背景信息
最近接手的项目中遇到一个新的需求,需要对原有的机器学习相关的接口进行切换,因为机器学习算法训练包含的参数比较多,结构也比较复杂,参数之前存在复杂的动态依赖关系。更麻烦的问题在于前端 Web 页面是基于接口结构与字段类型进行渲染的,同时为了支持基于接口渲染出前端页面,前人使用的技术方案如下所示:
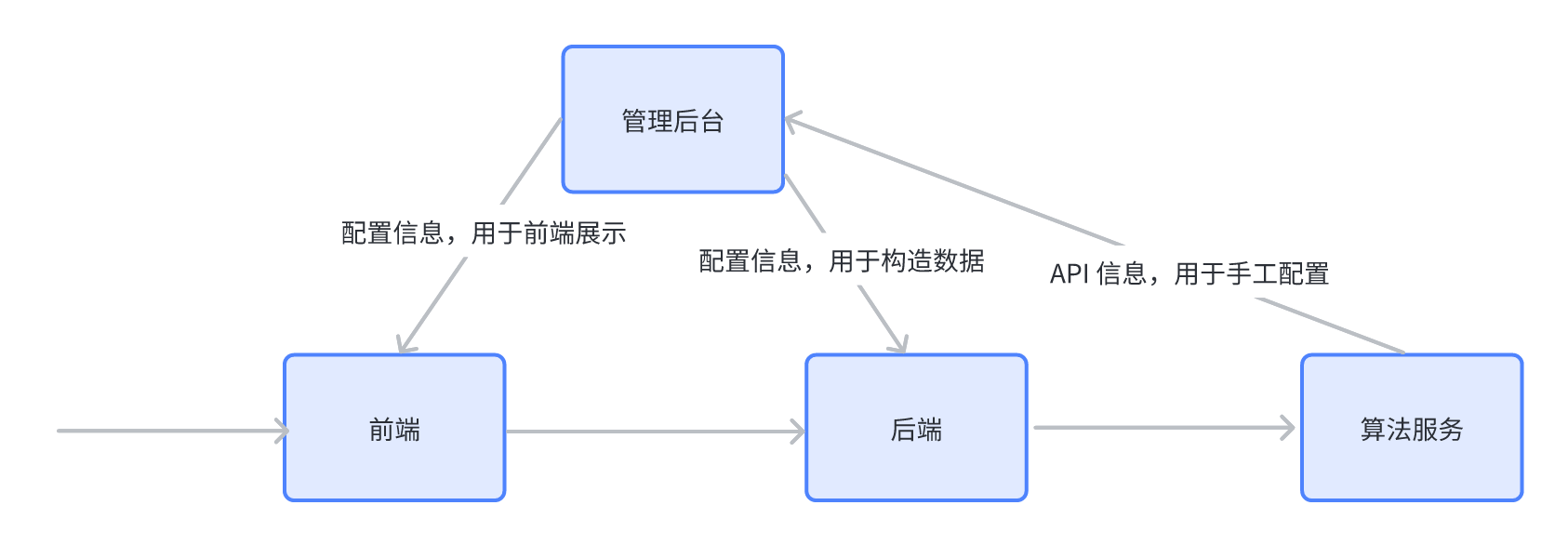
可以看到基于接口需要去管理后台进行参数的配置,管理后台为了前端逻辑的展示的需要,定义了复杂的类型,比如光数组就定义了整数数组,字符串数组,对象数组,可多选数组等 6 种类型,即使如此,前端渲染时因为描述能力的限制,依旧增加了不少特殊情况的处理逻辑。当前访问的问题很明显:
- 接口的变更基本上意味着原有方案的大量改造,因为目前的结构与类型差异很大,意味着原有定义可能无法满足需求,更麻烦的是前端页面的渲染逻辑中的特殊处理,需要大量的改造;
- 本次变更完成之后将来的接口变更依旧需要花费比较多时间,现有方案的可拓展能力很弱;
- 后台配置字段依赖人工,配置错误可能会导致接口请求失败;
- 前后端的逻辑耦合,新字段的支持都需要确认前端能否正确支持;
技术方案探索
根据上面的问题,原有的技术方案基本不可用,需要一种更具拓展性的技术方案。预期需要有一套完备的接口描述方案,然后基于这套完备的接口描述文件进行动态渲染。每次用户访问页面时,实时请求接口描述数据,基于这个接口描述文件进行动态页面渲染。这样后续的接口升级就能平滑过渡了,而且不需要后台配置,避免了人工配置不可靠的问题。预期流程如下所示:
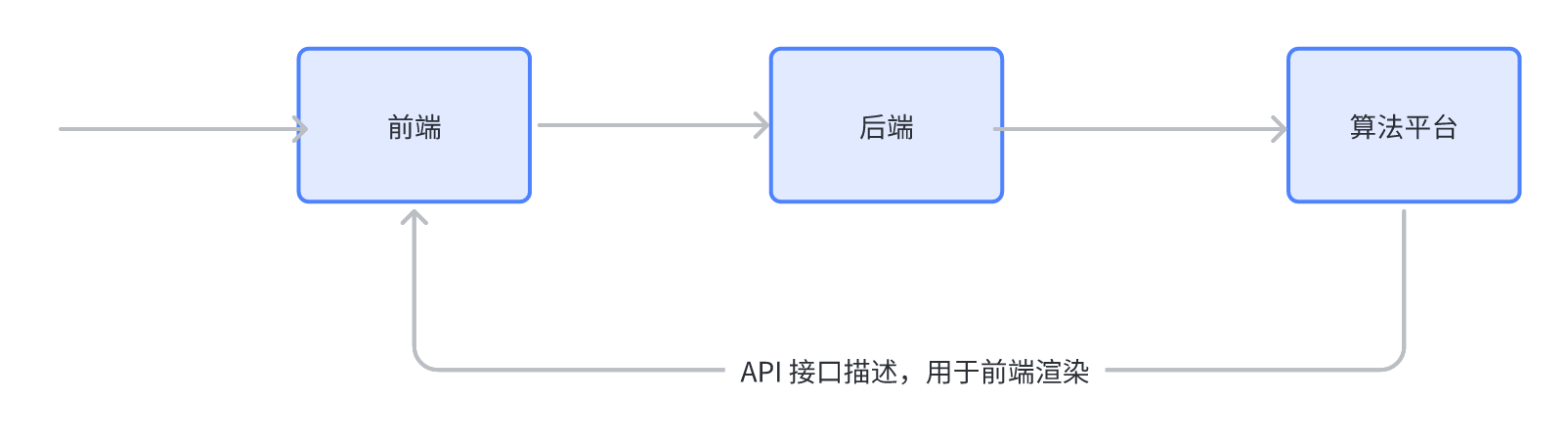
接口描述方案探索
接口描述方案优先选择成熟的标准,简单调研就发现了 OpenAPI 规范,这是一个与编程语言无关的 RESTful 规范,从应用的广泛层度来看应该可以确认是完备的接口描述规范。而且更友好的是,现有的 Python Web 服务 FastAPI 就是基于 OpenAPI 的,预期兼容性好。
但是实际应用时我们期望裁剪接口数据,仅仅获取接口字段描述相关内容,而不是完整的 OpenAPI 的接口描述信息,参考 FastAPI 的实现代码,确认实际的字段描述事实上就是基于 JSON Schema 实现的。JSON Schema 就是通过一套简单的规则可以对现有的字段与结构进行了描述,完美满足需求。JSON Schema 描述是怎样的呢,可以看一个例子:
原始接口数据如下所示:
{
"first_name": "George",
"last_name": "Washington",
"birthday": "1732-02-22",
"address": {
"street_address": "3200 Mount Vernon Memorial Highway",
"city": "Mount Vernon",
"state": "Virginia",
"country": "United States"
}
}
