基于属性的测试
基于属性的测试一种适用于单元测试的测试方法,使用方式与传统的测试方法不太相同,传统的测试方法使用流程如下所示:
- 创建测试用例,指定输入;
- 指定预期的输出;
- 运行代码,判断输出是否符合预期;
基于属性的测试方法使用流程如下所示:
- 描述输入数据;
- 描述输出属性;
- 自动生成大量测试用例,判断输出属性是否违背;
流程看起来类似,但是区别还是比较明显的,传统测试方法每次都只能指定一个测试用例,而基于属性的测试方法是通过描述指定一组测试用例,测试覆盖的情况会大大增加,发现bug的可能性也会大大增加。
而本文介绍的hypothesis就是基于属性的测试方法在python中实现的一个库,可以帮助python programmer更好地测试代码,按照官方的说法:Test faster, fix more,即测试更快,修复更多
基本用法
在实际使用中,只需要描述好数据,然后指定所有数据下应该满足的属性即可,数据的描述可以使用hypothesis提供的基础策略(strategy),hypothesis提供了基本上所有的基础类型的策略,而描述属性,可以使用assert指定,如果assert不满足,则表示代码中存在潜在的bug
基本用例
from hypothesis import given
from hypothesis.strategies import integers
def add(a, b):
b = min(b, 5)
return a + b
@given(integers(), integers())
def test_commutative(a, b):
assert add(a, b) == add(b, a)
在上面的代码中,我们提供了一个基础的测试用例,测试了一个简单的加法函数,但是此加法函数会在b>5时不满足设定的,测试hypothesis是否能帮助找到这个用例,最终结果如下所示:
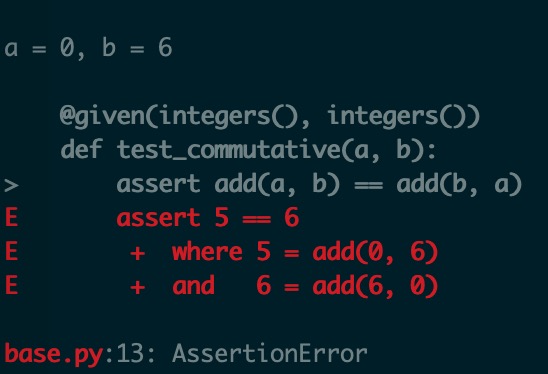 可以看到hypothesis帮我们找到一组会导致失败的测试用例(a=0, b=6)
可以看到hypothesis帮我们找到一组会导致失败的测试用例(a=0, b=6)
更复杂的用例
上面的代码比较简单,可能无法体现hypothesis测试的效果,下面是一个更有意思的测试场景,我们被给出一个整数数组,希望找到两两相乘可以得到的最大值,有人给出的实现代码如下所示:
def max_product(l):
if len(l) < 2:
raise TabError
b1, b2 = sorted(l, reverse=True)[0:2]
return b1*b2
实现的思路就是找到数组中最大的两个数,相乘就是我们需要的最大值,那么是否正确呢?常规情况下,我们会给出几组测试用例,类似如下所示:
def test1():
assert max_product([1, 2, 5]) == 10
def test2():
assert max_product([5, 1, 2, 3]) == 15
def test3():
assert max_product([5, 1, 2, 6, 3, 1]) == 30
def test4():
with pytest.raises(TabError):
max_product([1])
虽然写的复杂一些,但是覆盖很全面,测试结果看起来一切正常,我们似乎就可以上线了。但是这时候,如果我们使用hypothesis来测试一下呢:
from hypothesis import given
from hypothesis.strategies import integers, lists
@given(lists(integers(), min_size=2))
def test_fuzz(li):
assert max_product(li) >= li[0] * li[1]
很简单就实现了一组测试用例,我们指定了一个整数的数组,判断运行的结果是否比数组中的前两个整数相乘的结果大,运行之后可以看到:
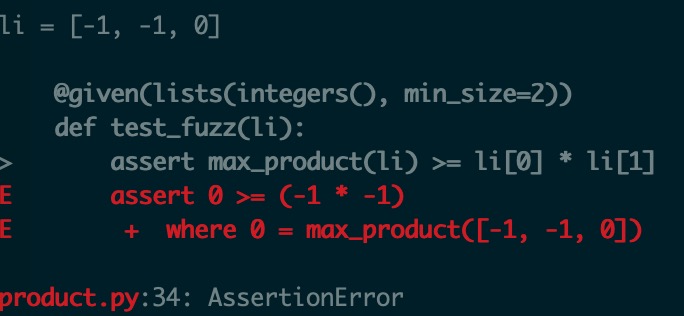 通过上面的运行结果看到,在测试用例为[-1, -1, 0]时会出错,原因是之前的算法遗漏了负数的情况。通过这个例子就可以看到,使用hypothesis可以帮助我们发现一些隐藏得比较深的bug
