基本介绍
- docker 轻量的虚拟技术,镜像提供标准的运行环境供任务运行,任务在镜像之上运行。
- docker-compose docker容器集群编排应用,定义和运行多个docker应用。通过单个docker-compose文件可以启动多个docker应用
- kubernetes 依赖docker进行容器管理,属于docker容器集群管理系统,方便进行部署,升级,回滚,健康监控自动化,动态扩容缩容
核心概念
kubernetes 设计理念
核心思想在于预期状态(Desired State)
kubernetes 保证集群中容器一直处于预期状态始终处于预期状态下,当实际情况与预期状态不符合时,kubernetes就会进行动态调整,直到集群符合预期状态。用户可以通过kubectl调整集群的预期状态,调整预期后,k8s会动态调整,直到符合新的预期
kubernetes 框架
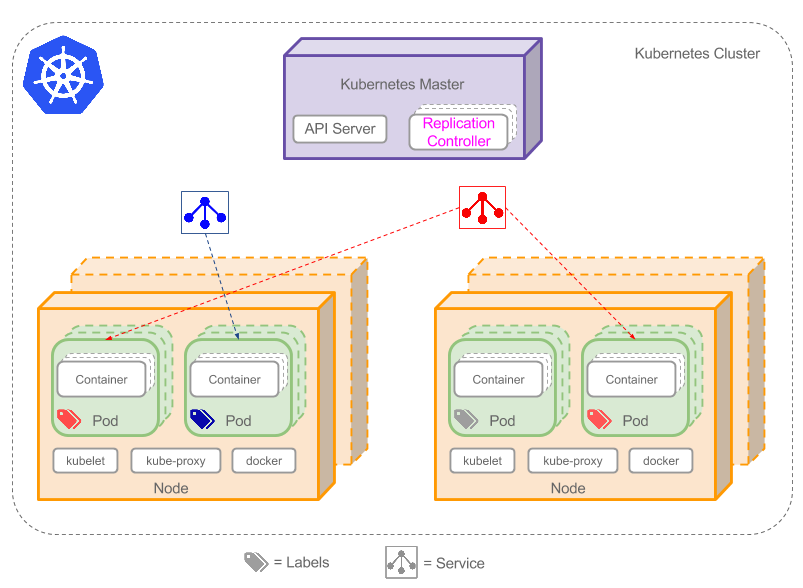
- Cluster 集群 计算,存储和网络资源的集合,k8s利用这些资源运行应用
- Master 用于调度与管理整合系统的主机,为了保证高可用,可以包含多个master节点
- Node 用于运行容器应用的主机,根据Master的要求管理容器的生命周期
- Pod 最小的调度单元,内部可以包含一个或多个container,pod内容的containter共享资源,。一般情况下采用one-container-per-pod模型
- Controller kubernetes一般使用controller来管理pod,controller中可能包含多个副本的pod,最常用的就是Deployment
- Service 每个Pod有自己的IP,而且可能动态变化,为了能正确访问,service提供一种访问pod的方式,为pod提供负载均衡。具体访问方式:service有自己固定的IP地址,service利用label选择特定的一组pod,kubernetes会维护service和pod之间的映射关系,需要访问pod时,只需访问service即可。
- label 使用键值对去选择特定的一组pod。可以使用label标记特定的一组pod,然后使用selector进行选择
具体实践
在具体的项目中实践了kubernetes,具体的产品的架构相对简单,采用的是flask + celery + beat + redis + mongo的结构,redis与mongo都是采用阿里云进行存储,因此真正需要使用kubernetes部署的只有web,celery与beat。由于部署的代码相对类似,仅以web的部署代码为例进行介绍:
apiVersion: extensions/v1beta1 # 当前配置格式版本
kind: Deployment # 当前控制器类型
metadata:
name: sms-web # 控制器名字
spec:
replicas: 6 # web服务使用6副本
revisionHistoryLimit: 5 # 上线版本历史数量,保存最新5次的版本,可以回滚到5次前的记录
strategy:
type: RollingUpdate # 代码上线方式,滚动升级,交替创建新副本,销毁老副本,保证始终可用
# rollingUpdate:
# maxSurge: 2 # 上线过程中,副本最多超过期望值的数量,sms-web最多会存在8个副本,不设置默认值为25%,向上取整
# maxUnavailable: 1 # 上线过程中,最多不可用副本的数量,sms-web最少会存在5个可用副本,不设置默认值为25%,向下取整
minReadySeconds: 10 # 新创建副本转换为ready持续的时间最小值
template:
metadata:
labels:
app: sms-web # 标签,可用于选中对应的deployment
spec:
containers:
- name: sms-web
image: private-image # 镜像数据,目前镜像采用私有仓库的镜像
command: ["sh", "-c", "exec gunicorn -w 4 -b 0.0.0.0:8004 wsgi:app -k eventlet"] # 启动镜像后执行的命令,启动web服务
env:
- name: ENV # 执行的环境变量
value: 'online'
