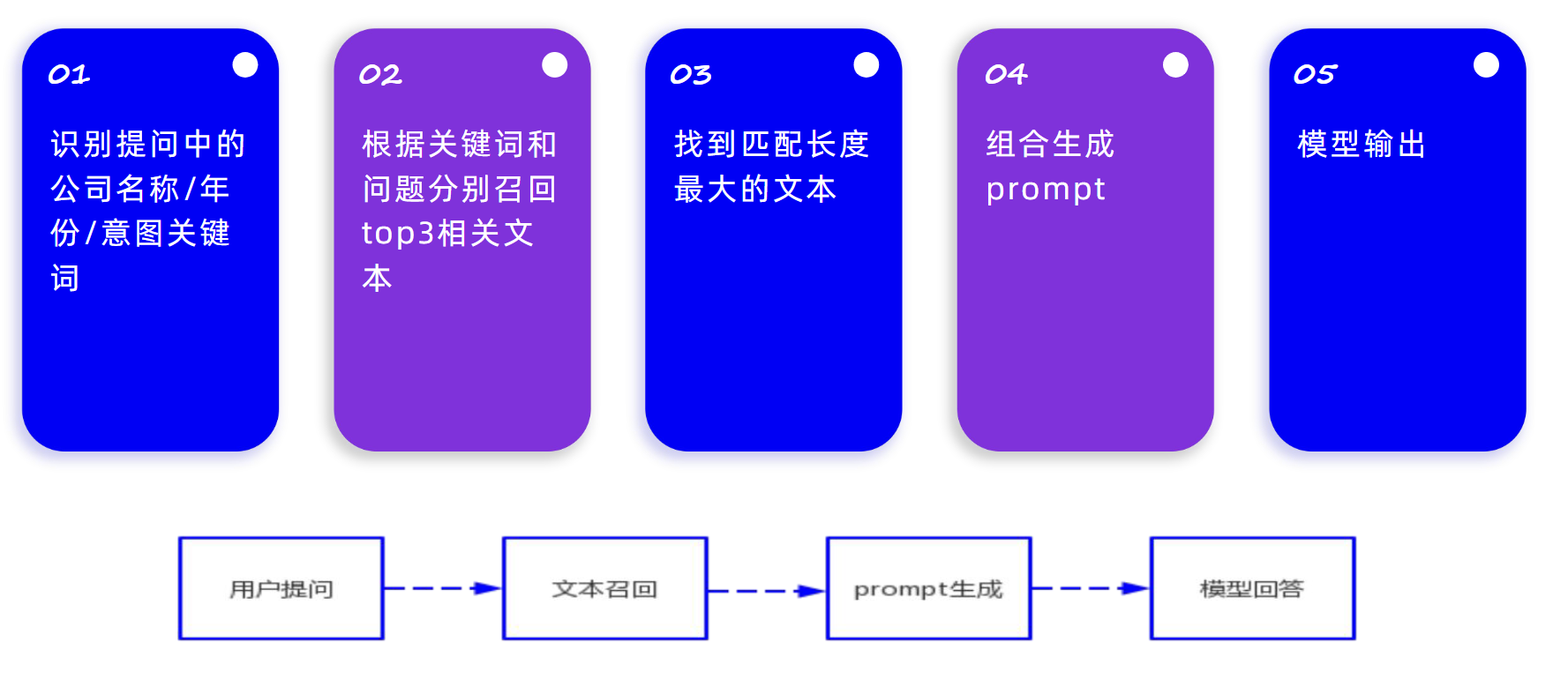
这种类型的问题比较类似常规的 RAG 系统中面临的问题,但是与常规的 RAG 系统基于向量检索不同,此项目使用的 BM25 检索,基于关键字进行检索。
项目检索是基于 fastbm25 实现,实现简化后如下所示:
text_pages = load_pdf_pages(key)
text_lines = list(itertools.chain(*[page.split('\n') for page in text_pages]))
text_lines = [line for line in text_lines if len(line) > 0]
# 基于原始文本初始化 fastbm25
model = fastbm25(text_lines)
# 使用问题中提取的关键词和原始问题分别进行检索
result_keywords = model.top_k_sentence(keywords, k=3)
result_question = model.top_k_sentence(anoy_question, k=3)
# 合并检索结果
top_match_indexes = [t[1] for t in result_question + result_keywords]
block_line_indexes = merge_idx(top_match_indexes, len(text_lines), 0, 30)
总结
本文主要整理了 FinGLM 获得冠军的团队提供的方案,从处理流程来看,亮点不是特别突出,最终表现良好与其精细的问题分类以及有针对性的微调模型应该有不少的关系。
结合目前梳理的几个获奖项目,存在如下一些值得参考的经验:
- 特定场景的大模型微调可以大幅提升效果,而且所需的数据量不大,可以在实际的场景下进行尝试;
- 关键词在需要精准匹配的情况下效果良好,可以与向量检索结合使用;