基础背景
目前在使用前端框架的程序员们,或多或少都会知道框架背后的虚拟 DOM与 diff 算法,但是并不一定深入了解过为什么虚拟 DOM 要存在,以及不同前端框架如何进行更高效地渲染,这篇文章尝试去梳理一下这个完整流程
虚拟 DOM 介绍
有一些前端知识的都知道,对于 Web 页面而言,客户端最终可以展示的内容都是 html 页面,因此不管技术如何发展,最终都需要转化为 html 页面,才能被浏览器正确展示与处理。而 html 的组件部分是 DOM 节点,页面的 DOM 节点会被组合形成 DOM 树。
目前的前端框架中,我们会开发各种各样的组件,组件最终会被渲染会一个或多个 DOM 节点供用户展示。但是在前端框架中,都不约而同地采用了同一个思路,前端框架会将组件先转换为虚拟 DOM 节点,即 Virtual DOM,之后再将虚拟 DOM 节点渲染成实际的 DOM 节点,Virtual DOM 也会被组织成树形结构,即 Virtual DOM 树。
虚拟 DOM 节点目前是一个规范化的数据结构,类似如下所示:
{
tag: 'div',
data: {
style: {
backgroundColor: 'blue'
},
},
children: {
tag: null,
data: null,
children: '文本内容'
}
}
使用这个数据结构,最终可以转化为 DOM 节点,等价于如下所示 DOM 元素:
<div style="background-color: blue">
文本内容
</div>
Why
为什么我们要引入虚拟 DOM,而不是直接将组件转换为 DOM 节点呢?在我看来有下面一些原因:
- 增加灵活性,在技术领域一向有增加中间层的思路,利用中间层可以提供更多的灵活性。把原先的过程拆分为标准化和渲染两步之后,标准化的虚拟 DOM 数据根据需要进行渲染就可以适应更多平台了。借助虚拟 DOM 就可以渲染至非 Web 平台,甚至是最近前端的 SSR 也是利用了虚拟 DOM 可以根据需要渲染的特点实现的;
- 效率更高,利用标准化的数据可以实现按需更新,支持更高效的更新渲染,这部分后续会进一步介绍;
渲染过程
对于基于目前的前端框架的页面渲染分成两种情况:
-
首次渲染
首次渲染是指在用户请求页面时首次渲染出所需的页面,首次渲染中会将组件转换为 Virtual DOM 树,然后将 Virtual DOM 渲染成 DOM 树,呈现在用户面前。由于增加了一次转换,而且没有额外的优化,效率上和直接渲染为 DOM 树没有明显的提升;
-
后续渲染
后续渲染是指后续随着和用户交互,数据变化导致需要更新展示,此时利用新的组件数据转化为新的 Virtual DOM 树后,通过比较新旧 Virtual DOM 树,可以根据不同之处选择更新哪些 DOM 节点,尽可能地复用原有 DOM 节点,相对全部重新渲染会有明显的效率提升;
根据前面的介绍,框架主要关心的提升效率的地方主要是后续渲染,导致前端框架性能差异的点也就主要是:
- 能否更高效地比对新旧 Virtual DOM 树,找出不同之处;
- 能否使用最少的操作将旧的 Virtual DOM 树转换为新的 Virtual DOM 树,这样可以保证更新 DOM 树的操作尽量少,效率尽可能地高;
Tree diff
根据前面的介绍,我们知道,前端框架渲染的效率关键在于 Virtual DOM 树的比较与更新问题,这边主要介绍下各种解决思路
传统算法
对于树形结构的更新,已经有一些比较传统的算法可以实现了,可以参考下 论文
时间复杂度为 O(n^3) ,明显复杂度太高,无法被接受
React 算法
