背景信息
最终参与一个涉及比较大量 gRPC 服务调用的项目,内部调用链路比较复杂,追踪 bug 涉及的信息链路也很长,导致追踪问题比较困难。今天在跟踪特定问题时,发现部分链路日志缺失,而且执行链路比较难追踪,于是想到之前 Web 服务中为了方便异常追踪,会统一注册,将所有的请求与返回都打印出来,并通过唯一的 id 去串联完整处理链路,通过这种方式执行链路会变得特别清晰,调试问题也变得很方便,因此简单探索 gRPC 是否能支持同样的能力
探索过程
gRPC 原生实现
简单了解之后就发现了 gRPC 支持了 interceptor 机制,基本的请求处理流程如下:
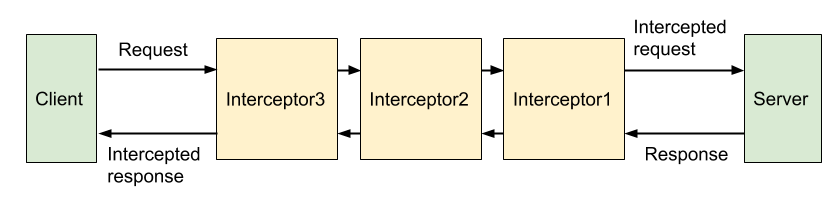
可以看到的 gRPC 的请求与响应都会经过 interceptor,在启动 grpc server 时注册 interceptor 列表,请求会依次经过列表中的 interceptor,最后处理结束时会再反向经过 interceptor 列表,直到最终产生结果返回给客户端
采用 grpc interceptor 可以进行简单实现如下:
class LoggerInterceptor(grpc.ServerInterceptor):
def intercept_service(self,continuation, handler_call_details):
logger.info(f"Request {handler_call_details}")
resp = continuation(handler_call_details)
logger.info("Response with {resp}")
return resp
实际注册机制也十分简单,在 grpc server 启动时配置上即可:
def serve():
server = grpc.server(futures.ThreadPoolExecutor(max_workers=5),
interceptors=[LoggerInterceptor()])
server.add_insecure_port('[::]:50051')
server.start()
实际可以工作,但是效果不佳,主要存在下面的原因:
- 请求参数 handler_call_details 中主要包含请求方法名,但是没有具体请求的参数信息,后续不方便还原完整现场;
- 返回值 resp 也不是预期原始返回值;
- gRPC 中有多种请求类型,Unary,Stream,需要实现不同类型的 interceptor;
感觉有点繁琐了
第三方实现
对于繁琐的问题,大部分都会有人提供更好的解决方案,简单搜索就找到了第三方的方案 grpc_interceptor
grpc_interceptor 对原有的 interceptor 进行了二次封装,提供了一个简单好用的 ServerInterceptor ,其中包含了请求参数,返回值也比较符合预期,上面的 LoggerInterceptor 可以简单实现如下:
from grpc_interceptor import ServerInterceptor
from grpc_interceptor.exceptions import GrpcException
class LoggerInterceptor(ServerInterceptor):
def intercept(
self,
method: Callable,
request: Any,
context: grpc.ServicerContext,
method_name: str,
) -> Any:
logger.info(f"Request with {request}")
resp = method(request, context)
logger.info(f"Response with {resp}")
return resp
即可实现一个简单的日志请求和响应打印的能力
一些优化
为了线上业务使用更加方便,对上面的处理进行必要的优化,从跟踪请求流程的角度主要需要实现下面的能力:
- 请求和响应的日志中间可能会被插入大量的日志,为了方便进行关联,可以增加一个唯一 id 建立关联;
- 可以将请求方法名带上,方便快速确认请求信息;
- 可以增加必要的请求处理时间,方便定位一些耗时过长的问题;
- 异常请求下需要增加必要的预警机制;
按照上面的情况进行了必要优化后,最终代码如下所示:
class LoggerInterceptor(ServerInterceptor):
@classmethod
def get_simple_method_name(cls, original_method_name: str) -> str:
return original_method_name.split("/")[-1]
def intercept(
self,
method: Callable,
request: Any,
context: grpc.ServicerContext,
method_name: str,
) -> Any:
simple_method_name = self.get_simple_method_name(method_name)
try:
start = datetime.now()
current_call_id = start.strftime("%Y%m%d%H%M%S%f")
logger.info(f"[{simple_method_name}][{current_call_id}] Call with {request}")
ret = method(request, context)
end = datetime.now()
gap = end - start
logger.info(
f"[{simple_method_name}][{current_call_id}] Response cost {gap.seconds}.{gap.microseconds}s, details: {ret}"
)
return ret
except GrpcException as e:
logger.exception(f"[{simple_method_name}][{current_call_id}] handle got exception: {e}")
raise
上面提供的方法中使用简单的时间作为 id 串联了请求和相应日志,并增加了处理时间记录,并在异常情况下使用 logger.exception 输出异常信息,再额外配合 Sentry 即可实现异常上报预警。另外针对原始的 method_name 过长的问题,使用 get_simple_method_name() 进行了缩短,避免整体日志过长
总结
整体的实现并不复杂,但是对于 gRPC 的调试效率提升还是蛮多的,后续追踪问题更加方便了。调试 bug 是一个比较费心费力的过程,尽可能通过通用的机制方便自己,才能节省出更多摸鱼的时间呀