对应的 JSON Schema 描述可能是如下所示的:
{
"type": "object",
"properties": {
"first_name": { "type": "string" },
"last_name": { "type": "string" },
"birthday": { "type": "string", "format": "date" },
"address": {
"type": "object",
"properties": {
"street_address": { "type": "string" },
"city": { "type": "string" },
"state": { "type": "string" },
"country": { "type" : "string" }
}
}
}
}
通过下面的描述我们可以知道其中的字段类型以及结构关系,基于对应的 JSON Schema 即可完备解释接口信息。
后端生成探索
由于之前使用的是 FastAPI,因此项目中大量使用 Pydantic 进行类型定义,基于 Pydantic 对象可以通过 model_json_schema() 方法直接生成 schema 数据,将此数据直接返回给前端即可。
但是考虑到原有的 Pydantic 对象基本都缺乏具体的描述信息,比如字段的解释以及限制信息,只需要通过 Field 进行补充即可,开发工作量较小。
渲染方案探索
基于现有的标准 Schema 数据,可以实现通用的渲染能力,后续所有的变更就不需要进行额外的开发了,而且前端可以根据实际需要定义具体的渲染方案,只要符合 JSON Schema 规范即可,前后端顺利解耦。
但是实现一套完整的 JSON Schema 的解析与渲染依旧需要花费不少时间,不过考虑到 JSON Schema 已经是相对成熟的标准,因此调研是否存在相对成熟的解决方案,简单调研就发现,前端存在 JSON Schema Form 的做法。对于复杂的 Form 页面,根据后端提供的 JSON Schema 数据,自动渲染出页面,正是我们所需要的。JSON Schema Form 的开源方案有不少,整理在下面:
- https://github.com/lljj-x/vue-json-schema-form 1.7K star,项目在持续迭代中,支持 Vue2
- https://github.com/xaboy/form-create/tree/next 4.9K star,项目在持续迭代中,支持 Vue
- https://github.com/alibaba/formily 9.8k star,阿里开源,项目持续迭代中,支持 Vue,React
- https://github.com/wearebraid/vue-formulate 2.2K star,项目更新频率不高,支持 Vue
- https://github.com/vue-generators/vue-form-generator 2.9K star,项目看起来没有再更新了