通过上面的运行结果看到,在测试用例为[-1, -1, 0]时会出错,原因是之前的算法遗漏了负数的情况。通过这个例子就可以看到,使用hypothesis可以帮助我们发现一些隐藏得比较深的bug
带状态的测试
除了前面介绍的普通的测试方式,hypothesis还提供一个带状态的测试,前面测试用例改变数据的状态后,后续的测试用例执行时,是建立在前面测试用例的状态的基础上执行的。这在某些场景的测试中,是非常实用的,比如实现了一个数据结构中的栈stack类,那么如何测试stack类呢?我们会按照某种方式调用stack类提供的接口,此时后续接口的执行必须建立在前面的基础上。如果不使用hypothesis,我们会按照特定的顺序调用stack类提供的一系列接口,我们手工计算好借口的返回值,从而进行验证。但是有些bug可能按照我们定义的顺序就不会出现。这种场景下,如果使用hypothesis提供的带状态测试就很方便了。
这边简单了实现了一个set的功能类BadSet,内部采用数组存储数据,提供add()接口用于添加数据,remove()接口用于删除数据,contains()接口时用于判断数据是否存在,实现代码如下:
class BadSet(object):
def __init__(self):
self.data = []
def add(self, arg):
self.data.append(arg)
def remove(self, arg):
for i in xrange(0, len(self.data)):
if self.data[i] == arg:
del self.data[i]
break
def contains(self, arg):
return arg in self.data
使用hypothesis提供的测试状态机进行带状态测试实现如下:
from hypothesis.stateful import RuleBasedStateMachine, rule
from hypothesis.strategies import integers
class BadSetTest(RuleBasedStateMachine):
def __init__(self):
super(BadSetTest, self).__init__()
self.target = BadSet()
@rule(value=integers())
def add(self, value):
self.target.add(value)
assert self.target.contains(value)
@rule(value=integers())
def remove(self, value):
self.target.remove(value)
assert not self.target.contains(value)
TestBadSetComp = BadSetTest.TestCase
hypothesis使用@rule()定义了一系列测试用例,用法类似于上面看到的@given()装饰器,但是区别在于这些测试用例是有状态的,后续测试时,这些@rule()定义的测试用例作为一个整体执行,而hypothesis会以随机的顺序执行这些测试用例。这样就可以避免自己写测试用例时执行顺序单一的问题。
上面的指定了两个测试用例,一个测试用例add用于执行BadSet类的add()方法,用于加入一个值,并在加入后判断是否加入值是否在BadSet中,另一个测试用例remove用于移除一个值,判断移除后值是否还在BadSet中。hypothesis测试后执行结果如下:
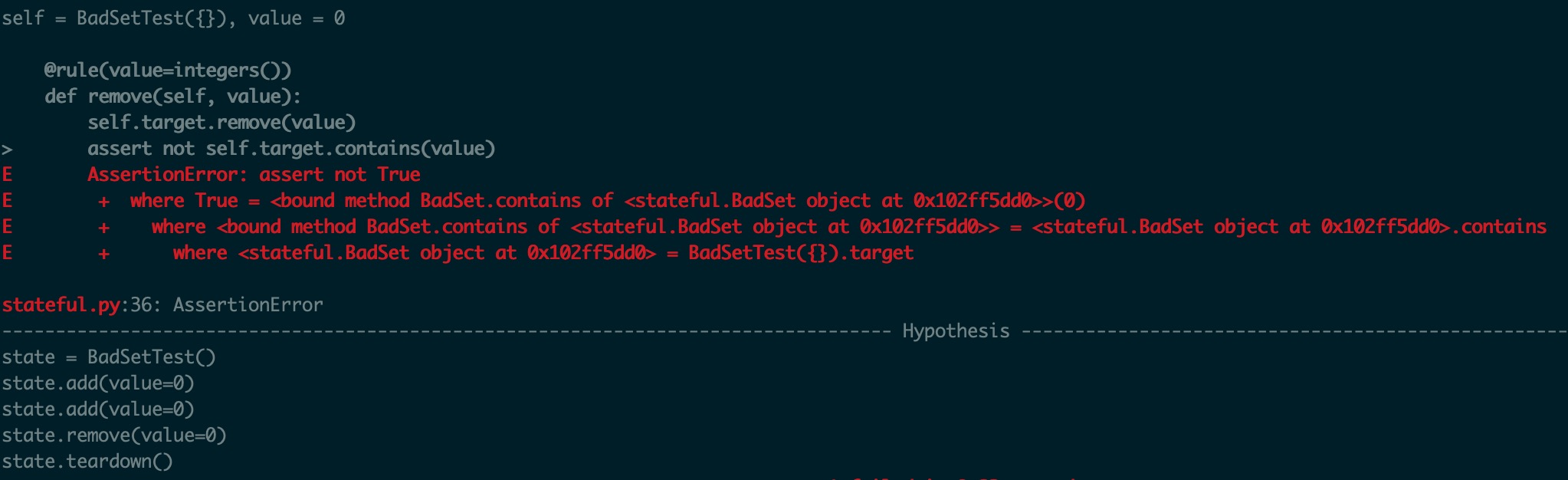
可以看到hypothesis最终在remove测试用例后出错,执行的顺序为:add(0), add(0), remove(0),这样就能发现,由于BadSet使用数组实现set,可以重复插入,导致移除后数据还会存在,从而就证明原始的BadSet有问题,需要进行修复。
总结
hypothesis是一个优秀的基于属性的测试库,可以帮助我们省去很多生成数据的麻烦,但是不保证所有的数据都会被测试到,因此一些特殊的边界数据我们如果需要保证一定会测试到,可以使用@example()额外添加。同时hypothesis提供的带状态的测试方式对于带状态的测试会特别方便,如果有这样的测试场景,不妨试用一下,可能会给你很多惊喜。如果希望了解hypothesis更多的信息,不妨参考下官方文档。