背景介绍
前面介绍过 有道 QAnything 源码解析,通过深入了解工业界的知识库 RAG 服务,得到了不少调优 RAG 服务的新想法。
因此本次趁热打铁,额外花费一点时间,深入研究了另一个火热的开源 RAG 服务 RagFlow 的完整实现流程,希望同样有所收获。
项目概述
框架设计
首先依旧可以先从框架图入手,与 常规的 RAG 架构 进行一些比较
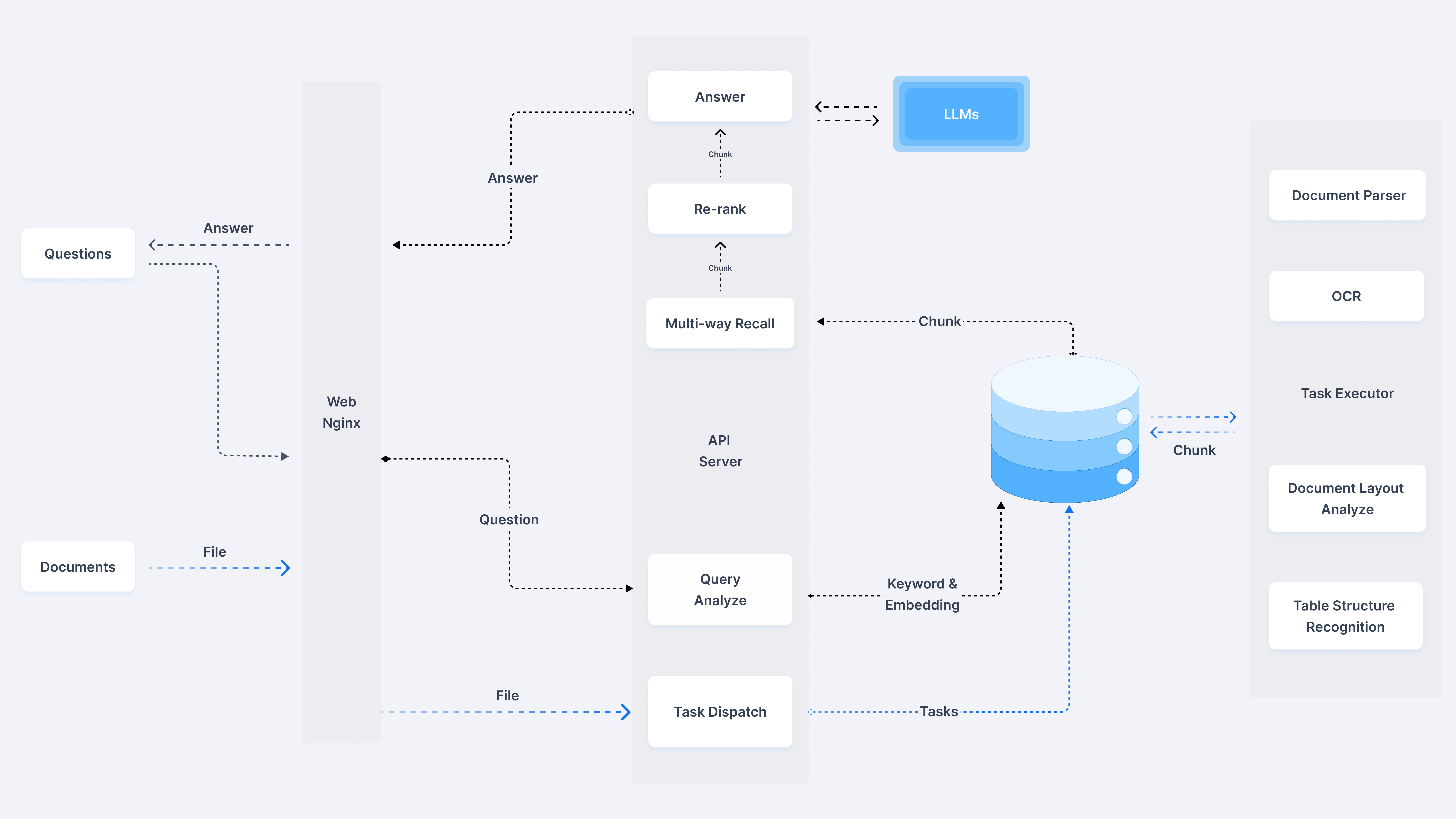
可以看到右侧知识库被明显放大,同时最右侧详细介绍了文件解析的各种手段,比如 OCR, Document Layout Analyze 等,这些在常规的 RAG 中可能会作为一个不起眼的 Unstructured Loader 包含进去,可以猜到 RagFlow 的一个核心能力在于文件的解析环节。
在 官方文档 中也反复强调 Quality in, quality out, 反映出 RAGFlow 的独到之处在于细粒度文档解析。
另外 介绍文章 中提到其没有使用任何 RAG 中间件,而是完全重新研发了一套智能文档理解系统,并以此为依托构建 RAG 任务编排体系,也可以理解文档的解析是其 RagFlow 的核心亮点。
源码结构
首先可以看到 RagFlow 的源码结构:
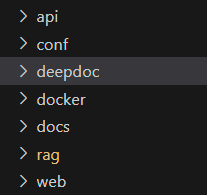
对应模块的功能如下:
- api 为后端的 API
- web 对应的是前端页面
- conf 为配置信息
- deepdoc 对应的就是文件解析模块
从代码结构就能看出文件解析 deepdoc 在 RAGFlow 中一等公民角色
另外相关的技术栈如下:
- Web 服务是基于 Flask 实现,这个在 2024 年来看稍微有一点点过时了
- 业务数据库使用的是 MySQL
- 向量数据库使用的是 ElasticSearch ,奇怪的是公司有自己的向量数据库 infinity 竟然默认没有用上
- 文件存储使用的是 MinIO
正如前面介绍的因为没有使用 RAG 中间件,比如 langchain 或 llamaIndex,因此实现上与常规的 RAG 系统会存在一些差异
源码解析
文件加载的支持
常规的 RAG 服务都是在上传时进行文件的加载和解析,但是 RAGFlow 的上传仅仅包含上传至 MinIO,需要手工点击触发文件的解析。
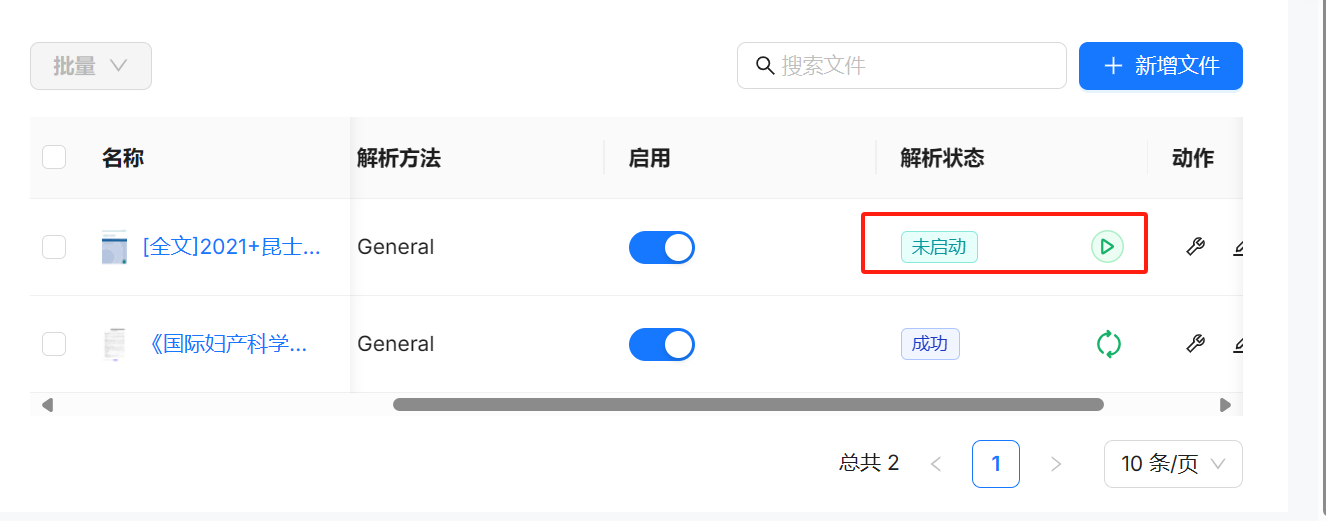
根据实际体验,以及网络上的反馈了解到 RAGFlow 的解析相当慢,估计资源开销也比较大,因此也能理解为什么采取二次手工确认的产品方案了。
实际的文件解析通过接口 /v1/document/run 进行触发的,实际的处理是在 api/db/services/task_service.py 中的 queue_tasks() 中完成的,此方法会根据文件创建一个或多个异步任务,方便异步执行。实现如下所示:
def queue_tasks(doc, bucket, name):
def new_task():
nonlocal doc
return {
"id": get_uuid(),
"doc_id": doc["id"]
}
tsks = []
# pdf 文件的解析,根据不同的类型设置单个任务最多处理的页数
# 默认单个任务处理 12 页 pdf,pager 类型的 pdf 一个任务处理 22 页,其他 pdf 不分页
if doc["type"] == FileType.PDF.value:
file_bin = MINIO.get(bucket, name)
do_layout = doc["parser_config"].get("layout_recognize", True)
