背景信息
在最初接触 FATE 源码时就整理过 FATE Flow 源码解析 - 作业提交处理流程,文章整理了 FATE 是如何接收用户提交的作业 (job),然后将作业拆分为独立的任务 (task),然后执行完成各个任务,在这个过程中不断更新作业(job)的执行进度,直到最终完成整个作业(job)。如果期望对 FATE 作业提交的执行流程有一个基础的认识,可以详细了解下之前的文章。
这篇文章是前面文章的补充,期望进一步深入探索 FATE 中提交的作业(job)是如何被如何被拆分,以及各个任务是如何确定对应的执行代码,以及如何在任务之间完成数据的传递。期望读完这篇文章,提交的任何作业,都可以快速明确预期执行链路,出现问题也快速定位。
作业提交
用户在使用 FATE 提交作业时,最重要的一个文件就是对应的 dsl 文件,其中包含了本次作业中执行的组件列表(component),组件是对复杂作业的分解,以之前描述过的纵向联邦线性回归为例,对应的 dsl 文件如下所示:
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"data_transform_0": {
"module": "DataTransform",
"input": {
"data": {
"data": [
"reader_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"intersection_0": {
"module": "Intersection",
"input": {
"data": {
"data": [
"data_transform_0.data"
]
}
},
"output": {
"data": [
"data"
]
}
},
"hetero_linr_0": {
"module": "HeteroLinR",
"input": {
"data": {
"train_data": [
"intersection_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
}
}
}
从 dsl 文件可以比较直观了解算法需要包含哪些内容,可以看到其中的 components 下面包含了四个基础组件,最终完成算法时会执行这四块内容:
| 组件名(用于关联输入输出) | 组件模块名(用于注册实现代码) | 功能解释 |
|---|---|---|
| reader_0 | Reader | 数据读取 |
| data_transform_0 | DataTransform | 数据转换 |
| intersection_0 | Intersection | 数据集合求交 |
| hetero_linr_0 | HeteroLinR | 纵向线性回归算法 |
通过 dsl 可以很容易理解 FATE 纵向联邦线性回归的实现方案,整体的流程也比较清晰了。但是 FATE 是如何基于 dsl 运行的,这就是这篇文章关注的重点。
执行流程串联
这边对 FATE 中作业的执行的完整流程进行串联,本文侧重于了解作业内组件的执行流程,考虑到流程涉及的链路过多,因此会省略不必要的细节,可以结合 FATE Flow 源码解析 - 作业提交处理流程 补充作业执行细节。
作业提交
用户提交对应的入口是 python/fate_flow/apps/job_app.py 中的 submit_job() ,实际的处理由 DAGScheduler.submit() 完成。
我们最重要的是跟踪 dsl 数据的传递与处理过程,作业提交中最重要的一部分内容就是 FederatedScheduler.create_job() 通知各个参与方去创建作业(job)与任务(task)。此方法内部封装的就是一个 RPC 请求,实际调用 python/fate_flow/scheduling_apps/party_app.py 中 /<job_id>/<role>/<party_id>/create 接口。
参与方收到请求后会创建对应的作业(job)与任务(task)。任务的创建对应的实现在 python/fate_flow/controller/job_controller.py 中, 具体如下所示:
def initialize_task_holder_for_scheduling(cls, role, party_id, components, common_task_info, provider_info):
for component_name in components:
task_info = {}
task_info.update(common_task_info)
task_info["component_name"] = component_name
task_info["component_module"] = ""
task_info["provider_info"] = provider_info
task_info["component_parameters"] = {}
