基础概念
Celery是一个异步任务处理框架,Celery处理的主要图示如下所示:
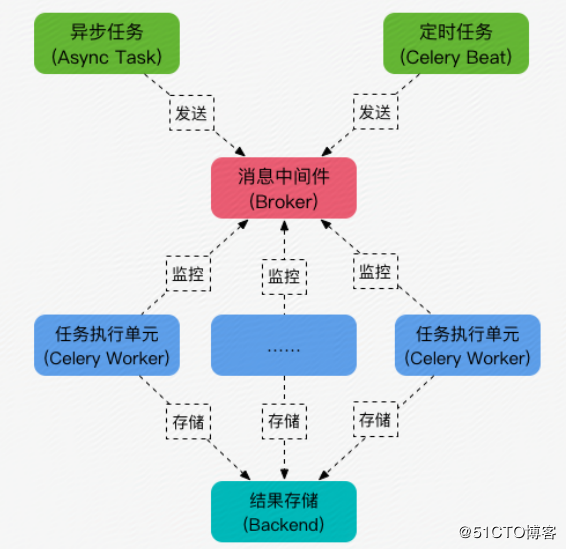
此图示借鉴自51cto
Celery 任务的处理流程为:
- 手工创建异步任务或使用Beat创建定时异步任务;
- 启动的异步任务存储至消息中间件Broker中;
- 任务处理单元Worker持续监控Broker,当发现创建的异步任务时,执行异步任务;
- 异步任务处理的结果存储至Backend中;
上述流程中Broker是必选的,但是Celery没有提供Broker,使用者可以使用RabbitMQ或Redis等作为Broker,而Backend不是必选,如果使用者不关心异步处理的结果,可以不使用Backend。
本文多部分内容都参考官方文档Celery 4.2,英文基础好的同志可以直接阅读官方文档
使用流程
如果希望使用celery进行异步任务的控制,使用的流程如下所示:
- 安装Celery和Broker,之前项目中的选择的是Redis,使用比较稳定;
- 创建Celery应用实例;
- 使用应用实例装饰待运行的方法,创建任务;
- 异步执行任务;
创建应用实例
在使用Celery时,首先就需要创建应用实例,在创建实例时,需要制定Broker地址,代码如下所示:
app = Celery('tasks', broker="redis://redis_address/")
在创建应用实例时,除了Broker地址需要关注以外,还需要关注的是应用实例的名字,名字一般作为创建Celery实例的第一个参数给出,上面的例子中的tasks 就是应用实例的名字。需要关注的原因在于:应用实例创建的任务的任务名称必须保证唯一性,而Celery创建的任务默认情况下如果不能确定任务属于哪个模块时,会使用应用实例的名字作为任务名称的前缀
创建任务
使用创建的Celery实例装饰方法,创建可异步执行的任务。构建的代码如下所示:
@app.task
def add(x, y):
return x + y
启动Worker
Celery需要启动Worker进行异步任务的处理,启动Celery的Worker的命令如下所示:
celery -A proj:celery worker -l info
在上面的命令中使用-A 参数指定了对应的Celery实例
启动异步任务
可以使用delay() 方法或apply_async() 方法启动异步任务,执行的代码如下所示:
add.delay(2, 2)
使用apply_async() 方法执行代码如下所示:
add.apply_async((2, 2))
任务调用
任务命名
每个任务都需要唯一的名字,如果任务名没有显示指定,那么Celery会自动为你创建任务名,Celery的命名基于任务的模块名与任务的方法名。
如果使用相对引用,可能会导致同一个任务有不同的任务名,导致无法正确查找到任务。因此如果采用相对引用,就不要使用Celery自动命名机制。
任务绑定
在创建任务时,如果需要访问任务本身的信息,可以使用@task(bind=True) 进行调用,这样可以绑定任务实例,而调用方法第一个参数总是self ,可以通过此参数访问任务实例信息。
而任务实例的request属性包含当前执行任务相关的任务和信息。其中部分属性信息如下所示:
id当前执行任务的唯一idargs位置参数kwargs关键字参数retries当前任务重试次数eta任务的原始预期到达时间expires任务的原始到期时间callbacks任务成功执行后的方法签名列表errback任务执行失败后的方法签名列表
使用的代码如下所示:
@app.task(bind=True)
def dump_context(self, x, y):
print('Executing task id {0.id}, args: {0.args!r} kwargs: {0.kwargs!r}'.format(
self.request))
日志信息
执行单元会为你自动设置logging,你也可以手工指定logging
celery提供了一个特殊的logger叫做celery.task ,这个logger可以帮你在日志中加入任务名和任务id作为日志的一部分
官方建议在顶层模块创建一个通用logger,供所有任务使用,你可以调用get_task_logger() 方法获取logger,与继承celery.task 类似,可以在日志中加入任务名与任务id,使用代码如下所示:
from celery.utils.log import get_task_logger
logger = get_task_logger(__name__)
@app.task
def add(x, y):