pages = PdfParser.total_page_number(doc["name"], file_bin)
page_size = doc["parser_config"].get("task_page_size", 12)
if doc["parser_id"] == "paper":
page_size = doc["parser_config"].get("task_page_size", 22)
if doc["parser_id"] == "one":
page_size = 1000000000
if not do_layout:
page_size = 1000000000
page_ranges = doc["parser_config"].get("pages")
if not page_ranges:
page_ranges = [(1, 100000)]
for s, e in page_ranges:
s -= 1
s = max(0, s)
e = min(e - 1, pages)
for p in range(s, e, page_size):
task = new_task()
task["from_page"] = p
task["to_page"] = min(p + page_size, e)
tsks.append(task)
# 表格数据单个任务处理 3000 行
elif doc["parser_id"] == "table":
file_bin = MINIO.get(bucket, name)
rn = RAGFlowExcelParser.row_number(
doc["name"], file_bin)
for i in range(0, rn, 3000):
task = new_task()
task["from_page"] = i
task["to_page"] = min(i + 3000, rn)
tsks.append(task)
else:
tsks.append(new_task())
bulk_insert_into_db(Task, tsks, True)
DocumentService.begin2parse(doc["id"])
# 任务插入 Redis 消息队列,方便异步处理
for t in tsks:
assert REDIS_CONN.queue_product(SVR_QUEUE_NAME, message=t), "Can't access Redis. Please check the Redis' status."
从上面的实现来看,文件的解析是根据内容拆分为多个任务,通过 Redis 消息队列进行暂存,之后就可以离线异步处理。
直接查看对应的消息队列的消费模块,对应在 rag/svr/task_executor.py 中的 main() 方法中。实现简化后如下所示:
def main():
# 获取任务
rows = collect()
for _, r in rows.iterrows():
embd_mdl = LLMBundle(r["tenant_id"], LLMType.EMBEDDING, llm_name=r["embd_id"], lang=r["language"])
# 执行文件解析
cks = build(r)
# 执行向量化
tk_count = embedding(cks, embd_mdl, r["parser_config"], callback)
init_kb(r)
# 写入 ES
es_r = ELASTICSEARCH.bulk(cks, search.index_name(r["tenant_id"]))
完整的处理流程如下所示:
- 调用
collect()方法从消息队列中获取任务 - 接下来每个任务会依次调用