TaskController.create_task(role=role, party_id=party_id,
run_on_this_party=common_task_info["run_on_this_party"],
task_info=task_info)
可以看到,实际是通过遍历 components 依次创建 task,即每个组件 (component) 会对应创建一个 task。那么上面的例子中,纵向联邦线性回归会创建 4 个对应的 task,后续只需要深入了解任务(task)的执行流程对应的就是组件(component)的执行。图示如下所示:
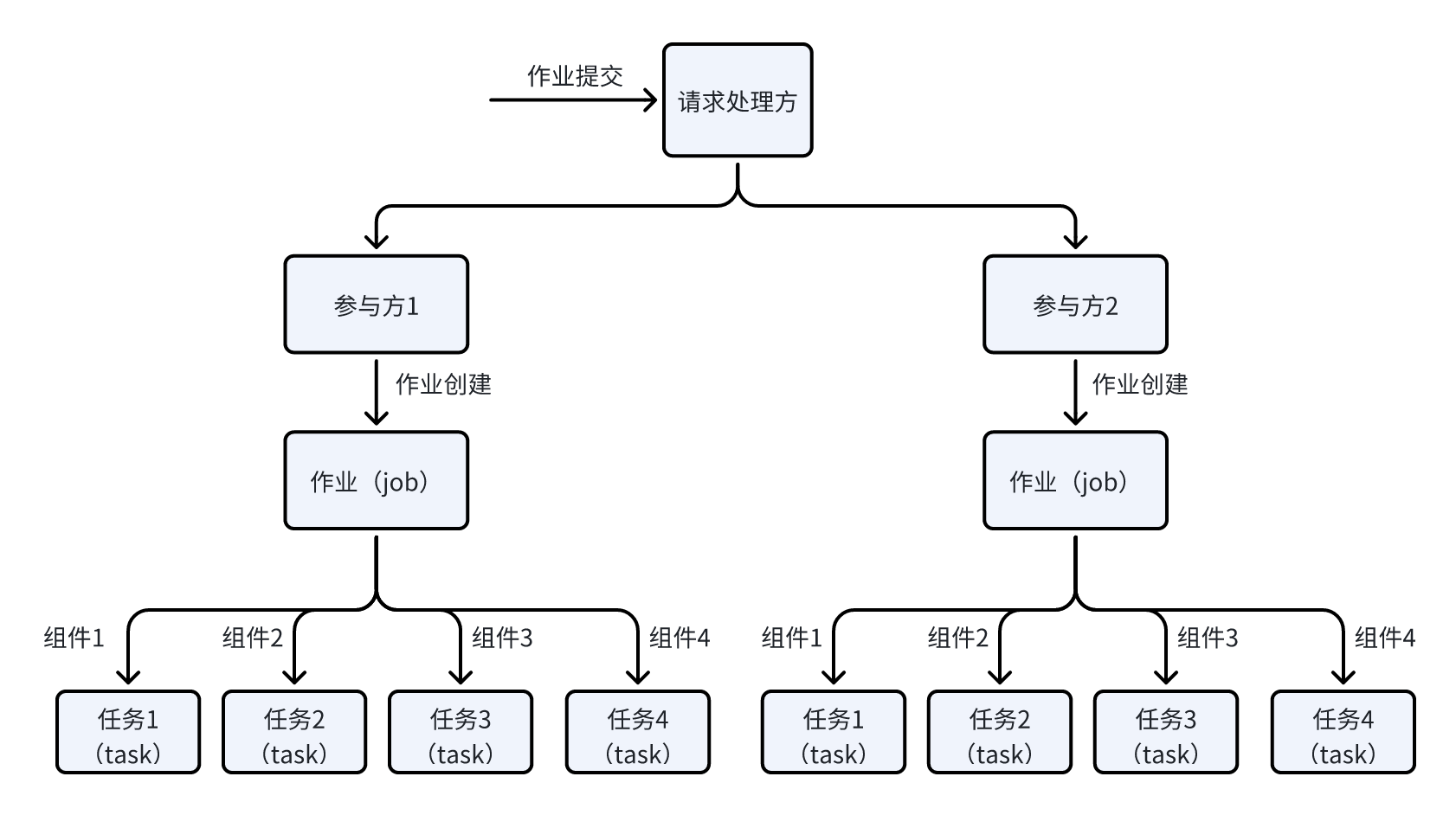
作业执行
在作业创建完成后,会确定作业前置依赖是否完成,并执行对应的资源申请,直到一切就绪之后,才能开始调度执行。实际执行入口为 python/fate_flow/scheduler/dag_scheduler.py 中对应的 DAGScheduler.run_do() 方法,此方法执行 job 的状态流转,并将就绪的 job 调用 schedule_running_job() 运行起来。
此方法会以 task 为单位执行 job,确定 task 相关的资源就绪后,最终会调用 FederatedScheduler.start_task() 通知各个参与方执行 task。这个同样是一个 RPC 请求,最终调用的是 python/fate_flow/scheduling_apps/party_app.py 文件中 start_task() 执行任务,与前面创建 job 时的套路是一样的。
参与方上 task 执行的是在 TaskController.start_task() 完成的,task 首先会选择执行引擎(Engine),目前 FATE 支持三种执行引擎 EGGROLL,SPARK,LINKIS_SPARK。
不同的执行引擎只是执行环境上有差异,最终完成的事情都是一样的。下面以 FATE 自研的 EggrollEngine 为例,可以看到最终就是调用了 python/fate_flow/manager/worker_manager.py 中的 WorkerManager.start_task_worker() 完成 task 执行的,具体如下:
def start_task_worker(cls, worker_name, task: Task, task_parameters: RunParameters = None,
executable: list = None, extra_env: dict = None, **kwargs):
# 实际执行的 python 代码,对应的路径为 python/fate_flow/worker/task_executor.py
if worker_name is WorkerName.TASK_EXECUTOR:
from fate_flow.worker.task_executor import TaskExecutor
module_file_path = sys.modules[TaskExecutor.__module__].__file__
if executable:
process_cmd = executable
else:
process_cmd = [env.get("PYTHON_ENV") or sys.executable or "python3"]
# 构造本地命令行
common_cmd = [
module_file_path,
"--job_id", task.f_job_id,
"--component_name", task.f_component_name,
]
process_cmd.extend(common_cmd)
# 创建新进程,执行命令,实际执行 python3 python/fate_flow/worker/task_executor.py --job_id xxx --component_name xxx
p = process_utils.run_subprocess(job_id=task.f_rjob_id, config_dir=config_dir, process_cmd=process_cmd,
added_env=env, log_dir=log_dir, cwd_dir=config_dir, process_name=worker_name.value,
process_id=worker_id)
可以看到,最终实际的执行可以等价于在命令行直接执行 python3 python/fate_flow/worker/task_executor.py --job_id xxx --component_name xxx,FATE 会在独立的进程直接执行对应的 python 脚本。而作业 id 与组件名是通过命令行参数传递的。
任务执行流程