logger.info('Adding {0} + {1}'.format(x, y))
return x + y
任务配置
任务装饰器会接受一系列参数用于改变任务行为,下面是一些常用的配置参数:
Task.name任务名Task.max_retries最大重试次数Task.throws将一些预期内的异常不视作错误Task.default_retry_delay任务默认的重试延迟Task.backend本次任务结果存储位置,默认会使用celery指定的统一的结果存储位置
任务重试
在任务执行失败时,可以执行任务的retry() 方法进行重试,当执行任务的重试时,新的任务id与重试的任务id相同。而且Celery会保证新的任务会执行在相同的任务队列中。手动重试的代码例子如下所示:
@app.task(bind=True)
def send_twitter_status(self, oauth, tweet):
try:
twitter = Twitter(oauth)
twitter.update_status(tweet)
except (Twitter.FailWhaleError, Twitter.LoginError) as exc:
raise self.retry(exc=exc)
除了手工进行重试以外,Celery还可以在任务装饰器中使用参数autoretry_for指定在特定的错误下自动执行重试,示例如下所示:
@app.task(autoretry_for=(FailWhaleError,))
def refresh_timeline(user):
return twitter.refresh_timeline(user)
任务调用
可以采用三种方式调用任务:
apply_async(args[, kwargs[, …]])发送异步任务消息启动异步任务,后续由Worker异步执行任务delay(*args, **kwargs)是apply_async方式的简写,但是不支持执行参数calling (__call__)直接调用方法,任务在当前线程执行,不会由Worker处理
一般情况下,如果只是简单执行异步任务,不需要指定参数,可以直接使用delay() 创建异步任务,如果需要使用执行参数,那么会选择apply_async() 方法创建异步任务
实用的执行参数包括如下所示:
link使用此参数指定成功执行后的回调link_error使用此参数执行执行失败后的回调eta使用此参数指定任务最早执行时间,使用datetime类型countdown类似eta参数,指定多少秒后执行任务
工作流程设计
任务签名(Signatures)
一般情况下,我们会使用delay() 或 apply_async() 启动任务,但是某些情况下我们可能会需要将任务传递给另一个进程,或者是作为参数传递给另一个方法。此时我们可以使用任务签名(Signature)
任务签名包装了任务调用的参数,关键字参数和执行参数,签名可以传递给方法,甚至可以序列化之后在网络上传输。
创建任务签名可以Celery提供的signature() 方法,或者调用任务本身的signature() 方法,使用Celery提供的signature() 方法代码如下所示:
from celery import signature
signature('tasks.add', args=(2, 2), countdown=10)
而使用任务本身的signature() 方法代码如下所示:
add.signature((2, 2), countdown=10)
这种方法还有一种简写方法s() ,代码如下所示:
add.s(2, 2).set(countdown=10)
任务签名也类似任务运行的方法delay() 和 apply_async() ,一般情况下,可以将任务签名类似任务一样运行。
在使用回调函数时,为了将回调函数作为参数传递给apply_async() 方法,就会使用任务签名,代码如下所示:
add.apply_async((2, 2), link=add.s(8))
####基元(Primitive)
为了实现复杂的工作流程,Celery提供了一系列基元作为基础进行组合,创建复杂的工作流程。而这些基元本身依赖的基础就是任务签名,这些基元如下所示:
- 组(group),组基元是由并行执行的任务列表组合而成的任务签名
- 链(link),链基元允许我们将签名链接在一起,从而在一个签名执行完后启动另一个签名,本质上形成任务链
- 弦(chord),弦类似于组,类似于一个有回调的组,在并行的任务列表全部执行结束之后会执行回调函数
- 映射(map),map基元就像类似的map方法一样,创建一个临时任务,将一系列参数应用到任务中。比如