build()进行文件的解析 - 调用
embedding()方法进行向量化 - 最后调用
ELASTICSEARCH.bulk()写入 ElasticSearch,从这里就可以看到向量库的技术选型
接下来主要关注 build() 方法深入 RAGFlow 核心的文件解析,具体的实现简化后如下所示:
def build(row):
# 根据类型选择合适的解析器
chunker = FACTORY[row["parser_id"].lower()]
# 执行文档的解析和切片
cks = chunker.chunk(
row["name"],
binary=binary,
from_page=row["from_page"],
to_page=row["to_page"],
lang=row["language"],
callback=callback,
kb_id=row["kb_id"],
parser_config=row["parser_config"],
tenant_id=row["tenant_id"],
)
实际是根据 parser_id 去选择合适的解析器组,注意这个应该是从业务层得到的一个类型,每个解析器组中都包含了 pdf, word 等支持格式的文件解析,可以理解为一个使用场景的属性。这个会不会导致后续使用场景较多情况下,出现 N (场景) * N (文件格式) 的组合情况可能值得考虑,后续可能会进行优化。
以默认的 naive 类型为例深入对应的 chunk() 实现,其对应的实现在 rag/app/naive.py 中。此方法中包含了目前主持的 docx, pdf, xlsx, md 等格式的解析,我们以 pdf 为例深入查看对应的实现。
可以看到解析器是继承自 deepdoc/parser/pdf_parser.py 中的 RAGFlowPdfParser 实现,终于进入深度文档解析环节了。
pdf 文件的打开是基于 PyPDF2 实现,并基于 pdfplumber 实现表格数据的提取,这个库相对 PyMuPDF 速度更慢,但是可以处理得更精细。
另外使用的 OCR 模型为 /InfiniFlow/deepdoc,在解析中额外加载了一个 XGB 模型 InfiniFlow/text_concat_xgb_v1.0 用于内容提取。
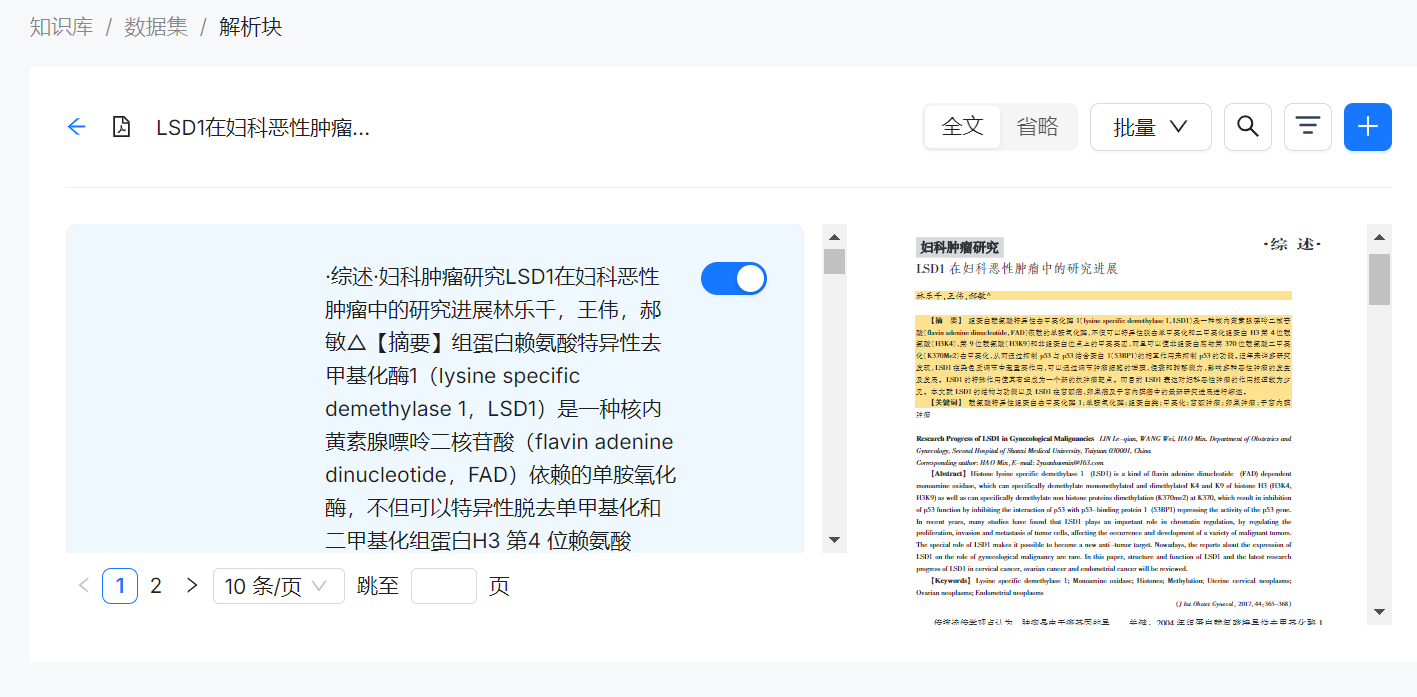
实际的解析过程写的也很复杂,无怪乎处理速度有点慢。不过预期处理效果相对其他 RAG 项目也会好一些。从实际前端的展示的 Demo 来看,RAGFlow 可以将解析后的文本块与原始文档中的原始位置关联起来,这个效果还是比较惊艳的,目前看起来只有 RagFlow 实现了类似的效果。
文件的预处理策略
在 RAGFlow 中的文件中包含了不少了数据的清理操作,比如在 deepdoc/vision/layout_recognizer.py 中的就包含着文档中无用内容的判断,示例如下:
def __is_garbage(b):
patt = [r"^•+$", r"(版权归©|免责条款|地址[::])", r"\.{3,}", "^[0-9]{1,2} / ?[0-9]{1,2}$",
r"^[0-9]{1,2} of [0-9]{1,2}$", "^http://[^ ]{12,}",
"(资料|数据)来源[::]", "[0-9a-z._-]+@[a-z0-9-]+\\.[a-z]{2,3}",
"\\(cid *: *[0-9]+ *\\)"
]
return any([re.search(p, b["text"]) for p in patt])
文档中版权内容,参考来源信息等内容会被清理。但是这样处理比较分散,而且不同的流程中也充斥着大量的特殊处理,导致从源码很难拆分出明确的预处理逻辑。