针对传统算法进行树形结构的更新算法时间复杂度过高的问题,React 给出的解决方案是根据前端的实际情况去简化问题:
-
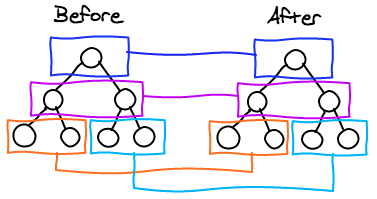
分层比较 ,仅仅比较同一层的节点,不会跨层去比较节点,这样节点需要比较的节点数就大大降低,而由于跨层移动本身出现的比较少,减少跨层复用带来的性能开销也比较少,类似图示如下所示:
-
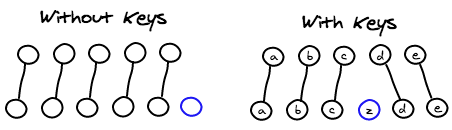
列表 key ,在同一层的比较中,新旧子节点可能是列表对列表的比较,在没有 key 的情况下,React 基本无法判断新旧节点的对应关系,此时会直接按照先后顺序进行复用,如果指定了 key,那么就可以更准确地了解对应新旧节点的对应关系,从而更好地复用节点,类似图示:
-
组件类型比较 ,仅仅比较同类型的组件,如果组件类型不同,直接移除旧组件,增加新组件,这样避免浪费宝贵的资源进行低概率的比较;
通过前面的介绍可以看到,React 通过一系列的简化,原有的树形结构的比较更新问题简化为了列表比较更新的问题,复杂度大大降低,基本接近 O(n)。
通过前面的介绍,我们可以发现,原有的更新渲染的问题最初通过 VIrtual DOM 标准化后转变为树形比较更新的问题,通过抽象后变成列表比较更新的问题,因此渲染更新主要关注的就是如何高效地比较更新列表。很多介绍 Virtual DOM diff 算法的只关注两个列表的比较更新的原因就在于此。下面就来分别讨论下如何提升性能:
-
比对列表的不同之处,此问题的前提是如何确定列表中的节点是否相等,因此 React 要求我们在列表中尽量指定 key,这样才能方便 React 确定新旧节点的对应关系,有了 key 之后如何高效的比较呢?
- 如果列表中数量较少,那么直接按照顺序比较就好;
- 如果列表中数量的较多,那么直接将元素保存至字典中,键为用户指定的 key,那么也可以在 O(n) 的时间内进行高效的比较;
-
尽量少的操作,此问题的前提是确定可以执行的操作,React 定义的操作动作包括:
- INSERT_MARKUP,插入节点,新列表中存在而原有列表不存在时,插入新节点
- MOVE_EXISTING 移动节点,新旧列表中都存在而位置不同时,移动节点
- REMOVE_NODE 移除节点,旧列表中存在而新列表中不存在时,移除节点
看到这个操作可以理解,插入和删除可优化的空间很有限,后续可以优化的点主要在于减少移动操作,后面比较比较算法的差异时会看到各种前端框架在减少移动操作上所做的优化。
具体实现
React 的实现比较简单,遍历新列表,通过使用 lastIndex 记录元素在旧列表出现的最大位置,如果新列表中后续出现的元素在原有列表中的存在的位置小于 lastIndex 则表示需要移动。下面举出一个简单的例子,节点都通过字母代替,如下所示:
原有列表为 [a, b, c] ,更新为 [c, a, b] ,具体的判断过程如下所示:
- 遍历新列表,得到的第一个元素
c,查询旧列表得到在旧列表中的索引为 2,由于初始lastIndex为 0,此时得到索引值大于lastIndex,不需要移动,并更新lastIndex为 2; - 遍历新列表得到第二个元素
a, 查询在旧列表中索引为 0,此时小于lastIndex,需要执行移动; - 遍历新列表得到第三个元素
b,查询旧列表中索引为 1,此时小于lastIndex, 需要执行移动;
即执行两次移动操作,即可将旧列表更新为新列表。
如何判断需要执行插入操作呢?很简单,新列表遍历中如何旧列表没有对应的元素,那么就执行插入操作