- https://github.com/baidu/amis 14.2K star,百度开源,项目持续迭代中,支持 React,可以通过 SDK 支持 Vue
- https://github.com/rjsf-team/react-jsonschema-form 12.8K star,项目在持续迭代中,支持 React,可以使用 https://rjsf-team.github.io/react-jsonschema-form/ 进行在线 JSON Schema 渲染测试
- https://github.com/alibaba/x-render 6.2K star,阿里开源,项目持续迭代中,支持 React
- https://github.com/JakHuang/form-generator 8.1K star,项目没有再更新了
- https://github.com/koumoul-dev/vuetify-jsonschema-form 502 star,项目没有再更新了
最终因为实际项目目前使用 Vue2 开发的,选择了 https://github.com/lljj-x/vue-json-schema-form ,其中包含了在线渲染预览的支持,可以比较方便地确认展示效果。当前方案的另一个优势在于,渲染与后端解耦后,后续可以根据需要选择任意的渲染库。
技术方案
根据之前的探索,确定了最终的技术方案:
- 接口的描述使用 JSON Schema,基于标准协议描述接口字段信息;
- 后端基于 Pydantic 对象的 model_json_schema() 直接生成 Schema 数据;
- 前端基于 JSON Schema Form 进行渲染,实际选择 https://github.com/lljj-x/vue-json-schema-form,并基于其提供的实时在线渲染调整渲染效果;
实践中的问题
虽然方案看起来没啥问题,但是由于我们的单个接口需要支持所有的机器学习算法,而不同机器学习的算法的参数存在很大差异,而这些算法参数又不可妥协地需要用户输入,因此实践中还是遇到了不少问题的,记录在这边:
动态结构支持
因为需要支持不同的机器学习算法,而不同机器学习算法的超参存在着很大差异,比如线性回归算法与 MLP 算法的超参就存在着极大差异,如何对根据算法名匹配到正确的超参结构呢。
在没有很好的解法的情况下最初的方案是使用并集,然后再补充额外的业务校验,这样虽然可以勉强支持动态校验,但是前端直接渲染就存在明显问题,不能算法超参的正确性,不必要的超参元素的渲染会导致用户体验很差。
调研后发现 Pydantic 提供了 Discriminated Unions 解决方案,可以基于特定 key 渲染支持不同的结构。一个简单的例子如下所示:
class Cat(BaseModel):
pet_type: Literal['cat']
meows: int
class Dog(BaseModel):
pet_type: Literal['dog']