从常规的流程来看,RAGFlow 将提取的内容分为普通的文本内容 + 表格,分别对这两部分内容进行 tokenize, 方便进行检索。
文件检索的支持 (包含混合检索)
文件检索的支持可以查看实际的对话处理流程,对话的 API 为 /v1/conversation/completion,实际对话的处理是在 api/db/services/dialog_service.py 中的 chat() 方法中完成
深入跟踪对话处理流程,可以看到文件的检索是在 rag/nlp/search.py 中的 search() 方法中完成。
RAGFlow 的检索目前实现的是混合检索,实现的是文本检索 + 向量检索,混合检索完全依赖 ElasticSearch 实现,具体的实现如下所示:
def search(self, req, idxnm, emb_mdl=None):
qst = req.get("question", "")
bqry, keywords = self.qryr.question(qst)
bqry = add_filters(bqry)
bqry.boost = 0.05
# 构造 ElasticSearch 文本查询的请求
s = Search()
pg = int(req.get("page", 1)) - 1
ps = int(req.get("size", 1000))
topk = int(req.get("topk", 1024))
src = req.get("fields", ["docnm_kwd", "content_ltks", "kb_id", "img_id", "title_tks", "important_kwd",
"image_id", "doc_id", "q_512_vec", "q_768_vec", "position_int",
"q_1024_vec", "q_1536_vec", "available_int", "content_with_weight"])
s = s.query(bqry)[pg * ps:(pg + 1) * ps]
s = s.highlight("content_ltks")
s = s.highlight("title_ltks")
if not qst:
if not req.get("sort"):
s = s.sort(
{"create_time": {"order": "desc", "unmapped_type": "date"}},
{"create_timestamp_flt": {
"order": "desc", "unmapped_type": "float"}}
)
else:
s = s.sort(
{"page_num_int": {"order": "asc", "unmapped_type": "float",
"mode": "avg", "numeric_type": "double"}},
{"top_int": {"order": "asc", "unmapped_type": "float",
"mode": "avg", "numeric_type": "double"}},
{"create_time": {"order": "desc", "unmapped_type": "date"}},
{"create_timestamp_flt": {
"order": "desc", "unmapped_type": "float"}}
)
if qst:
s = s.highlight_options(
fragment_size=120,
number_of_fragments=5,
boundary_scanner_locale="zh-CN",
boundary_scanner="SENTENCE",