workingDir: /code # 容器工作目录
volumeMounts:
- name: log-dir # volume挂载,将volume挂载在/var/log/sms目录下
mountPath: /var/log/sms
resources:
limits:
memory: 800Mi # 资源消耗限制,最多占用800M内存
cpu: "1"
requests:
cpu: "0.1" # 使用单个的cpu的10%,注意此时只是申请,不是真实占用,主要作为pod是否可以启动的参考
memory: 200Mi # 申请的最少的资源消耗,最少占用200M内存
terminationGracePeriodSeconds: 180 # 优雅关闭的时间间隔
imagePullSecrets:
- name: pull-secret # 拉取私有仓库镜像所需的秘钥
volumes:
- name: log-dir # 本地挂载空目录,避免与Node节点产生耦合
emptyDir: {}
滚动升级
对于web的配置采用RollingUpdate,即滚动升级的方式,保证线上可以不停机升级。实际上线时maxSurge和maxUnavaiable都采用了默认值25%,kubernetes会保证sms-web最多会存在8个副本,最少会存在5个副本。会采用增加新副本,减少老副本,再增加新副本,再减少老副本的方式来循环升级,保证系统的高可用
资源配置
对于web资源的配置采用limits和requests进行配置,limits指定pod可用的资源的上限,当pod需要的资源达到上限时,继续请求资源是不能成功的。requests指定所需的资源的下限,当系统可用的资源达不到下线时,pod是不能正常启动的
目录挂载
在web服务中,挂载了目录/var/log/sms,使用的name为log-dir,可以看到log-dir对应的volumes是emptyDir类型,表示对应于Node节点上的一个空目录。此挂载的目录与pod的生命周期是一致的,当pod被销毁时,挂载目录也会被销毁。因此挂载的内容是脆弱的,不能过度依赖此挂载目录。在实践中,采用此目录存储日志文件,同时进程会及时取走日志文件,同步至远端,这种用法是可行的。
私有仓库镜像
在具体的业务中,一般会将镜像保存至特定的私有仓库中,在私有仓库中拉取镜像时,需要秘钥进行拉取。具体操作参考官方文档
kind: Service
apiVersion: v1
metadata:
name: sms-web
spec:
type: NodePort # 设置service类型,NodePort类型的service可以通过NodeIp: NodePort进行访问
selector:
app: sms-web # 设置service对应的pod,本项目中对应的Deployment sms-web对应的pod
ports:
- protocol: TCP
port: 8004 # port 是 service 暴露给Cluster内部使用的端口,内部可以通过<clusterIp>:port 进行访问
targetPort: 8004 # pod上实际的端口,访问通过此端口进入容器进行处理
nodePort: 31090 # nodePort 是 k8s 提供给集群外部进行访问的接口,集群外部可以通过 <nodeIp>: nodePort 进行访问
service选择器
在实践中,需要访问pod时,一般都是使用service进行桥接,因为pod是脆弱,随时可能销毁,地址也可能随时会变化。而service则提供了一种稳定访问到pod的方法。实际业务中,一般采用选择器将service绑定到特定的pod上。
在前面的sms-web上,通过labels: app: sms-web指定了pod的标签,而在service中,则可以通过selector: app: sms-web 指定的相同键值对选中相应的pod,绑定好之后,后续需要访问pod时,只需要访问此service的地址即可
service访问端口
service类型一般使用ClusterIp和NodePort类型,其中ClusterIp是只能在Cluster内部进行访问的,而NodePort类型则可以在Cluster外部进行访问