任务执行是在 python/fate_flow/worker/task_executor.py 中的 TaskExecutor._run_() 方法上完成的,最核心的功能就是根据组件名(component_name)确定组件对应的模块,然后确定模块对应的代码。简化后如下所示:
def _run_(self):
# 根据 component_name 确定对应的组件
component = dsl_parser.get_component_info(component_name=args.component_name)
# 根据组件获取对应的组件模块名,用于关联实现代码,即上面文件中 Reader,DataTransform,Intersection,HeteroLinR
module_name = component.get_module()
# 根据组件模块名确定注册的实现模块
run_object = provider_interface.get(module_name, ComponentRegistry.get_provider_components(provider_name=component_provider.name, provider_version=component_provider.version)).get_run_obj(self.args.role)
# 实际执行对应模块的代码
cpn_output = run_object.run(cpn_input)
而对应的可执行对象 run_object 到底是如何确定的呢?其对应的基类为 python/fate_flow/components/_base.py 中的 ComponentMeta 类,可以看到其中包含了 get_run_obj() 可以获取可执行对象,此对象包含 run() 方法用于执行业务逻辑。
而相关的组件的注册也是通过 ComponentMeta 类来完成的,FATE-Flow 项目中全局搜索可以看到对应的组件列表:

通过上面的图示可以看到通过 ComponentMeta 注册组件时使用的就是组件模块名,这也能理解为什么是通过组件模块名确定对应的组件实现模块的。
我们以上面使用的 Reader 组件为例来简单查看实现的结构,其对应的实现在 python/fate_flow/components/reader.py 中:
reader_cpn_meta = ComponentMeta("Reader")
@reader_cpn_meta.bind_runner.on_guest.on_host
class Reader(ComponentBase):
def _run(self, cpn_input: ComponentInputProtocol):
...
可以看到会使用组件模块名 Reader 初始化 ComponentMeta 对象,接下来使用 @reader_cpn_meta.bind_runner 装饰器绑定对应的执行对象,此对象会实现 _run() 方法,其中包含的就是主要的逻辑实现。
但是最终获取匹配组件时只会调用 run() 方法呀,秘密就藏在对应的基类 ComonentBase 中。 此基类实现了 run() 方法,而此方法中会调用 _run() 完成主要的功能,因此也就能理解上面实际执行中 run_object.run() 的设计了。
算法任务执行流程
前面的 FATE-Flow 工程中图示中可以看到 Reader 对应的组件,但是纵向联邦线性回归中其他的组件都没有看到,其对应的实现都是在 FATE 项目 中的。
深入查看 FATE 项目对应的实现,就会发现 FATE 项目中 python/federatedml/components/components.py 也存在一个基本一样的 ComponentMeta 类,用于组件的注册,而大部分的算法相关的组件都是实现在 FATE 项目中的。我们就以上面用到的 HeteroLinR 组件为例看看算法组件的实现。
实际去查看 HeteroLinR 组件可以看到对应的注册方式与前面的 Reader 组件基本一样:
hetero_linr_cpn_meta = ComponentMeta("HeteroLinR")
# 注册 guest 角色执行类
@hetero_linr_cpn_meta.bind_runner.on_guest
def hetero_linr_runner_guest():
from federatedml.linear_model.coordinated_linear_model.linear_regression.hetero_linear_regression.hetero_linr_guest import (
HeteroLinRGuest, )
return HeteroLinRGuest
实际去查看算法组件的实现类 HeteroLinRGuest 可能就会发现一些差异,可以看到实现的方法如下:
class HeteroLinRGuest(HeteroLinRBase):
def fit(self, data_instances, validate_data=None):
...