boundary_chars=",./;:\\!(),。?:!……()——、"
)
s = s.to_dict()
# 补充向量查询的信息
q_vec = []
if req.get("vector"):
assert emb_mdl, "No embedding model selected"
s["knn"] = self._vector(
qst, emb_mdl, req.get(
"similarity", 0.1), topk)
s["knn"]["filter"] = bqry.to_dict()
if "highlight" in s:
del s["highlight"]
q_vec = s["knn"]["query_vector"]
# 将构造的完整查询提交给 ElasticSearch 进行查询
res = self.es.search(deepcopy(s), idxnm=idxnm, timeout="600s", src=src)
kwds = set([])
for k in keywords:
kwds.add(k)
for kk in rag_tokenizer.fine_grained_tokenize(k).split(" "):
if len(kk) < 2:
continue
if kk in kwds:
continue
kwds.add(kk)
aggs = self.getAggregation(res, "docnm_kwd")
return self.SearchResult(
total=self.es.getTotal(res),
ids=self.es.getDocIds(res),
query_vector=q_vec,
aggregation=aggs,
highlight=self.getHighlight(res),
field=self.getFields(res, src),
keywords=list(kwds)
)
可以看到 RAGFlow 将混合检索需求转换为复杂的查询条件,利用 elasticsearch-dsl 进行复杂查询的构造,之后直接提交给 ElasticSearch 即可。
检索结果的重排
文件的重排是在 rag/nlp/search.py 中的 rerank() 中完成的,重排是基于文本匹配得分 + 向量匹配得分混合进行排序,默认文本匹配的权重为 0.3, 向量匹配的权重为 0.7,对应的实现如下所示:
# tkweight 为文本匹配权重,vtweight 为向量匹配权重
def rerank(self, sres, query, tkweight=0.3,
vtweight=0.7, cfield="content_ltks"):
# 获取文本关键词
_, keywords = self.qryr.question(query)
# 获取文本向量
ins_embd = [
Dealer.trans2floats(
sres.field[i].get("q_%d_vec" % len(sres.query_vector), "\t".join(["0"] * len(sres.query_vector)))) for i in sres.ids]
if not ins_embd:
return [], [], []
for i in sres.ids:
if isinstance(sres.field[i].get("important_kwd", []), str):
sres.field[i]["important_kwd"] = [sres.field[i]["important_kwd"]]
ins_tw = []
for i in sres.ids:
content_ltks = sres.field[i][cfield].split(" ")