barks: float
class Lizard(BaseModel):
pet_type: Literal['reptile', 'lizard']
scales: bool
class Model(BaseModel):
pet: Union[Cat, Dog, Lizard] = Field(..., discriminator='pet_type')
n: int
类似上面的例子中,定义了三种不同的结构 Cat, Dog, Lizard, 实际传入时就可以通过传入不同的 pet_type 参数校验不同的结构了。
同时 Pydantic 还支持 Annotated 包装 Union 语法,方便添加 Field 类型,更好地支持实际中需要的描述信息,使用类似如下所示:
Pet = Annotated[Union[Cat, Dog, Lizard], Field(discriminator='pet_type')]
当复杂结构放在 Pydantic Model 中效果可能不明显,但是在业务流程中需要直接使用这个类型时就会感受到这个包装的便利性了。
特殊类型的支持问题
项目中最初使用的 Pydantic 版本为 v1.10,对于常规的数据类型的支持还是正常的,但是某些特殊语法的支持就存在一些问题了,比如 Mlp 算法超参需要支持动态新增神经网络层,具体的参数定义如下所示:
class LayersConf(pydantic.BaseModel):
neurons: int = pydantic.Field(title="神经元个数", ge=1)
activation: ActivationNameEnum = pydantic.Field(default=ActivationNameEnum.relu,
title="激活函数",
description="该层所用激活函数类型")
class MlpHyperparamsConf(pydantic.BaseModel):
layers: List[LayersConf] = pydantic.Field(title="神经网络层")
num_classes: int = pydantic.Field(title="类别数", ge=2)
这种情况下基于这个语法是可以支持渲染出如下所示内容:
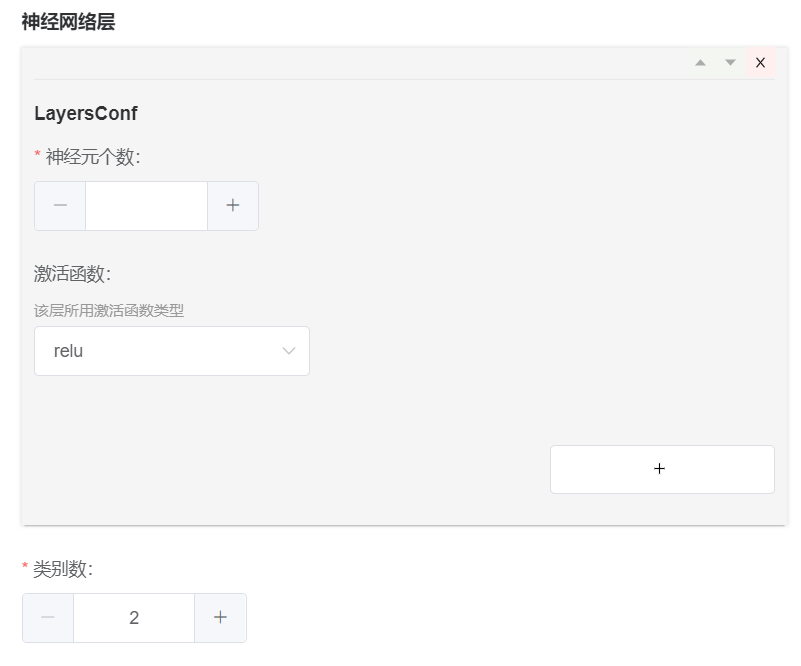
可以看到神经网络层的外层参数时包含中文描述的,但是对于每一层 LayersConf 没办法增加描述信息,基于 Annotated 进行封装后如下所示:
class LayersConf(pydantic.BaseModel):
neurons: int = pydantic.Field(title="神经元个数", ge=1)
activation: ActivationNameEnum = pydantic.Field(default=ActivationNameEnum.relu,
title="激活函数",
description="该层所用激活函数类型")