def predict(self, data_instances):
...
算法组件只实现了 fit() 与 predict() 方法,分别对应于算法训练与推理功能,根据前面的介绍,预期算法组件应该执行 run() 方法,一路追踪到算法组件的基类。此基类为位于 python/federatedml/model_base.py 中的 ModelBase ,在此类中就实现了 run() 方法,此方法同样是调用 _run() 完成主要功能。
但是与前面的组件不同之处在于,ModelBase 的 _run() 中会根据实际输入生成一个方法列表,然后依次执行。生成方法列表中最重要一部分实现是 python/federatedml/util/component_properties.py 中的 ComponentProperties._train_process() 方法,具体如下:
def _train_process(self, running_funcs, model, train_data, validate_data, test_data, schema):
# 仅有训练集的情况
elif self.has_train_data:
running_funcs.add_func(model.set_flowid, ['fit'])
running_funcs.add_func(model.fit, [train_data])
running_funcs.add_func(model.set_flowid, ['validate'])
running_funcs.add_func(model.predict, [train_data], save_result=True)
# 不存在训练接,仅有测试集,属于推理阶段
elif self.has_test_data:
running_funcs.add_func(model.set_flowid, ['predict'])
running_funcs.add_func(model.predict, [test_data], save_result=True)
return running_funcs
可以看到根据数据集的不同,执行的方法列表也不同。存在训练集的情况下,会执行 fit() 方法用于模型训练,而存在测试集的情况下就一定会生成 predict() 方法用于推理。看到这边也就能理解前面算法组件的实现了。
任务间数据传递
从前面的介绍可以知道,算法组件是通过独立进程执行的,考虑进程之间是隔离的,数据不能直接共享,那么就需要明确下数据是如何传递的呢?实际作业执行中,后续任务的输入很有可能是前面任务执行的输出。比如 DataTransform 组件对应的任务需要执行数据转换,必然会依赖 Reader 组件对应的任务先读取到数据。
数据的传递细节其实都隐藏在 python/fate_flow/worker/task_executor.py 中的 TaskExecutor._run_() 方法执行过程中,我们只需要关注组件执行输出 cpn_output 的传递路径就可以发现,最终所有的输出会调用 python/fate_flow/operation/job_tracker.py 中的 Tracker.save_output_data() 方法进行持久化。
def save_output_data(...):
if computing_table:
...
# 输出数据持久化
session.Session.persistent(computing_table=computing_table,
namespace=output_table_namespace,
name=output_table_name,
schema=schema,
part_of_data=part_of_data,
engine=output_storage_engine,
engine_address=output_storage_address,
token=token)
return output_table_namespace, output_table_name
输出数据存储时会关联上对应的 table_namespace 和 table_name
而组件输入数据的构造主要来自于 TaskExecutor.get_task_run_args(),深入实现可以看到获取对应的 table_namespace 和 table_name 然后获取对应的数据的流程,具体就不额外展开了,感兴趣的可以自行探索。
总结
通过这篇文章的介绍,我们梳理了 FATE 作业执行的完整流程,简单总结下其中涉及的关键信息:
1、FATE 作业提交的 dsl 文件中会定义作业中包含的组件(component)列表,FATE 收到请求后会创建对应的作业(job), 然后为每个组件(component)生成对应的任务(task);
2、每个任务(task)使用独立的进程进行执行,实际执行是根据组件对应的组件模块名确定对应的组件执行代码,实际的执行过程就是执行组件类中的 run() 方法;
3、算法组件基类中会根据作业输入确定执行的方法列表, 存在训练数据集是会执行 fit() 进行训练,存在测试数据集时会执行 predict() 进行推理;
4、任务执行的输出会被持久化存储,后续任务执行时可以使用前面任务执行的输出作为输入进行执行;