如何判断需要执行移除操作呢?在新列表遍历完成后,需要遍历老列表,如果在新列表中没有对应的元素,则执行删除操作
Vue2 算法
Vue2 的虚拟 DOM 算法其实来源于 snabbdom ,背后的原理是完全一致的
Vue2 的算法的基础简化思路都是类似的,包括分层比较,列表 key,组件类型等,这部分就不用再额外介绍了,主要的区别主要在于最终列表比较的 diff 算法部分。
前面介绍 React 算法部分时,根据举出的例子可以明显地感觉到仅仅使用一个 lastIndex 存在的问题,将 [a,b,c] 转化为 [c, a, b] 的一个更高效的方案是移动 c 元素至列表最前面,只需要一次移动即可完成列表的更新
Vue2 引入了双端比较的算法, 通过在新旧列表中分别采用两个指针指向列表头部和尾部,每次执行新旧列表中四次指针比较判断是否存在节点复用,从而避免 React 算法中的低效移动问题,具体的实现算法可以参考 此博客 ,通过双端比较可以解决尾部元素移动至列表头部的低效问题。
Vue3 算法
Vue3 算法相对 Vue2 有了比较大的变化,Vue3 的算法参考自 inferno ,而 inferno 是目前效率最高的算法了,下面可以分别介绍下算法中所做的优化:
-
去除相同前置和后置元素 ,此优化由 Neil Fraser 提出,可以比较容易实现而且带来带来比较明显的提升;
比如原有列表为
[a, b, c, d],而新列表为[a, b, d], 去除相同的前置和后置元素后,真正需要处理的是[c]和[],复杂性会大大降低 -
最长递增子序列
在比较 Vue2 算法相对 React 所做的优化时,提到使用双端比较,从而使移动元素的次数减少,而 inferno 中则对移动次数进行了进一步的优化。下面对这个算法进行介绍:
-
首先遍历新列表,通过 key 去查找在原有列表中的位置,从而得到新列表在原有列表中位置所构成的数组。比如原有数组为
[a, b, c],新数组为[c, a, b],遍历后得到的位置数组为[2, 0, 1],现在的算法就是通过位置数组判断最小化移动次数; -
inferno 给出的方法就是最长递增子序列
最长递增子序列是经典的动态规划算法,不了解的可以前往 最长递增子序列 去补充一下前序知识。那么为什么最长递增子序列就可以保证移动次数最少呢?因为在位置数组中递增就能保证在旧数组中的相对位置的有序性,从而不需要移动,因此递增子序列的最长可以保证移动次数的最少
对于前面的得到的位置数组
[2, 0, 1],得到最长递增子序列[0, 1],满足此子序列的元素不需要移动,没有满足此子序列的元素移动即可。对应与实际的节点即c节点移动至所有节点最前面即可。
-
结论
通过前面的介绍,对虚拟 DOM 存在的原因以及背后的 diff 算法进行了梳理,可以帮助大家从基础上了解前端框架所做的事情以及背后的效率差异,如果想对更多前端库背后的算法进行比较,那么司徒正美 的文章可以给你一些参考
对于各个框架来说,其所做的优化必然也不是仅仅只是最基础的 diff 算法,比如 React 还会对修改合并为一批进行渲染更新,以及用户可以通过 shouldComponentUpdate 指定是否需要进行组件更新,可以参考 Christopher Chedeau 的博客 ,这些优化都是默认启用的。
总体来说,前端框架帮我们封装了高效的数据渲染更新策略,让我们可以在不用做过多的优化即可高效地渲染更新内容,从而让工程师可以仅仅关注于抽象的数据部分与相应的展示样式。因此如果只是业务向的工程师,可以仅仅使用即可,最多阅读下官方文档。但是如果想探究下文档下给出的建议的具体缘由,就需要对底层的细节有更多的了解了。