task.map([1, 2]),按顺序将参数传递到任务中,结果就是[task(1), task(2)] - starmap, 类似于map,只是参数是类似
*args一样应用的,比如add.starmap([(2, 2), (4, 4)])的结果是[add(2, 2), add(4, 4)] - 块(chunk), 将长的参数列表分解为块,从而分块执行
下面分别对这些基元进行解释:
链
一般情况下,将任务链接在一起,我们会在异步执行的apply_async() 方法中加入link 参数,用于在任务执行成功之后执行回调方法,也会使用link_error 参数用于在执行失败后执行回调
同时也可以使用链来将任务串联起来。链的用法可以使用chain() 方法或者| 操作符,比如:
chain(add.s(4, 4), mul.s(8), mul.s(10)).apply_async()
使用| 操作符类似如下所示:
(add.s(2, 2) | mul.s(8) | mul.s(10)).apply_async()
组
组用于在并行执行一系列任务,组方法接受多个签名作为参数,使用方式类似如下所示:
roup(add.s(2, 2), add.s(4, 4)).apply_async()
组也支持迭代器作为参数,类似如下所示:
group(add.s(i, i) for i in xrange(100))()
弦
弦用于执行一系列任务之后执行回调方法,使用的方式类似如下所示:
chord(add.s(i, i) for i in xrange(100))(tsum.s())
在上面的代码中执行了100次add() 任务,最后将前面执行的结果作为参数传递给tsum() 方法进行处理
map和Starmap
map和starmap是用于对序列中的所有元素调用任务,与组有明显区别在于:
- 这种类型只发出一个任务消息
- 执行操作是连续的
块
分块可以将迭代的工作片段化,如果你有100万个对象需要处理,可以创建10个任务,每个任务处理10万个对象。使用chunks() 用于创建分块签名,代码类似如下所示:
add.chunks(zip(range(100), range(100)), 10)
Worker
Worker主要用于实际执行异步任务,使用者创建了异步任务之后会存储至Broker中,而Worker会持续监控Broker,如果检测到时间准备就绪的异步任务,就会执行此异步任务,并将执行结果存储至Backend中。一般情况下,相关的操作如下所示:
启动worker
直接使用celery worker命令启动Worker,命令如下所示:
celery -A proj:celery worker -l info
停止worker
停止worker应该使用TERM 信号,这样worker会在停止前完成当前的工作。如果在预期时间内,任务没有成功停止,一般是卡在无限循环或类似的问题上,此时可以发送KILL 信号停止worker,这种方式可能会导致任务丢失
重启worker
重启worker应该先发送TERM 停止worker,然后启动新的worker实例
任务撤销
在运行过程中,如果需要撤销特定的任务,可以使用Celery中的revoke() 方法,如果worker收到revoke请求,那么worker会跳过这个任务,但是在没有设置termimate 选项的情况下,worker不会终止已经开始执行的任务。revoke() 方法的用法如下所示:
app.control.revoke('task_id')
周期性任务
Celery beat是一个调度器,它会周期性地创建任务,然后由合适的Worker进行执行
在beat中,每个周期性的任务称为Entry(周期性任务条目),任务的Entry一般是由使用者在beat_schedule 中进行配置,同样,用户也可以通过add_periodic_task() 方法动态增加任务Entry。比如每隔30秒长执行add任务,那么配置应该是如下所示:
app.conf.beat_schedule = {
'add-every-30-seconds': {
'task': 'tasks.add',
'schedule': 30.0,
'args': (16, 16)
},
}
在配置任务Entry时,可以配置的字段如下所示:
task任务名schedule任务执行频率,可以使用整数,timedelta或者是crontabargs位置参数kwargs关键字参数options执行选项
总结
Celery是python下一个比较完善的异步任务调度框架,使用起来比较简单,同时也有很好的灵活性,难得的是还提供比较强大的工作流程设计,是一个适合用于生产环境的异步处理框架。