WrapperLayersConf = Annotated[LayersConf, pydantic.Field(title="层定义")]
class MlpHyperparamsConf(pydantic.BaseModel):
layers: List[WrapperLayersConf] = pydantic.Field(title="神经网络层")
num_classes: int = pydantic.Field(title="类别数", ge=2)
但是实际渲染出的内容也依旧没有相关的描述信息,从输出的 Schema 来看相关的描述信息确实缺失了,确认 Pydantic 实现上存在问题,先尝试进行 Pydantic 版本的升级,升级值 Pydantic v2.1 之后,问题确实得到了解决:
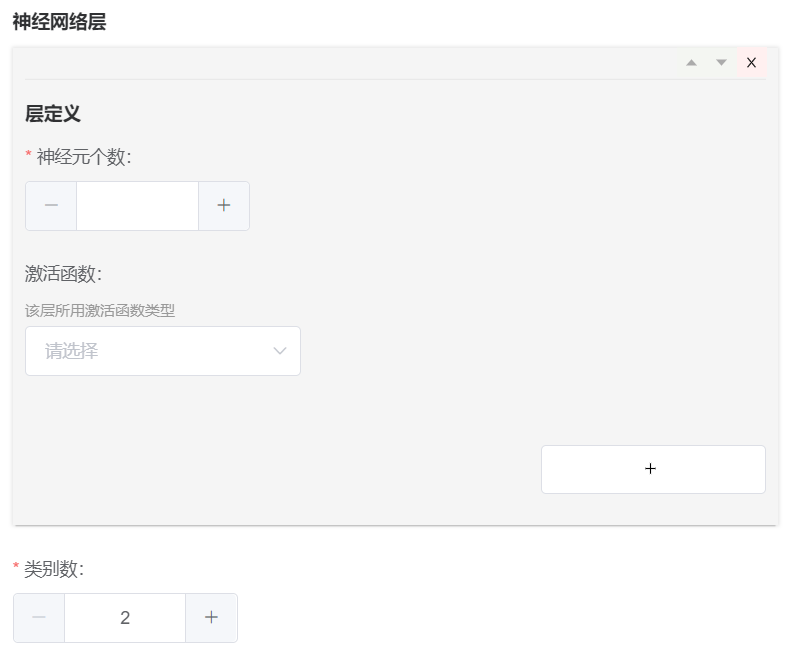
但是实际又碰到了 Pydantic v2 版本不向前兼容,导致项目中出现大量的报错,参考官方 迁移方案 进行了必要迁移后,再手工修复部分异常,看起来就可用了。
另外提醒下,Pydantic v2 版本开始支持 model_config 用法了,上面基于 Annotated 补充 Field 可以直接写入 model_config 里面了,感兴趣的可以去使用下。
前端 OneOf 渲染问题
迁移至 Pydantic v2 后,原有的 Union 会被转换为 JSON Schema 中对应的 OneOf 语法,但是目前的前端渲染库去渲染时就会出现问题,对于这种语法,最终渲染出来的效果如下所示:
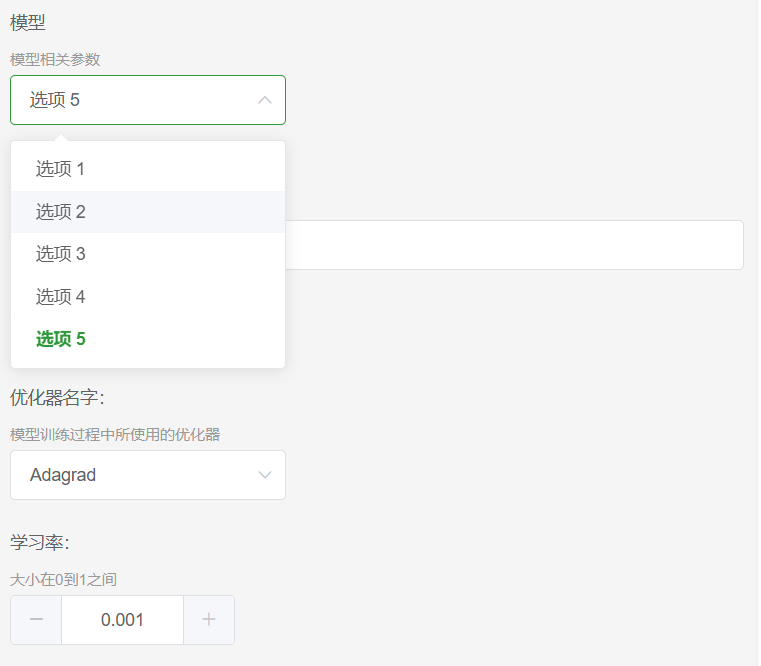
此时用户体验会很糟糕,确认了一下转换的 JSON Schema 语法,看起来没啥问题,Pydantic 转换是符合预期的,但是渲染库不能很好地支持,而且调研不同的渲染库效果均不佳。
从技术角度没有很好的解决方案了,和产品协调具体的妥协逻辑,确认产品端是先选中具体的机器学习算法再渲染机器学习训练参数的,因此可以在请求算法对应的 Schema 时传递对应的的机器学习算法名称,后端直接返回对应的无 Oneof 的 Schema 数据,从而保证渲染的正确性。而发起机器学习训练时的校验中使用统一的 Schema。在必要的妥协调整后避免这个体验问题,前端渲染的库的支持完善了再切换回去。
总结
解决了前后端的一些问题后,最终得到了一套通用的机器学习训练接口与页面渲染方案,后端的参数更新会直接影响前端的页面渲染,而且不再需要任何手工配置,因为建立在标准协议与开源工具的基础上,前后端被真正解耦开,而且开发的工作量大大降低,整体的开发周期从预期的 4 周下降至 1 周左右。从这个实际方案设计与落地的过程个人的一些感受:
- 尽可能抽象化需求,避免解决单一具体问题;
- 尽可能选择标准化协议,而不是定义自己的标准,完备性和可拓展性都无法保证;
- 在标准协议下,尽可能寻找已有的开源实现,建立在巨人的肩膀上效率会高很多;