本项目中的Service需要外部访问,因此指定的类型为NodePort,可以看到指定了三个端口地址,其中port 是Cluster内部访问的端口,在Cluster内部可以通过service_ip: port的方式进行访问。而nodePort端口,即上面指定的31090,是Cluster外部访问的端口,但是service_ip是一个Cluster内部的ip地址,那么Cluster外部通过什么地址来访问呢? 答案是node_ip: nodePort 地址,其中node_ip为cluster上的Node节点任意一个地址,因为对于service指定为NodePort类型后,每个Node都会为Service提供转发,当访问任意Node节点的nodePort端口时,事实上,请求都会被转发给service,然后被转发给pod
实践中的异常
本地mongodb无法连接
本地mongodb初始情况下连接失败,一直被拒绝,通过127.0.0.1的地址是可以正常连接的,但是通过本地ip/sms连接失败
mongo默认只允许本机访问,mac下的配置文件在/usr/local/etc/mongod.conf, 其中有一行bindIp: 127.0.0.1,只允许本机访问
如果想要支持其他ip,可以修改为[ip1, ip2, 127.0.0.1]的写法,如果想要全部放开,将bindIp修改为0.0.0.0,然后将mongodb重启即可 执行pkill mongod关闭mongodb, 然后再执行mongod -f /usr/local/etc/mongod.conf –fork 启动即可
本地redis无法连接
本地redis初始情况下连接失败
原因与mongodb类似,配置文件在/usr/local/etc/redis.conf,修改bindIp即可解决
测试环境部署时requirements.txt找不到
在dockerfile中根据路径添加requirements.txt文件,一直报错: no such file or directory
- dockerfile不支持绝对路径,只支持相对当前dockerfile文件的相对路径,按照绝对路径来写容易出现此错误
- 在项目中默认会生成.dockerignore文件,此文件默认状态下会忽略所有文件
本次是由于原因2,requirements.txt被忽略,因此始终找不到。在.dockerignore文件中添加 !code/sms/requirements.txt,将所需的文件不忽略即可
celery没有正常启动
在启动完所有的镜像后,发现celery似乎没有工作,启动失败
使用root启动celery时,如果不进行配置会报错
在配置celery的Deployment时,添加环境变量C_FORCE_ROOT=True,即可解决使用root启动celery的问题
k8s环境变量设置为True时出错
在撰写k8s配置文件时,为了保证celery可以正常启动,需要配置环境变量C_FORCE_ROOT=True,在k8s配置文件添加此环境变量时,运行出错
k8s配置不支持除字符串以外的其他类型数据,而且不会自动转换,因此配置环境变量时,变量值为数字,或者true, True等值时,会直接报错
将缓解变量C_FORCE_ROOT对应的值设置为’true’即可
部分Pod无法启动
利用kubectl apply 启动所需的pods后,原始希望能启动web的3个副本,celery的3个副本,beat的1个副本,但是实际web只有2个pod状态为Running, 而celery也只有2个pod状态为Running,beat的pod状态为Running,其他pod状态为Pending
利用kubectl describe pod xxx 查看pod的具体信息,在最后发现了相关的原因,错误信息为,0/1 nodes are available: 1 Insufficient cpu。领悟到web, celery, beat都设置了资源限制,其中request memory 设置为 200Mi, 而request cpu设置为 “0.2”,表示pod所需的最小的memory为200M,最小cpu为0.2,因此单台设备分配给5个pod后就分配完了,没办法启动更多的pod,从而导致这些pod一直处于Pending状态
- 增加cpu,可以通过增加Node节点数量从而增加cpu资源
- 减少任务的cpu需求,修改resources中requests需要的cpu资源,即pod所需的最少cpu资源 在实际情况中,根据任务的具体的情况进行分析,采用相应的策略,本次由于只是本地测试,为了进行测试,采用方法2,修改了requests需要的资源