title_tks = [t for t in sres.field[i].get("title_tks", "").split(" ") if t]
important_kwd = sres.field[i].get("important_kwd", [])
tks = content_ltks + title_tks + important_kwd
ins_tw.append(tks)
# 获取整体相似分,文本相似分,向量相似分
sim, tksim, vtsim = self.qryr.hybrid_similarity(sres.query_vector,
ins_embd,
keywords,
ins_tw, tkweight, vtweight)
return sim, tksim, vtsim
获取混合相似分之后,基于混合的相似分进行过滤和重排,默认混合得分低于 0.2 的会被过滤掉
大模型的处理
在进行上面的检索和重排阶段中,只是进行了必要的过滤,没有限制匹配文档的数量。
实际内容可能会超过大模型的输入 token 数量,因此在调用大模型前会调用 api/db/services/dialog_service.py 文件中 message_fit_in() 根据大模型可用的 token 数量进行过滤。这部分与有道的 QAnything 的实现大同小异,就不额外展开了。
将检索的内容,历史聊天记录以及问题构造为 prompt,即可作为大模型的输入了,默认的英文 prompt 如下所示:
"""
You are an intelligent assistant. Please summarize the content of the knowledge base to answer the question. Please list the data in the knowledge base and answer in detail. When all knowledge base content is irrelevant to the question, your answer must include the sentence "The answer you are looking for is not found in the knowledge base!" Answers need to consider chat history.
Here is the knowledge base:
{knowledge}
The above is the knowledge base.
"""
对应的中文 prompt 如下所示:
"""
你是一个智能助手,请总结知识库的内容来回答问题,请列举知识库中的数据详细回答。当所有知识库内容都与问题无关时,你的回答必须包括“知识库中未找到您要的答案!”这句话。回答需要考虑聊天历史。
以下是知识库:
{knowledge}
以上是知识库
"""
总结
通过上面的介绍,可以对开源的 RagFlow 有了一个大致的了解,与前面的 有道 QAnything 整体流程还是比较类似的。同样支持混合检索,文本检索的方案都是基于 ElasticSearch 实现,在检索后都实现了 Rerank 流程,并在进入大模型之前基于可用最大 token 进行动态过滤。
不过对比来看,来自互联网大厂有道的 QAnything 的代码质量高很多,实现功能封装与命名都相当简洁易懂,工程的鲁棒性也明显高出一大截。如果想要通过源码了解 RAG 服务推荐优先阅读 QAnything。
当然 RagFlow 也有一些独到之处,对于文件的细粒度处理带来更高质量的参考信息,从而更好的提升参考信息,如果对这部分感兴趣可以深入了解下 RagFlow 的相关代码实现细节。